CNN+SVM实现(基于TensorFlow,python,SVM基于sklearn库,附带自己数据)
简单说明
1.简单将CNN与SVM进行结合:将经过CNN训练的数据的全连接层输出(训练集与验证集都进行)喂给SVM(只取一部分数据进行,SVM对小数据优势比较大,大数据花费的时间多)。
2.CNN+SVM:CNN充当特征提取器,SVM充当分类器。
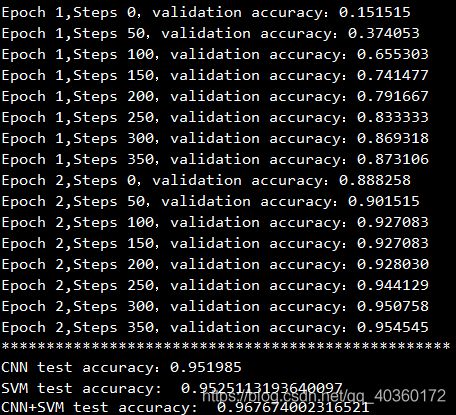
3.结果对比:CNN,SVM,CNN+SVM。
4.数据参见之前博客博客链接
编程实现
# -*- coding: utf-8 -*-
"""
Created on Sun Mar 29 21:19:03 2020
@author: 小小飞在路上
"""
import numpy as np
from sklearn.model_selection import train_test_split #数据集的分割函数
from sklearn.preprocessing import StandardScaler #数据预处理
import pandas as pd
import warnings
import tensorflow as tf
from sklearn import svm
warnings.filterwarnings('ignore')
graph=tf.get_default_graph() #分配内存
# In[]
#
def weight_variables(shape):
"""权重"""
w=tf.Variable(tf.random_normal(shape=shape,mean=0.0,stddev=1.0,seed=1))
# w=tf.Variable(tf.truncated_normal(shape=shape,mean=0.0,stddev=1.0,seed=1))
return w
def bias_variables(shape):
"""偏置"""
b=tf.Variable(tf.constant(0.0,shape=shape))
return b
def CNN_model(n_future,n_class,n_hidden,n_fc1,future_out):
"""模型结构"""
with tf.variable_scope("data"):
x=tf.placeholder(tf.float32,[None,n_future])
y_true=tf.placeholder(tf.int32,[None,n_class])
keep_prob = tf.placeholder(tf.float32)
with tf.variable_scope("cov1"):
w_conv1=weight_variables([1,3,1,n_hidden])
b_conv1=bias_variables([n_hidden])
x_reshape = tf.reshape(x,[-1,1,n_future,1])
#卷积、激活
x_relu1=tf.nn.relu(tf.nn.conv2d(x_reshape,w_conv1,strides=[1,1,1,1],padding="SAME")+b_conv1)
#池化
x_pool1=tf.nn.max_pool(x_relu1,ksize=[1,1,2,1],strides=[1,1,2,1],padding="SAME")
with tf.variable_scope("conv_fc"):
#全连接
w_fc1=weight_variables([1*future_out*n_hidden,n_fc1])
b_fc1=bias_variables([n_fc1])
x_fc_reshape=tf.reshape(x_pool1,[-1,1*future_out*n_hidden])
y_fc1=tf.matmul(x_fc_reshape,w_fc1)+b_fc1
h_fc1_drop = tf.nn.dropout(y_fc1, keep_prob)
w_fc2=weight_variables([n_fc1,n_class])
b_fc2=bias_variables([n_class])
y_predict=tf.matmul(h_fc1_drop,w_fc2)+b_fc2
with tf.variable_scope("soft_cross"):
loss=tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y_true,logits=y_predict))
with tf.variable_scope("opmizer"):
# train_op=tf.train.AdamOptimizer(0.01).minimize(loss)
train_op=tf.train.RMSPropOptimizer(0.001, 0.9).minimize(loss)
with tf.variable_scope("acc"):
Y_truelable=tf.argmax(y_true,1)
Y_predictlable=tf.argmax(y_predict,1)
equal_list=tf.equal(Y_truelable,Y_predictlable)
#equal_list None个样本
accuracy=tf.reduce_mean(tf.cast(equal_list,tf.float32))
return x,y_true,keep_prob,y_fc1,train_op,accuracy
# In[]
#数据读取及划分
url = 'C:/Users/weixifei/Desktop/TensorFlow程序/data1.csv'
data = pd. read_csv(url, sep=',',header=None)
data=np.array(data)
X_data=data[:,:23]
Y=data[:,23]
labels=np.asarray(pd.get_dummies(Y),dtype=np.int8)
X_train,X_,Y_train,Y_=train_test_split(X_data,labels,test_size=0.3,random_state=20)
X_test,X_vld,Y_test,Y_vld=train_test_split(X_,Y_,test_size=0.1,random_state=20)
# In[]
#数据标准化处理
stdsc = StandardScaler()
X_train=stdsc.fit_transform(X_train)
X_test=stdsc.fit_transform(X_test)
X_vld=stdsc.fit_transform(X_vld)
Y_train_1=np.argmax(Y_train,axis=1)
Y_test_1=np.argmax(Y_test,axis=1)
Y_vld_1=np.argmax(Y_vld,axis=1)
# In[]
n_future=23
n_class=12
n_hidden=16
n_fc1=256
if n_future % 2==0:
future_out=n_future//2
else:
future_out=n_future//2+1
#模型调用
x,y_true,keep_prob,y_fc1,train_op,accuracy=CNN_model(n_future,n_class,n_hidden,n_fc1,future_out)
init_op=tf.global_variables_initializer()
training_epochs=2
batch_size = 64
total_batches=X_train.shape[0]//batch_size
# In[]
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for epoch in range(training_epochs):
for i in range(total_batches):
start=(i*batch_size)%X_train.shape[0] #
end=start+batch_size
sess.run(train_op,feed_dict={
x:X_train[start:end],y_true:Y_train[start:end],keep_prob:0.5})
if i % 50==0:
print("Epoch %d,Steps %d,validation accuracy:%f"%(epoch+1,i,sess.run(accuracy,feed_dict={
x:X_vld,y_true:Y_vld,keep_prob:1})))
x_temp1=sess.run(y_fc1,feed_dict={
x:X_train})
x_temp2=sess.run(y_fc1,feed_dict={
x:X_test})
clf = svm.SVC(C=0.9, kernel='linear') # linear kernel
#SVM训练只取一部分数据
clf.fit(X_train[:1000], Y_train_1[:1000])
clf1 = svm.SVC(C=0.9, kernel='linear') # linear kernel
#SVM训练只取一部分数据
clf1.fit(x_temp1[:1000], Y_train_1[:1000])
# SVM选择了linear核,C选择了0.9
print("*"*50)
print("CNN test accuracy:%f"%(sess.run(accuracy,feed_dict={
x:X_test,y_true:Y_test,keep_prob:1})))
print("SVM test accuracy: ",clf.score(X_test, Y_test_1))
print("CNN+SVM test accuracy: ",clf1.score(x_temp2, Y_test_1))
结果