ue4 本地化要点详解
UE4中的本地化系统以“文本”的本地化为中心,还包含资源的本地化,诸如声音,图像等。
要查看本地化是否生效,请使用编辑器的standalone 模式运行游戏进行查看。在编辑器运行时,会有一些本地化未生效。
关于文化(cultures)
文化名称(IETF语言标记)由三个连字符分隔的部分组成
-
两个字母的ISO 639-1语言代码(例如“zh”)。
-
可选的四字母ISO 15924字符集代码(例如“Hans”)。
-
可选的双字母ISO 3166-1国家和地区代码(例如“CN”)。
当UE4查找特定文化的本地化数据时,它会将它们从最大特定到最不特定。例如:
-
zh-Hans-CN被处理为“zh-Hans-CN”,然后是“zh-CN”,然后是“zh-Hans”,然后是“zh”。
-
en-GB被处理为“en-GB”,然后是“en”。
为了实现特定文化的最广泛覆盖,请使用有效的最不具体的文化代码。 使用“zh-Hans”进行简化本地化,使用“zh-Hant”进行传统本地化。
本地化目标
UE4的本地化流程是基于本地化目标来进行工作的,要实现本地化,必须要有本地化目标并且加载本地化目标!!!。本地化目标指的是经过命名的独立的本地化数据模块。 目标中的文本是从一组特定来源中收集,存储在 Manifest 文件内,在针对特定语言文化 (Culture) 的存档文件(Archives)中翻译,编译成针对特定语言的本地化资源文件(LocRes),然后由系统加载以供显示。
一个项目可以只有一个目标以便简化实施,也可以有多个目标以便将项目的本地化数据分成各个独立部分。Unreal 编辑器就有一个独立于虚幻引擎其他部分的目标,因此可以在对编辑器进行本地化的同时,避免将编辑器的本地化数据随游戏一起分发。通常来讲,游戏会用一个目标用于游戏本体的本地化数据,并使用额外的目标来实现游戏的扩展包内容。
本地化目标由两部分组成:其配置(存储在Config/Localization/)及其数据(存储在Content/Localization/{TargetName}/)
如果我们假设本地化目标使用英语(“en”)和法语(“fr”),那么它在Content/Localization/文件夹中的布局将如下所示:
{TargetName}/
{TargetName}.manifest
{TargetName}.locmeta
en/
{TargetName}.archive
{TargetName}.po
{TargetName}.locres
fr/
{TargetName}.archive
{TargetName}.po
{TargetName}.locres
| 文件 |
描述 |
| {TargetName}.manifest |
|
| {TargetName}.archive |
|
| {TargetName}.po |
|
| {TargetName}.locres |
|
| {TargetName}.locmeta |
|
本地化目标还指定“本地”文化,应将其设置为您创作内容的文化(通常称为“源文本”或“源数据”)。(在没有指定文化时,引擎将自动查找所在系统指定的文化, 如果用户自己指定了文化,引擎就会去找你指定的那个文化。在找不到指定的文化时(比如这里你使用了-culture=ja,也就是要找日文,结果没找到),自动找这个“本地”文化。)本地文化也可以包含“翻译”,就像任何其他文化一样,尽管本地文化翻译只是为了便于复制编辑源文本而不直接编辑源代码或资产。 外国文化使用本地文化的翻译文本作为翻译的源文本,并且如果更改本地文化的翻译文本将变得“陈旧”,也就是需要重新翻译(在本地化编译步骤中有一个设置以允许过时翻译(如果需要))。
默认创建工程并不会有本地化目标。所有上述文件和文件夹都由本地化流程工具生成。本地化流程工具有两种调用方法,通常我们是使用第一种:
1.本地化控制板界面,从编辑器的window->locailzation bashboard 打开
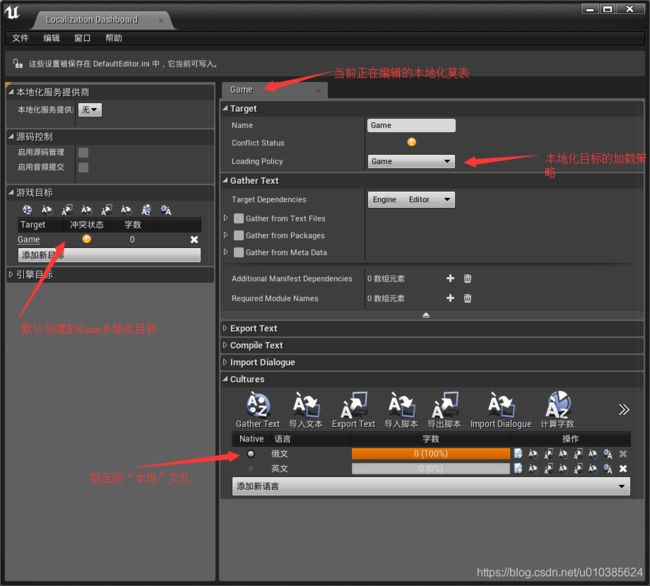
默认情况下,仪表板将为您创建名为Game的本地化目标,但在你没有为该本地化目标指定“本地”文化之前,则该控制板界面并不会为你的工程创建真正的本地化目标的文件。 除非您的项目特别复杂,否则这可能是您需要的唯一本地化目标。 如果添加新的本地化目标,请确保为其指定适当的加载策略(通常为游戏)。如果不这样做,则本地化目标不会在运行时加载。 当指定完本地文化后,就会在 Config/Localization中创建本地化目标的配置。 指定完本地文化后,我们还要指定需要收集本地化文本的源代码(C++文件)和游戏资源位置,关于本地化文本的概念请看下面的介绍。

之后,我们就可以开始收集本地化文本了。 通过GatherText 按钮就可以搜集文本。
关于具体使用,请看这里UE4制作多语言游戏(本地化功能详解) - 执手画眉弯的博客 - CSDN博客
2.使用 Unreal Automation Tool (UAT) 的 Localize 脚本。具体使用请看Localization Tools,
运行引擎文件夹中的Engine/Build/BatchFiles/RunUAT.bat 批处理文件,调用UAT。常用帮助命令包括 runUAT -help 和runUAT -list 。UAT的使用请看BuildGraph和 How to use Automation Tool?。
关于本地化的一些基本概念
1.本地化文本
文本本地化的主要组件是FText类, 本地化文本是本地化的基本元素。本地化文本由命名空间、键名、源字符串和显示字符串共同组成。可本地化的文本由三个组件组成:命名空间 ,键名和字符串。 通过命名空间和键名便能为文本定义唯一的标识索引。命名空间通常表示用来当前所在的游戏模块,比如某一个页面。 通过使用不同的命名空间,可以帮助在不同上下文的环境下同样的文本单来表达不同的意思。键提供了与文本有关的特定上下文。 源字符串是尚未翻译原文形式的字符串,通常是作为翻译的验证。显示字符串是将要呈现的字符串形式,通常是根据源字符串翻译而来。
在UE4中创建可本地化文本的最常用方法是使用文本字面值
在c++中创建文本字面值的方法:
可以使用LOCTEXT系列宏在C ++中创建文本文字。
| 宏 |
描述 |
| NSLOCTEXT |
通过定义命名空间,键和源字符串来创建本地化的文本片段。 |
| LOCTEXT |
通过定义键和源字符串来创建本地化的文本片段,并使用通过LOCTEXT_NAMESPACE定义的命名空间。必须在使用前通过 #define LOCTEXT_NAMESPACE "你的命名空间名字" 定义LOCTEXT_NAMESPACE 通常该宏在cpp文件中定义,并在cpp文件末尾取消定义 #undef LOCTEXT_NAMESPACE |
注意:所有参数必须为字符串文字,即用“”包裹的文字。不能是变量
Example:
// Define the namespace to use with LOCTEXT
// This is only valid within a single file, and must be undefined before the end of the file
#define LOCTEXT_NAMESPACE "MyNamespace"
// Create text literals
const FText HelloWorld = NSLOCTEXT("MyOtherNamespace", "HelloWorld", "Hello World!")
const FText GoodbyeWorld = LOCTEXT("GoodbyeWorld", "Goodbye World!")
// Undefine the namespace before the end of the file
#undef LOCTEXT_NAMESPACE
在INI文件中创建文本文字
可以使用NSLOCTEXT宏语法在INI文件中创建文本文字。
在资产中创建文本文字
可以使用FText属性创建文本文字。将自动为您生成密钥,但您可以使用文本字段旁边的高级组合为文本定义自定义命名空间或密钥。使用默认命名空间或密钥也很好。
格式化本地化文本
文本格式化提供了一种通过使用格式占位符来指代实际文本的可本地化格式模式,以更容易本地化的方式组合文本的方法。
格式占位符包含在一对花括号中,可以是数字(用于基于索引的格式)或字符串(用于基于名称的格式)。例如:
"You have {0} health left."
"You have {CurrentHealth} health left."
C ++中的文本格式化
C ++中的文本格式由FText::Format函数族处理。每个函数都采用一种FTextFormat模式,该模式将从一个FText实例隐式构造,然后是下表中定义的其他参数。
|
|
格式化类型 |
描述 |
| FText::Format |
通用格式化文本 |
接受基于索引的参数(使用FFormatOrderedArguments或可变参数)或基于名称的参数(使用FFormatNamedArguments)。 |
| FText::FormatOrdered |
基于变量索引的格式化 |
接受任何FFormatArgumentValue可以构造的参数 |
| FText::FormatNamed
|
基于变量名称的格式化 |
接受连续的名称(FString可以构造的任何东西),然后接受值(FFormatArgumentValue可以构造的任何东西)参数。 |
在蓝图中使用格式化文本
蓝图中的文本格式由“ 格式文本”节点处理。此节点可以采用文字格式模式,也可以将节点链接到另一个文本引脚。
|
|
|

-
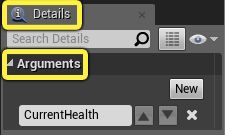
指定文字格式模式时,将自动生成格式参数引脚。
-
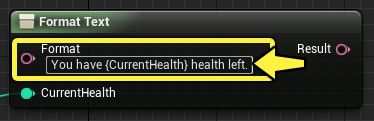
格式模式链接到另一个文本引脚时,必须使用节点的“详细信息”面板手动指定格式的参数。
本地化的文本生成(数字,时间,大小写转换)
文本生成使用国际化数据来生成不依赖于直接本地化的文化正确文本。本地化的文本生成有三种类型:数字,时间和转换。
他们会根据当前所用的文化来生成适用于当前文化的显示格式
数字文本生成
C ++中的数字生成
C ++中的数字生成由以下函数处理
| 功能 |
描述 |
| FText :: AsNumber |
将UE4支持的任何数字类型转换为用户友好的文本表示形式(“1234.5”变为“1,234.5”)。 |
| FText :: AsPercent |
将float或double转换为百分比文本表示形式(“0.2”变为20%)。 |
| FText :: AsMemory |
将值(以字节为单位)转换为用户友好的内存表示形式(“1234”变为“1.2 KiB”)。 |
| FText :: AsCurrencyBase |
将货币基本表示形式的值转换为用户友好的货币表示形式(“123450”表示“USD”变为“$ 1,234.50”)。 |
蓝图中的数字生成
蓝图中的数字生成由以下节点处理。
| 节点 |
描述 |
| ToText(byte),ToText(int),ToText(float) |
将支持的数字类型转换为用户友好的文本表示形式(“1234.5”变为“1,234.5”)。 |
| AsPercent |
将float或double转换为百分比文本表示形式(“0.2”变为20%)。 |
| AsCurrency |
将货币基本表示形式的值转换为用户友好的货币表示形式(“123450”表示“USD”变为“$ 1,234.50”)。 |
时间
C ++中的时间生成
C ++中的时间顺序生成由以下函数处理。
| 功能 |
描述 |
| FText :: AsDate |
将FDateTime值转换为用户友好的日期表示。 |
| FText :: AsTime |
将FDateTime值转换为用户友好的时间表示。 |
| FText :: AsDateTime |
将FDateTime值转换为用户友好的日期和时间表示。 |
| FText :: AsTimespan |
将FTimespan值转换为用户友好的delta时间表示(以小时,分钟和秒为单位)。 |
以上大多数都采用EDateTimeStyle来控制输出(默认来自活动的语言环境,但可以设置为“ “short”, “medium”, “long”, or “full”)。
注意:期望生成时间默认为基于0时区的时间(它将转换为本地时区)。如果给定时间不是基于0时区的(例如,如果它已经在本地时间),那么您应该FText::GetInvariantTimeZone()作为时区参数传递。
蓝图中的时间顺序生成
蓝图中的时间顺序生成由以下节点处理。
| 节点 |
描述 |
| AsDate |
将非基于UTC的“DateTime”值按原样转换为用户友好的日期表示(不调整到本地时区)。 |
| AsDate (from UTC) |
将基于UTC的“DateTime”值转换为用户友好的日期表示(调整为本地时区)。 |
| AsTime |
将非基于UTC的“DateTime”值按原样转换为用户友好的时间表示(不调整到本地时区)。 |
| AsTime (from UTC) |
将基于UTC的“DateTime”值转换为用户友好的时间表示(调整为本地时区)。 |
| AsDateTime |
将非基于UTC的“DateTime”值转换为用户友好的日期和时间表示(不调整到本地时区)。 |
| AsDateTime (from UTC) |
将基于UTC的“DateTime”值转换为用户友好的日期和时间表示(调整为本地时区)。 |
| AsTimespan |
将“Timespan”值转换为用户友好的delta时间表示(以小时,分钟和秒为单位)。 |
大小写转换
c++中的大小写转换
| FText::ToLower |
以符合Unicode的方式将FText实例转换为其小写形式。 |
| FText::ToUpper |
以符合Unicode的方式将FText实例转换为其大写形式。 |
蓝图中的大小写转换
| Text to Lower |
以符合Unicode的方式将“Text”实例转换为其小写形式。 |
| Text to Upper |
以符合Unicode的方式将“Text”实例转换为其大写形式。 |
2.资产本地化
资产本地化就是可以在选择不同文化时,使用不同的资产,来代替“源资产”。
要管理,创建和使用指定文化的本地化资产,必须具有可用于指定文化的本地化文件,即必须具有 Content/Localization/{CultureName}/ 文件夹,并且通常需要文件夹不是空的。如果你在本地化控制板界面中加入了某个文化并执行了GatherText,那么这个文化就具有这个文件夹并且非空。
本地化资产存在于项目“Content”文件夹中“L10N”文件夹下,每种文化都有一个文件夹,存放自己文化的本地化资产。因此,如果您有一个已命名的资产/Game/MyFolder/MyAsset并且您想要本地化法语资产(“fr”),那么本地化的资产就是/Game/L10N/fr/MyFolder/MyAsset。(这里的/Game就是Content文件夹, L10N 是 localization 的缩写形式,意即在 l 和 n 之间有 10 个字母,本意是指软件的“本地化”)。
可以通过右键点击“源资产”, 弹出菜单中的资产本地化 ,来管理本地化资产。 默认情况下,内容浏览器中隐藏了本地化资产。单击“ 查看选项”>“显示本地化资产”以查看它们。
如果你在运行时改变文化,本地化文本将重新加载,但本地化资产并不会在重新加载!!。 已经加载过的资源将继续使用原有文化的本地化资源,还未加载的资源在加载时,将使用新的文化的本地化资源。 如果您计划在运行时支持动态文化更改,则可能需要重新启动游戏才能使这些更改生效。重新启动游戏会清除并重新加载本地化的资产。
资产组
资产组可以你允许你为一组资产类,分配单独的文化。最常见的情况是允许显示的文字等使用中文,而音频使用英文。
要创建资产组。请在DefaultGame.ini类型的配置文件中设置如下内容
[Internationalization.AssetGroupClasses]
+Audio=SoundWave
+Audio=DialogueWave
这个资产组名叫Audio,包含的资产类为SoundWave和DialogueWave
本地化字体
字体本地化可以通过以下两种方式之一进行:
-
-
-
您可以使用复合字体生成适用于所有文化的单一字体资源。
-
您可以使用资产本地化为每种文化生成单独的字体资产。
-
-
如果您的项目不支持在运行时更改动态文化,并且不显示任何不受限制的用户定义文本(例如播放器名称或聊天窗口),则仅建议使用第二个选项。在所有其他情况下,第一个选项将提供更好的结果。
本地化对话
本地化对话以 Dialogue Wave类型的资源为中心。该资源可以通过本地化控制板界面的GatherText 收集其中的 spoken text 和 optional subtitle overrides。
Dialogue Wave 提供了一种 根据不同说话者与倾听者,说出意思相同的一段话,却使用不同语音与显示字幕的一种方法。

关于Dialogue Wave 的使用,请看这里使用对话语音和和Waves
对话进行本地化,我们使用 UE4为我们提供的本地化控制板界面。 当我们GatherText后,我们可以使用控制板界面中的导出此目标的对话脚本(所有语音)按钮,默认它将选中本地化目标的内容文件夹,点击确认后,这将在本地化目标的内容文件夹的每个文化文件夹中生成一个额外的文件,称为{TargetName}Dialogue.csv。
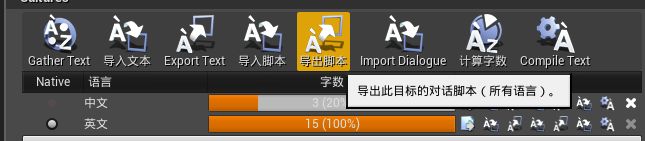
每个CSV 文件, 包含通过本地化管道从您的资产收集的所有Dialogue Wave 的当前文化的信息。每一行对应一个Dialogue Wave中的Dialogue Context
注意:只有已经对某个Dialogue Context的spoken text生成的key进行过本地化翻译,在本地化CSV中才会有这一个Dialog Context的信息。
其中
SpokenDialogue 字段 表示 Dialogue Wave的spoken text在当前Dialogue Context下的当前文化的翻译信息,这个字段的信息可以修改,修改后的信息将在该CSV被重新导入后,设置为新的文化翻译内容。
AudioFileName 字段 表示 Dialogue Context在当前文化下,所使用的Sound Wave所使用的WAV源文件名称。这个名称是不可手动修改的,切记!!。 这个名字的生成格式,是在工程设置中的Audio 页签的中 Dialogue Filename Format设置的。
我们使用该CSV的主要目的,是根据该CSV中的AudioFileName字段,导入并生成不同文化的Dialogue Wave 和 Sound Wave 资产,以实现资产的本地化。
首先,我们需要创建一个存放所有原始录制音频文件的文件夹MyRecordedAudio,在其中,根据文化名称创建不同文件夹,比如fr,en, zh,我们需要将我们录制的音频文件命名为AudioFileName字段定义的名称,并放到指定文化所在文件夹中。比如 我们 AudioFIleName 中定义的名称为 dialog_A0115BEA00000000.wav, 那么我们把录制的中文音频文件放置到zh文件夹中,并命名为dialog_A0115BEA00000000.wav。 最终路径是MyRecordedAudio/zh/dialog_A0115BEA00000000.wav. 然后我们我们使用本地化控制板界面中的import Dialogue 按钮导入。这里需要设置Raw Audio Path 为我们的MyRecordedAudio。

在运行时管理活动的文化
对文化的管理有三种情况:
1.language: language控制使用的本地化数据,包括文本翻译和一般的本地化资产。、
2.locale: 区域设置是用来控制数字/日期/时间/等的格式化。
3.Asset group culture: 这个控制特定资产组中的资产所使用的文化。
你可以通过SetActiveCulture一次性将所有这些都设置成一种文化。但如果你需要使用单独的资产组,比如使用另一种文化的音频。那么你需要分开处理。
获取正在使用的文化
c++ 要在之前加上FInternationalization::Get().
| Function |
Description |
| GetCurrentLanguage |
获取language当前使用的文化的IETF语言标记 |
| GetCurrentLocale |
获取locale当前使用的文化的IETF语言标记 |
| GetCurrentAssetGroupCulture |
获取指定资产组当前使用的文化的IETF语言标记 |
设置正在使用的文化
| Function |
Description |
| SetCurrentCulture |
使用IETF语言标记将language,locale,和所有资产组都设置成指定文化 |
| SetCurrentLanguage |
使用IETF语言标记设置language为指定文化 |
| SetCurrentLocale |
使用IETF语言标记设置locale为指定文化 |
| SetCurrentLanguageAndLocale |
使用IETF语言标记设置language和locale为指定文化 |
| SetCurrentAssetGroupCulture |
使用IETF语言标记设置特定的资产组为指定文化 |
| ClearCurrentAssetGroupCulture |
清空指定资产组的文化,并使用当前language使用的文化 |
你还可以通过控制台命令在非shoping版本中来指定文化
culture=fr
language=fr
locale=fr
查询可用文化
| 功能 |
描述 |
| GetDefautCulture |
获取系统指定的文化的IETF语言标记 |
| GetNativeCulture |
获取“本地”文化的IETF语言标记 |
| GetLocalizedCultures |
获取可用的文化。指在项目中添加的所有文化的IETF语言标记 |
| GetSuitableCulture |
从可用文化列表中获取最合适的文化的IETF语言标记。 |
| GetCultureDisplayName |
从IETF语言标记中获取文化的显示名称。比如zh在中文中显示为中文,在英文中显示chinese |
覆盖默认文化
UE4通过查询底层平台层以获取活动语言和区域设置来确定默认区域性。如果不支持平台语言,UE4将回退到本地化目标的本地语言。在已发布的项目中,您可能不会覆盖此行为。但是,在开发过程中,这些覆盖可用于测试其他语言。
项目的默认设置通常在DefaultGame.ini中定义,也可以在DefaultGameUserSetting.ini中定义,且DefaultGameUserSetting中的优先级更高。
此示例显示将文化设置为法语。
[Internationalization]
culture=fr
例如:
此示例显示将语言和地区设置为法语,同时将名为Audio的资产组设置为日语。
[Internationalization]
language=fr
locale=fr
[Internationalization.AssetGroupCultures]
+Audio=ja
也可以使用命令行标志覆盖这些设置。
-culture=fr
-language=fr
-locale=fr