结巴(jieba)分词的使用-Java实现
结巴分词Java版
结巴分词的使用比较方便,效果也不错,也无需连接网络即可使用。在项目中使用到了结巴分词,故在此做个小笔记。
本项目中所想实现的是如下的较精准模式。
支持三种分词模式:
1、较精确模式:试图将句子最较精确地切开,适合文本分析;
【我/ 来到/ 北京/ 清华大学】
2、全模式:把句子中所有的可以成词的词语都扫描出来, 速度较快,但是不能解决歧义;
【我/ 来到/ 北京/ 清华/ 清华大学/ 华大/ 大学】
3、搜索引擎模式:在较精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
【小明, 硕士, 毕业, 于, 中国, 科学, 学院, 科学院, 中国科学院, 计算, 计算所】
创建工程
工程目录:

conf:conf目录是添加词库的,希望组合的词或者不被拆分的词都可以添加在该目录下的文件中。
这里的词库可以使用搜狗词库和自定义词库。
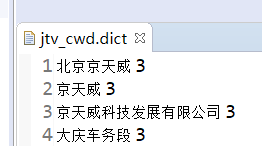
自定义词库的格式:
一个词占一行;每一行分三部分:词语、词频(可省略)、词性(可省略),用空格隔开,顺序不可颠倒。
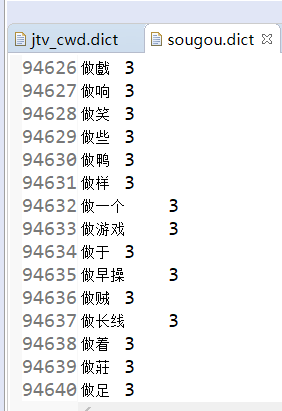
sougou.dict词库包:(共有94640个)
下载链接:sougou.dict
本人创建的是maven项目,需要导入jieba-analysis的jar包:
com.huaban
jieba-analysis
1.0.2
测试代码:
package com.test.Jieba;
import java.nio.file.Paths;
import org.junit.Test;
import com.huaban.analysis.jieba.JiebaSegmenter;
import com.huaban.analysis.jieba.WordDictionary;
import junit.framework.TestCase;
public class JiebaTest extends TestCase {
private JiebaSegmenter segmenter = new JiebaSegmenter();
String sentences = "北京京天威科技发展有限公司大庆车务段的装车数量";
/**
* 读取conf目录下所有的自定义词库**.dict文件。
*/
@Override
protected void setUp() throws Exception {
WordDictionary.getInstance().init(Paths.get("conf"));
}
@Test
public void testCutForSearch() {
System.out.println(segmenter.sentenceProcess(sentences));
}
}代码很简单,主要就是创建对象,加载配置文件,文本分词。
效果展示:
1、在不适用自定义词库的情况下的分词效果:
[北京, 京, 天威, 科技, 发展, 有限公司, 大庆, 车务段, 的, 装车, 数量]
2、在使用自定义词库的情况下的分词效果:
[北京, 京天威科技发展有限公司, 大庆车务段, 的, 装车数量]