Glide都在用的LruCache,你学会了吗?

什么是LRU?
在了解我们的LRUCache之前自然是需要知道什么是LRU了。
先来一段百度百科的“科学”解释:LRU是Least Recently Used的缩写,即最近最少使用,是一种常用的页面置换算法,选择最近最久未使用的页面予以淘汰。该算法赋予每个页面一个访问字段,用来记录一个页面自上次被访问以来所经历的时间 t,当须淘汰一个页面时,选择现有页面中其 t 值最大的,即最近最少使用的页面予以淘汰。
一番百度猛如虎的操作之后,让我们来图解一下LRU好了。
LRU的替换算法在内存已满时分为以下两种情况:
(1)缓存内部不存在时,如何进行替换操作。
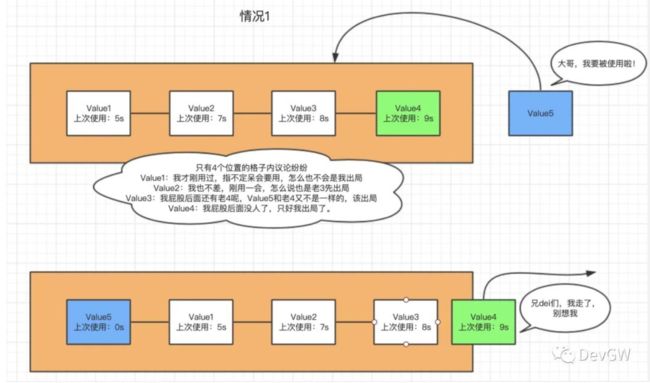
(2)缓存内部存在时,如何进行替换操作?

使用方法及结果
在项目中直接导入Glide的库,调用内部的LruCache来看看效果。
LruCache lruCache = new LruCache<String, Integer>(2);
lruCache.put("1", 1);
lruCache.put("2", 2);
lruCache.put("1", 1);
lruCache.put("3", 3);
System.out.println(lruCache.get("1"));
System.out.println(lruCache.get("2"));
System.out.println(lruCache.get("3"));
简要说明代码内容,创建一个空间为2的存储空间(这里先不透漏内部结构),用put()方法对数据进行存储,再通过get()对每个数据进行一次获取操作,然后我们再来看看结果。

我的天!!2没了?这是怎么一回事??想来认真看过上面图解的读者们已经心中知道答案了,但是呢我们还是要进入Glide的库中去看看它是如何去进行实现的了。
LruCache源码导读
先看看LruCache的变量家庭里有哪些小家伙把。
public class LruCache<T, Y> {
// 容量为100的双向链表
private final Map<T, Y> cache = new LinkedHashMap<>(100, 0.75f, true);
private final long initialMaxSize; // 初始化最大容量
private long maxSize; // 最大容量
private long currentSize; // 已存在容量
}
同样对于LruCache来说不也和HashMap一样只有三步骤要走嘛,那我就从这三个步骤入手探索一下LruCache好了,但是我们要带上一个问题出发,initialMaxSize的作用是什么?
new LruCache(size)
public LruCache(long size) {
this.initialMaxSize = size;
this.maxSize = size;
}
到这里想来读者都已经知道套路了,也就初始化了初始化最大容量和最大容量,那就直接下一步。
put(key, value)
public synchronized Y put(@NonNull T key, @Nullable Y item) {
// 返回值就是一个1
final int itemSize = getSize(item);
// 如果1大于等于最大值就无操作
// 也就说明整个初始化的时候并不能将size设置成1
if (itemSize >= maxSize) {
//用于重写的保留方法
onItemEvicted(key, item);
return null;
}
// 对当前存在数据容量加一
if (item != null) {
currentSize += itemSize;
}
@Nullable final Y old = cache.put(key, item);
if (old != null) {
currentSize -= getSize(old);
if (!old.equals(item)) {
onItemEvicted(key, old);
}
}
evict(); // 1 -->
return old;
}
// 由注释1直接调用的方法
private void evict() {
trimToSize(maxSize); // 2 -->
}
// 由注释2直接调用的方法
protected synchronized void trimToSize(long size) {
Map.Entry<T, Y> last;
Iterator<Map.Entry<T, Y>> cacheIterator;
// 说明当前的容量大于了最大容量
// 需要对最后的数据进行一个清理
while (currentSize > size) {
cacheIterator = cache.entrySet().iterator();
last = cacheIterator.next();
final Y toRemove = last.getValue();
currentSize -= getSize(toRemove);
final T key = last.getKey();
cacheIterator.remove();
onItemEvicted(key, toRemove);
}
}
这是一个带锁机制的方法,通过对当前容量和最大容量的判断,来抉择是否需要把我们的数据进行一个删除。但是问题依旧存在,initialMaxSize的作用是什么?,我们能够知道的是maxSize是一个用于控制容量大小的值。
get()
public synchronized Y get(@NonNull T key) {
return cache.get(key);
}
那这就是调用了LinkedHashMap中的数据,但是终究还是没有说出initialMaxSize的作用。
关于initialMaxSize
这里就不买关子了,因为其实就我的视角来看这个initialMaxSize确实是没啥用处的。哈哈哈哈哈!!!但是,又一个地方用到了它。
public synchronized void setSizeMultiplier(float multiplier) {
if (multiplier < 0) {
throw new IllegalArgumentException("Multiplier must be >= 0");
}
maxSize = Math.round(initialMaxSize * multiplier);
evict();
}
也就是用于调控我们的最大容量大小,但是我觉得还是没啥用,可是是我太菜了吧,这个方法没有其他调用它的方法,是一个我们直接在使用过程中使用的,可能和数据多次使用的一个保存之类的问题相关联把,场景的话也就类似Glide的图片缓存加载把。也希望知道的读者能给我一个解答。
LinkedHashMap
因为操作方式和HashMap一致就不再复述,就看看他的节点长相。
static class LinkedHashMapEntry<K,V> extends HashMap.Node<K,V> {
// 存在前后节点,也就是我们所说的双向链表
LinkedHashMapEntry<K,V> before, after;
LinkedHashMapEntry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
但是到这里,我又出现了一个问题,为什么我没有看到整个数据的移动?也就是最近使用的数据应该调换到最后开始的位置,他到底实在哪里进行处理的呢?做一个猜想好了,既然是使用了put()才会造成双向链表中数据的变换,那我们就应该是需要进入对LinkedHashMap.put()方法中进行查询。
当然有兴趣探索的读者们,我需要提一个醒,就是这次的调用不可以直接进行对
put()进行查询,那样只会调用到一个接口函数,或者是抽象类函数,最适合的方法还是使用我们的断点来进行探索查询。
但是经过一段努力后,不断深度调用探索发现这样的问题,他最后会调用到这样的问题。
// Callbacks to allow LinkedHashMap post-actions
void afterNodeAccess(Node<K,V> p) {
} // 把数据移动到最后一位
void afterNodeInsertion(boolean evict) {
}
void afterNodeRemoval(Node<K,V> p) {
}
这是之前我们在了解HashMap是并没有发现几个方法,上面也明确写着为LinkedHashMap保留。哇哦!!那我们的操作肯定实在这些里面了。
// --> HashMap源码第656行附近调用到下方方法
// 在putVal()方法内部存在这个出现
afterNodeAccess(e);
// --> LinkedHashMap对其具体实现
// 就是将当前数据直接推到最后一个位置
// 也就是成为了最近刚使用过的数据
void afterNodeAccess(Node<K,V> e) {
// move node to last
LinkedHashMapEntry<K,V> last;
if (accessOrder && (last = tail) != e) {
LinkedHashMapEntry<K,V> p =
(LinkedHashMapEntry<K,V>)e, b = p.before, a = p.after;
p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a != null)
a.before = b;
else
last = b;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
tail = p;
++modCount;
}
}
好了,自此我们也就清楚了整个链表的变换过程了。
实战:手撸LruCache
这是一个非常紧张刺激的环节了,撸代码前,我们来找找思路好了。
(1)存储容器用什么? 因为LinkedHashMap的思路太过冗长,我们用数组来重新完成整个代码的构建
(2)关键调用方法put()、get()以及put()涉及的已存在变量移位。
哇哦!看来要做的事情也并没有这么多,那我们就先来看看第一次构造出来的框架好了。
public class LruCache {
private Object objects[];
private int maxSize;
private int currentSize;
public LruCache(int size){
objects = new Object[size];
maxSize = size;
}
/**
* 插入item
* @param item
*/
public void put(Object item){
}
/**
* 获取item
* @param item
*/
public Object get(Object item){
return null;
}
/**
* 根据下标对应,将后续数组移位
* @param index
*/
public void move(int index){
}
}
因为只要是数组变换就存在移位,所以移位操作是必不可少的。那我们现在的工作也就是把数据填好了,对应的移位是怎么样的操作的思路了。
public class LruCache {
public Object objects[];
private int maxSize;
public int currentSize;
public LruCache(int size) {
objects = new Object[size];
maxSize = size;
}
/**
* 插入item
*
* @param item
*/
public void put(Object item) {
// 容量未满时分成两种情况
// 1。 容器内存在
// 2。 容器内不存在
int index = search(item);
if (index == -1) {
if (currentSize < maxSize) {
//容器未满,直接插入
objects[currentSize] = item;
currentSize++;
} else {
// 容器已满,删去头部插入
move(0);
objects[currentSize - 1] = item;
}
}else {
move(index);
}
}
/**
* 获取item
*
* @param item
*/
public Object get(Object item) {
int index = search(item);
return index == -1 ? null : objects[index];
}
/**
* 根据下标对应,将后续数组移位
*
* @param index
*/
public void move(int index) {
Object temp = objects[index];
// 将后续数组移位
for (int i = index; i < currentSize - 1; i++) {
objects[i] = objects[i + 1];
}
objects[currentSize - 1] = temp;
}
/**
* 搜寻数组中的数组
* 存在则返回下标
* 不存在则返回 -1
* @param item
* @return
*/
private int search(Object item) {
for (int i = 0; i < currentSize; i++) {
if (item.equals(objects[i])) return i;
}
return -1;
}
因为已经真的写的比较详细了,也没什么难度的撸了我的20分钟,希望读者们能够快入入门,下面给出我的一份测试样例,结束这个话题。

总结
想来我们都知道在操作系统中有这样的问题需要思考,具体题型的话就是缺页中断。
用一个例题来彻底了解LruCache的算法。
例: 存入内存的数据序列为:(1,2,1,3,2),内存容量为2。

LruCache 主要用于缓存的处理,这里的缓存主要指的是内存缓存和磁盘缓存。