Pytorch实现CNN经典网络框架(LeNet、AlexNet、VGGNet、GoogLeNet、ResNet)
卷积神经网络可谓是现在深度学习领域中大红大紫的网络框架,尤其在计算机视觉领域更是一枝独秀。CNN从90年代的LeNet开始,21世纪初沉寂了10年,直到12年AlexNet开始又再焕发第二春,从ZF Net到VGG,GoogLeNet再到ResNet和最近的DenseNet,网络越来越深,架构越来越复杂,解决反向传播时梯度消失的方法也越来越巧妙。下面介绍几种网络的结构框架和代码实现。
一、LeNet
1、介绍
LeNet是卷积神经网络的祖师爷LeCun在1998年提出,用于解决手写数字识别的视觉任务。 一共有7层,其中2层卷积和2层化层交替出现,最后输出3层全连接层得到整体的结果。没有添加激活层。
随后CNN的最基本的架构就定下来了:卷积层、池化层、全连接层。如今各大深度学习框架中所使用的LeNet都是简化改进过的LeNet-5(-5表示具有5个层),和原始的LeNet有些许不同,比如把激活函数改为了现在很常用的ReLu。
LeNet-5跟现有的conv->pool->ReLU的套路不同,它使用的方式是conv1->pool->conv2->pool2再接全连接层,但是不变的是,卷积层后紧接池化层的模式。
2、网络结构

3、代码实现
import torch.nn as nn
class Lenet(nn.Module):
def __init__(self):
super(Lenet,self).__init__()
layer1 = nn.Sequential()
layer1.add_module('conv1',nn.Conv2d(1,6,3,padding=1))
layer1.add_module('pool1',nn.MaxPool2d(2,2))
self.layer1 = layer1
layer2 = nn.Sequential()
layer2.add_module('conv2',nn.Conv2d(6,16,5))
layer2.add_module('pool2',nn.MaxPool2d(2,2))
self.layer2 = layer2
layer3 = nn.Sequential()
layer3.add_module('fc1',nn.Linear(400,120))
layer3.add_module('fc2',nn.Linear(120,84))
layer3.add_module('fc3',nn.Linear(84,10))
self.layer3 = layer3
def forward(self,x):
x = self.layer1(x)
x = self.layer2(x)
x = x.view(x.size(0),-1)
x = self.layer3(x)
return x
二、AlexNet
1、介绍
2012年AlexNet框架在ImageNet竞赛上面大放异彩的,它以领先第二名10%的准确度夺得冠军。掀起了卷积神经网络在图像领域的热潮。AlexNet相比于LeNet层数更深,第一次引入了激活层ReLU,并且在全连接层加入了Dropout防止过拟合。
2、网络结构
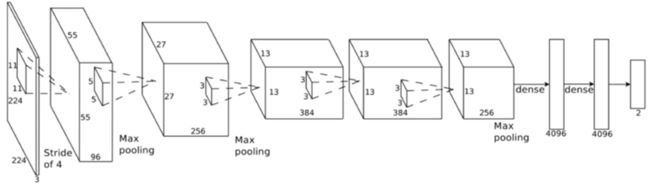
3、代码实现
class AlexNet(nn.Module):
def __init__(self,num_classes):
super(AlexNet,self).__init__()
#特征抽取
self.features = nn.Sequential(
nn.Conv2d(2,64,kernel_size=11,stride=4,padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3,stride=2),
nn.Conv2d(64,192,kernel_size=3,padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3,stride=2),
nn.Conv2d(192,384,kernel_size=3,padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(384,256,kernel_size=3,padding=1),
nn.ReLU(inplace=True),
nn.Con2d(256,256,kernel_size-3,padding=1),
nn.ReLu(inplace=True),
nn.MaxPool2d(kernel_size=3,stride=2))
self.classifier = nn.Sequential(
nn.Dropout(),
nn.Linear(256,6,6,4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096,4096),
nn.ReLu(inplace=True),
nn.Linear(4096,num_classes))
def forward(self,x):
x = self.features(x)
x = view(x.size(0),256*6*6)
x = self.classifier(x)
return x
三、VGGNet
1、介绍
VGGNe是ImageNet 2014年的亚军,它使用了更小的滤波器,同时使用的更深的网络结构。VGG只是对网络层进行不断的堆叠,并没有进行太多的创新,但增加深度确实可以一定程度改善模型效果。
AlexNet只有8层网络,而VGGNet有16-19层网络。AlexNet使用1111的大滤波器,而VGGNet使用33的卷积滤波器和2*2的大池化层。AlexNet和VGGNet对比图:

2、网络结构 VGG-16
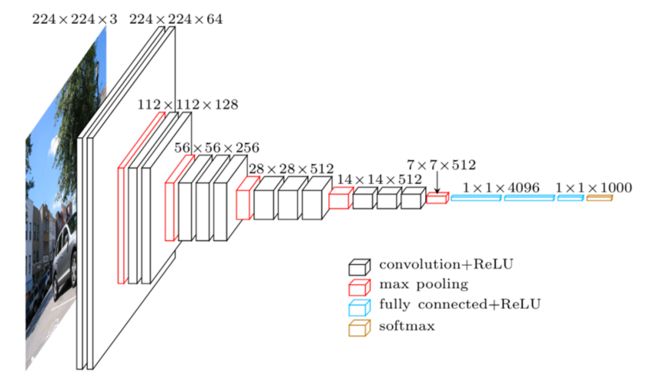
3、代码实现
class VGG(nn.Module):
def __init__(self,num_classes):
super(VGG,self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3,64,kernel_size=3,padding=1),
nn.ReLU(True),
nn.Conv2d(64,64,kernel_size=3,padding=1),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2,stride=2),
nn.Conv2d(64,128,kernel_size=3,padding=1),
nn.ReLU(True),
nn.Conv2d(128,128,kernel_size=3,padding=1),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2,stride=2),
nn.Conv2d(128,256,kernel_size=3,padding=1),
nn.ReLU(True),
nn.Conv2d(256,256,kernel_size=3,padding=1),
nn.ReLU(True),
nn.Conv2d(256,256,kernel_size=3,padding=1),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2,stride=2),
nn.Conv2d(256,512,kernel_size=3,padding=1),
nn.ReLU(True),
nn.Conv2d(512,512,kernel_size=3,padding=1),
nn.ReLU(True),
nn.Conv2d(512,512,kernel_size=3,padding=1),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2,stride=2),
nn.Conv2d(512,512,kernel_size=3,padding=1),
nn.ReLU(True),
nn.Conv2d(512,512,kernel_size=3,padding=1),
nn.ReLU(True),
nn.Conv2d(512,512,kernel_size=3,padding=1),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2,stride=2))
self.classifier = nn.Sequential(
nn.Linear(512*7*7,4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096,4096),
nn.ReLu(True),
nn.Dropout(),
nn.Linear(4096,num_classes))
self._initialize_weights()
def forward(self,x):
x = self.features(x)
x = x.view(x.size(0),-1)
x = self.classifier(x)
四、GoogLeNet
1、介绍
GoogLeNet 也叫InceptionNet,是在 2014 年被提出的。GoogLeNet 采取了比 VGGNet 更深的网络结构, 一共有 22 层,但是它的参数却比 A1exNet少了12倍。同时有很高的计算效率 ,因为它采用了一种很有效的Inception模块,而且它也没有全连接层,是 2014 年比赛的冠军。
2、网络结构
- 简单版Inception模块:
该结构将CNN中常用的卷积(1x1,3x3,5x5)、池化操作(3x3)堆叠在一起(卷积、池化后的尺寸相同,将通道相加),一方面增加了网络的宽度,另一方面也增加了网络对尺度的适应性。
网络卷积层中的网络能够提取输入的每一个细节信息,同时5x5的滤波器也能够覆盖大部分接受层的的输入。还可以进行一个池化操作,以减少空间大小,降低过度拟合。在这些层之上,在每一个卷积层后都要做一个ReLU操作,以增加网络的非线性特征。然而这个Inception原始版本,所有的卷积核都在上一层的所有输出上来做,而那个5x5的卷积核所需的计算量就太大了,造成了特征图的厚度很大
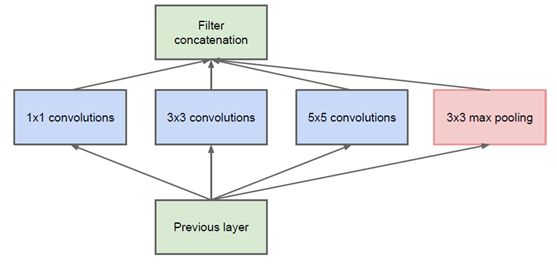
- 优化版Inception模型:为了避免上述情况,在3x3前、5x5前、max pooling后分别加上了1x1的卷积核,以起到了降低特征图厚度的作用,这也就形成了Inception v1的网络结构,如下图所示:

3、代码实现
整个GoogLeNet都是由这些Inception模块组成的。首先定义一个最基础的卷积模块、然后根据这个模块定义了1x1 ,3x3和5x5的模块和一个池化层,最后使用 torch.cat()将它们按深度拼接起来,得到输出结果。
class BasicConv2d(nn.Module):
def __init__(self,in_channels,out_channels,**kwargs):
super(BasicConv2d,self).__init__()
self.conv = nn.Conv2d(in_channels,out_channels,bias=False,**kwargs)
self.bn = nn.BatchNorm2d(out_channels,eps=0.001)
def forward(self,x):
x = self.conv(x)
x = self.bn(x)
return F.relu(x,inplace=True)
class Inception(nn.Module):
def __init__(self,in_channels,pool_features):
super(Inception,self).__init__()
self.branch1x1 = BasicConv2d(in_channels,64,kernel_size=1)
self.branch5x5_1 = BasicConv2d(in_channels,48,kernel_size=1)
self.branch5x5_2 = BasicConv2d(48,64,kernel_size=5,padding=2)
self.branch3x3dbl_1 = BasicConv2d(in_channels,64,kernel_size=1)
self.branch3x3dbl_2 = BasicConv2d(64,96,kernel_size=3,padding=1)
self.branch3x3dbl_3 = BasicConv2d(96,96,kernel_size=3,padding=1)
self.branch_pool = BasicConv2d(in_channels,pool_features,kernel_size=1)
def forward(self,x):
branch1x1 = self.branch1x1(x)
branch5x5 = self.branch5x5_1(x)
branch5x5 = self.branch5x5_2(branch5x5)
branch3x3dbl = self.branch3x3dbl_1(x)
branch3x3dbl = self.branch3x3dbl_2(branch3x3dbl)
branch3x3dbl = self.branch3x3dbl_3(branch3x3dbl)
branch_pool = F.avg_pool2d(x,kernel_size=3,stride=1,padding=1)
branch_pool = self.branch_pool(branch_pool)
outputs = [branch1x1,branch5x5,branch3x3dbl,branch_pool]
return torch.cat(outputs,1)
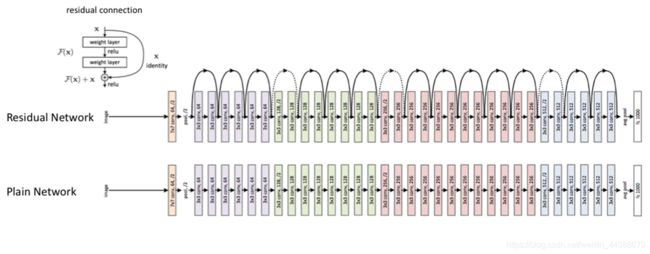
五、ResNet
1、介绍
ResNet是2015年ImageNet竞赛的冠军。由微软研究院提出,不再是简单的堆积层数,通过残差模块能够成功地训练高达152层深的神经网络。ResNet 最初的设计灵感来自这个问题:
- 随着网络深度增加,网络的准确度应该同步增加,当然要注意过拟合问题。但是网络深度增加的一个问题在于这些增加的层是参数更新的信号,因为梯度是从后向前传播的,增加网络深度后,比较靠前的层梯度会很小。这意味着这些层基本上学习停滞了,这就是梯度消失问题。
- 深度网络的第二个问题在于训练,当网络更深时意味着参数空间更大,优化问题变得更难,因此简单地去增加网络深度反而出现更高的训练误差。在不断加深度神经网络的时候,会出现一个Degradation,即准确率会先上开然后达到饱和,再持续增加深度则会导致模型准确率下降。比如下图,一个56层的网络的性能却不如20层的性能好,这不是因为过拟合(训练集训练误差依然很高),这就是退化问题。残差网络ResNet设计一种残差模块让我们可以训练更深的网络。

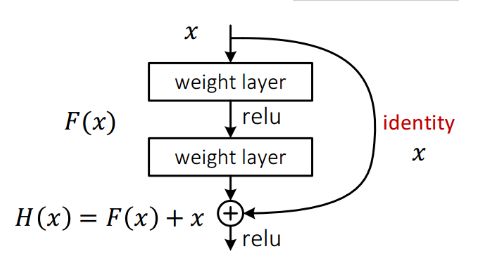
这里详细分析一下残差单元来理解ResNet的精髓。
从下图可以看出,数据经过了两条路线,一条是常规路线,另一条则是捷(shortcut),直接实现单位映射的直接连接的路线,这有点类似与电路中的“短路”。通过实验,这种带有shortcut的结构确实可以很好地应对退化问题。我们把网络中的一个模块的输入和输出关系看作是y=H(x),那么直接通过梯度方法求H(x)就会遇到上面提到的退化问题,如果使用了这种带shortcut的结构,那么可变参数部分的优化目标就不再是H(x),若用F(x)来代表需要优化的部分的话,则H(x)=F(x)+x,也就是F(x)=H(x)-x。因为在单位映射的假设中y=x就相当于观测值,所以F(x)就对应着残差,因而叫残差网络。为啥要这样做,因为作者认为学习残差F(X)比直接学习H(X)简单!设想下,现在根据我们只需要去学习输入和输出的差值就可以了,绝对量变为相对量(H(x)-x 就是输出相对于输入变化了多少),优化起来简单很多。
考虑到x的维度与F(X)维度可能不匹配情况,需进行维度匹配。这里论文中采用两种方法解决这一问题(其实是三种,但通过实验发现第三种方法会使performance急剧下降,故不采用):
- zero_padding:对恒等层进行0填充的方式将维度补充完整。这种方法不会增加额外的参数
- projection:在恒等层采用1x1的卷积核来增加维度。这种方法会增加额外的参数
2、网络结构
下图展示了两种形态的残差模块,左图是常规残差模块,有两个3×3卷积核卷积核组成,但是随着网络进一步加深,这种残差结构在实践中并不是十分有效。针对这问题,右图的“瓶颈残差模块”(bottleneck residual block)可以有更好的效果,它依次由1×1、3×3、1×1这三个卷积层堆积而成,这里的1×1的卷积能够起降维或升维的作用,从而令3×3的卷积可以在相对较低维度的输入上进行,以达到提高计算效率的目的。
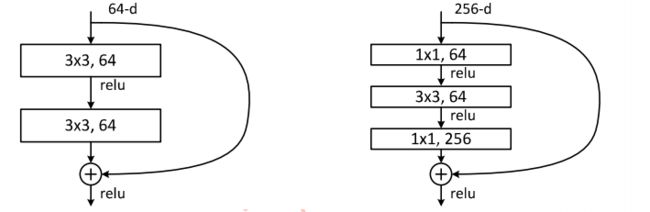
3、残差模块代码实现
def conv3x3(in_plans,out_planes,stride=1):
return nn.Conv2d(in_plans,out_planes,kernel_size=3,stride=stride
,padding=1,bias=False)
class BasicBlock(nn.Module):
def __init__(self,inplanes,planes,stride=1,downsample=None):
super(BasicBlock,self).__init__()
self.conv1 = conv3x3(inplanes,planes,stride)
self.bn1 = nn.BatchNorm2d(planes)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes,planes)
self.bn2 = nn.BatchNorm2d(planes)
self.downsample = downsample
self.stride = stride
def forward(self,x):
residual = x
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.conv2(x)
out = self.bn2(x)
if self.downsample is not None:
residual = self.downsample(out)
out += residual
out = self.relu(out)
return out
PyTorch将上面介绍过这些网络,都在torchvision.model 里面,同时大部分网络都有预训练好的参数。可以根据具体任务进行迁移学习和微调。
参考文献:
1、CNN网络架构演进:从LeNet到DenseNet:https://www.cnblogs.com/skyfsm/p/8451834.html
2、《深度学习之Pytorch》