Python文件输入和输出总结
一、文件的路径
(1)创建文件路径;使用os模块下的path.join(),实现路径的链接
#文件的路径
import os
filename=['accounts.txt', 'details.csv', 'invite.docx']
for i in filename:
print(i)
print(os.path.join('C:\\demo\\exercise',i))
输出结果为:
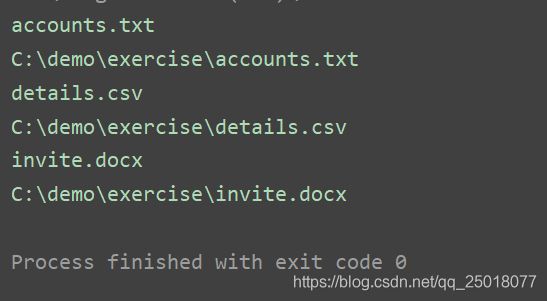
(2)获取当前文件路径
获取当前文件路径可以使用 os.getcwd() 取得当前工作路径的字符串,还可以利用 os.chdir() 改变它。例如,在交互式环境中输入以下代码:
os.getcwd() #获取当前文件路径
os.chdir('C:\\Windows\\System64') #修改当前文件路径
os.getcwd()注意:在使用os.chdir()函数修改当前路径时,修改后的路径必须是已存在的文件路径,否则将出现错误。
(3)绝对文件路径和相对文件路径
明确一个文件所在的路径,有 2 种表示方式,分别是:
- 绝对路径:总是从根文件夹开始,Window 系统中以盘符(C:、D:)作为根文件夹,而 OS X 或者 Linux 系统中以 / 作为根文件夹。
- 相对路径:指的是文件相对于当前工作目录所在的位置。例如,当前工作目录为 "C:\Windows\System32",若文件 demo.txt 就位于这个 System32 文件夹下,则 demo.txt 的相对路径表示为 ".\demo.txt"(其中 .\ 就表示当前所在目录)。
在使用相对路径表示某文件所在的位置时,除了经常使用 .\ 表示当前所在目录之外,还会用到 ..\ 表示当前所在目录的父目录Python os.path 模块提供了一些函数,可以实现绝对路径和相对路径之间的转换,以及检查给定的路径是否为绝对路径,比如说:
1、调用 os.path.abspath(path) 将返回 path 参数的绝对路径的字符串,这是将相对路径转换为绝对路径的简便方法。
2、调用 os.path.isabs(path),如果参数是一个绝对路径,就返回 True,如果参数是一个相对路径,就返回 False。
3、调用 os.path.relpath(path, start) 将返回从 start 路径到 path 的相对路径的字符串。如果没有提供 start,就使用当前工作目录作为开始路径。
4、调用 os.path.dirname(path) 将返回一个字符串,它包含 path 参数中最后一个斜杠之前的所有内容;调用 os.path.basename(path) 将返回一个字符串,它包含 path 参数中最后一个斜杠之后的所有内容。
5、调用 os.path.split() 获得一个路径的目录名称和基本名称;
6、如果 path 参数所指的文件或文件夹存在,调用 os.path.exists(path) 将返回 True,否则返回 False。
7、如果 path 参数存在,并且是一个文件,调用 os.path.isfile(path) 将返回 True,否则返回 False。
8、如果 path 参数存在,并且是一个文件夹,调用 os.path.isdir(path) 将返回 True,否则返回 False。
二、文件的基本操作
常见的文件操作包括创建、删除、修改权限、读取、写入等操作,可大致分为以下 2 类:
1、删除、修改权限:作用于文件本身,属于系统级操作。
2、写入、读取:是文件最常用的操作,作用于文件的内容,属于应用级操作。
文件的应用级操作可以分为以下 3 步,每一步都需要借助对应的函数实现:
- 打开文件:使用 open() 函数,该函数会返回一个文件对象;
- 对已打开文件做读/写操作:读取文件内容可使用 read()、readline() 以及 readlines() 函数;向文件中写入内容,可以使用 write() 函数。
- 关闭文件:完成对文件的读/写操作之后,最后需要关闭文件,可以使用 close() 函数。Python 垃圾回收机制无法自动回收打开文件所占用的资源。
一个文件,必须在打开之后才能对其进行操作,并且在操作结束之后,还应该将其关闭,这 3 步的顺序不能打乱。
file = open(file_name [, mode='r' [ , buffering=-1 [ , encoding = None ]]]
#此格式中,用 [] 括起来的部分为可选参数,即可以使用也可以省略。其中,各个参数所代表的含义如下:
# 1.file:表示要创建的文件对象。
# 2.file_name:要创建或打开文件的文件名称,该名称要用引号(单引号或双引号都可以)括起来。需要注意的是,如果要打开的文件和当前执行的代码文件位于同一目录,则直接写文件名即可;否则,此参数需要指定打开文件所在的完整路径。
# 3.mode:可选参数,用于指定文件的打开模式。如果不写,则默认以只读(r)模式打开文件。
# 4.buffing:可选参数,用于指定对文件做读写操作时,是否使用缓冲区。
# 5.encoding:手动设定打开文件时所使用的编码格式,不同平台的 ecoding 参数值也不同,以 Windows 为
例,其默认为 cp936(实际上就是 GBK 编码)。
#通常情况下在使用 open() 函数时打开缓冲区,即不需要修改 buffing 参数的值。
#@ 如果 buffing 参数的值为 0(或者 False),则表示在打开指定文件时不使用缓冲区;
#@ 如果 buffing 参数值为大于 1 的整数,该整数用于指定缓冲区的大小(单位是字节);
#@ 如果 buffing 参数的值为负数,则代表使用默认的缓冲区大小。例子:
#创建一个文件,名称为result.txt,追加方式,默认条件下缓存
my_file=open('result.txt','r+',buffering=-1,encoding=None)
print(my_file.name) #输出文件名
print(my_file.mode) #输出文件的打开方式
print(my_file.encoding) #输出文件的编码方式
print(my_file.closed) #判断文件是否已经关闭了
#读取文件
print("读取文件操作:")
print("(1)---read()函数使用:")
print(my_file.read(6)) #读取文件中的6个字符
print(my_file.read()) #读取文件中的所有字符
print(my_file.read(120)) #显然文件中字符数目小于120 ,在这种情形下将会读取文件中的所有字符
#readline()函数在读取文件中一行内容,其具体操作语法和read()函数一样
#会读取最后的换行符“\n”,再加上 print() 函数输出内容时默认会换行,所以输出结果中会多出了一个空行
print("(2)---readline()函数使用:")
print(my_file.readline(6))
#readlines() 函数用于读取文件中的所有行,它和调用不指定 size 参数的 read() 函数类似,
# 只不过该函数返回是一个字符串列表,其中每个元素为文件中的一行内容。
print("(3)---readlines()函数使用:")
print(my_file.readlines())

注意:由运行结果可以发现,read()、readline()、readlines()三个函数在读取函数时尽量使用一个,一个显著的特点是,当前读取完后的文件,下次就不再参与读取,因此尽量选取一种读取函数进行读取操作。
#文件的输出
My_file=open('result2.txt','w+')
My_file.write("Hello world,this is Python! Welcome")
My_file.close()
#1.写入文件完成后,一定要调用 close() 函数将打开的文件关闭,否则写入的内容不会保存到文件中。
#2.采用不同的文件打开模式,会直接影响 write() 函数向文件中写入数据的效果。
#3.对于以二进制格式打开的文件,可以不使用缓冲区,写入的数据会直接进入磁盘文件;
#4.但对于以文本格式打开的文件,必须使用缓冲区,否则 Python 解释器会 ValueError 错误。
#5.如果向文件写入数据后,不想马上关闭文件,也可以调用文件对象提供的 flush() 函数,
# 它可以实现将缓冲区的数据写入文件中。例如
## $注意,写入函数只有 write() 和 writelines() 函数,而没有名为 writeline 的函数。
## 使用 writelines() 函数向文件中写入多行数据时,不会自动给各行添加换行符