基于LSTM分类文本情感分析
背景介绍
文本情感分析作为NLP的常见任务,具有很高的实际应用价值。本文将采用LSTM模型,训练一个能够识别文本postive, neutral, negative三种情感的分类器。
本文的目的是快速熟悉LSTM做情感分析任务,所以本文提到的只是一个baseline,并在最后分析了其优劣。对于真正的文本情感分析,在本文提到的模型之上,还可以做很多工作,以后有空的话,笔者可以再做优化。
理论介绍
RNN应用场景
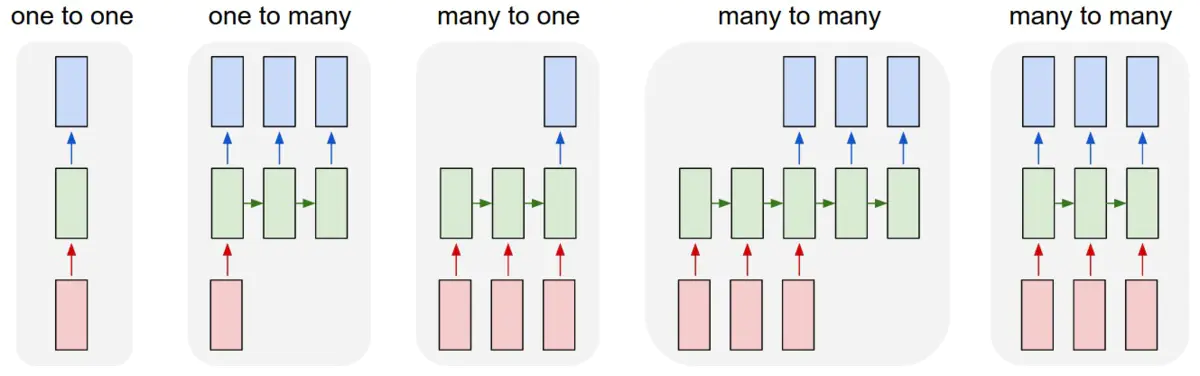
RNN相对于传统的神经网络,它允许我们对向量序列进行操作:输入序列、输出序列、或大部分的输入输出序列。如下图所示,每一个矩形是一个向量,箭头则表示函数(比如矩阵相乘)。输入向量用红色标出,输出向量用蓝色标出,绿色的矩形是RNN的状态(下面会详细介绍)。从做到右:(1)没有使用RNN的Vanilla模型,从固定大小的输入得到固定大小输出(比如图像分类)。(2)序列输出(比如图片字幕,输入一张图片输出一段文字序列)。(3)序列输入(比如情感分析,输入一段文字然后将它分类成积极或者消极情感)。(4)序列输入和序列输出(比如机器翻译:一个RNN读取一条英文语句然后将它以法语形式输出)。(5)同步序列输入输出(比如视频分类,对视频中每一帧打标签)。我们注意到在每一个案例中,都没有对序列长度进行预先特定约束,因为递归变换(绿色部分)是固定的,而且我们可以多次使用。
word2vec 算法
建模环节中最重要的一步是特征提取,在自然语言处理中也不例外。在自然语言处理中,最核心的一个问题是,如何把一个句子用数字的形式有效地表达出来?如果能够完成这一步,句子的分类就不成问题了。显然,一个最初等的思路是:给每个词语赋予唯一的编号1,2,3,4...,然后把句子看成是编号的集合,比如假设1,2,3,4分别代表“我”、“你”、“爱”、“恨”,那么“我爱你”就是[1, 3, 2],“我恨你”就是[1, 4, 2]。这种思路看起来有效,实际上非常有问题,比如一个稳定的模型会认为3跟4是很接近的,因此[1, 3, 2]和[1, 4, 2]应当给出接近的分类结果,但是按照我们的编号,3跟4所代表的词语意思完全相反,分类结果不可能相同。因此,这种编码方式不可能给出好的结果。
读者也许会想到,我将意思相近的词语的编号凑在一堆(给予相近的编号)不就行了?嗯,确实如果,如果有办法把相近的词语编号放在一起,那么确实会大大提高模型的准确率。可是问题来了,如果给出每个词语唯一的编号,并且将相近的词语编号设为相近,实际上是假设了语义的单一性,也就是说,语义仅仅是一维的。然而事实并非如此,语义应该是多维的。
比如我们谈到“家园”,有的人会想到近义词“家庭”,从“家庭”又会想到“亲人”,这些都是有相近意思的词语;另外,从“家园”,有的人会想到“地球”,从“地球”又会想到“火星”。换句话说,“亲人”、“火星”都可以看作是“家园”的二级近似,但是“亲人”跟“火星”本身就没有什么明显的联系了。此外,从语义上来讲,“大学”、“舒适”也可以看做是“家园”的二级近似,显然,如果仅通过一个唯一的编号,是很难把这些词语放到适合的位置的。

Word2Vec:高维来了
从上面的讨论可以知道,很多词语的意思是各个方向发散开的,而不是单纯的一个方向,因此唯一的编号不是特别理想。那么,多个编号如何?换句话说,将词语对应一个多维向量?不错,这正是非常正确的思路。
为什么多维向量可行?首先,多维向量解决了词语的多方向发散问题,仅仅是二维向量就可以360度全方位旋转了,何况是更高维呢(实际应用中一般是几百维)。其次,还有一个比较实际的问题,就是多维向量允许我们用变化较小的数字来表征词语。怎么说?我们知道,就中文而言,词语的数量就多达数十万,如果给每个词语唯一的编号,那么编号就是从1到几十万变化,变化幅度如此之大,模型的稳定性是很难保证的。如果是高维向量,比如说20维,那么仅需要0和1就可以表达2^20=1048576220=1048576(100万)个词语了。变化较小则能够保证模型的稳定性。
扯了这么多,还没有真正谈到点子上。现在思路是有了,问题是,如何把这些词语放到正确的高维向量中?而且重点是,要在没有语言背景的情况下做到这件事情?(换句话说,如果我想处理英语语言任务,并不需要先学好英语,而是只需要大量收集英语文章,这该多么方便呀!)在这里我们不可能也不必要进行更多的原理上的展开,而是要介绍:而基于这个思路,有一个Google开源的著名的工具——Word2Vec。
简单来说,Word2Vec就是完成了上面所说的我们想要做的事情——用高维向量(词向量,Word Embedding)表示词语,并把相近意思的词语放在相近的位置,而且用的是实数向量(不局限于整数)。我们只需要有大量的某语言的语料,就可以用它来训练模型,获得词向量。词向量好处前面已经提到过一些,或者说,它就是问了解决前面所提到的问题而产生的。另外的一些好处是:词向量可以方便做聚类,用欧氏距离或余弦相似度都可以找出两个具有相近意思的词语。这就相当于解决了“一义多词”的问题(遗憾的是,似乎没什么好思路可以解决一词多义的问题。)
关于Word2Vec的数学原理,读者可以参考这系列文章。而Word2Vec的实现,Google官方提供了C语言的源代码,读者可以自行编译。而Python的Gensim库中也提供现成的Word2Vec作为子库(事实上,这个版本貌似比官方的版本更加强大)。
句向量
接下来要解决的问题是:我们已经分好词,并且已经将词语转换为高维向量,那么句子就对应着词向量的集合,也就是矩阵,类似于图像处理,图像数字化后也对应一个像素矩阵;可是模型的输入一般只接受一维的特征,那怎么办呢?一个比较简单的想法是将矩阵展平,也就是将词向量一个接一个,组成一个更长的向量。这个思路是可以,但是这样就会使得我们的输入维度高达几千维甚至几万维,事实上是难以实现的。(如果说几万维对于今天的计算机来说不是问题的话,那么对于1000x1000的图像,就是高达100万维了!)
在自然语言处理中,通常用到的方法是递归神经网络或循环神经网络(都叫RNNs)。它们的作用跟卷积神经网络是一样的,将矩阵形式的输入编码为较低维度的一维向量,而保留大多数有用信息。
