NOIP 2015 普及组
文章目录
- T1 金币
-
- T1分析
- T2 扫雷游戏
-
- T2分析
- T3 求和
-
- T3分析
- T4 推销员
-
- T4分析
T1 金币
题目点击→计蒜客 [NOIP2015] 金币
题目描述
国王将金币作为工资,发放给忠诚的骑士。第一天,骑士收到一枚金币;之后两天(第二天和第三天),每天收到两枚金币;之后三天(第四、五、六天),每天收到三枚金币;之后四天(第七、八、九、十天),每天收到四枚金币……;这种工资发放模式会一直这样延续下去:当连续 N N N 天每天收到 N N N 枚金币后,骑士会在之后的连续 N + 1 N+1 N+1 天里,每天收到 N + 1 N+1 N+1 枚金币。
请计算在前 K K K 天里,骑士一共获得了多少金币。
输入格式
输入只有 1 1 1 行,包含一个正整数 K K K ,表示发放金币的天数。
输出格式
输出只有 1 1 1 行,包含一个正整数,即骑士收到的金币数。
数据范围
对于 100 % 100\% 100% 的数据, 1 ≤ K ≤ 10 , 000 1 \le K \le 10,000 1≤K≤10,000。
样例说明
样例1:
骑士第一天收到一枚金币;第二天和第三天,每天收到两枚金币;第四、五、六天,每天收到三枚金币。因此一共收到 1 + 2 + 2 + 3 + 3 + 3 = 14 1+2+2+3+3+3=14 1+2+2+3+3+3=14 枚金币。
T1分析
送分题,按照题目要求一天一天模拟,两层for循环就可以了,第一层枚举个数,第二层循环枚举所有的数字。
#include
using namespace std;
int main(){
int n;
cin >> n;
long long sum = 0;
for(int i = 0; ;i++){
for(int j = 0; j < i; j++){
sum += i;
n--;
if(n == 0){
cout << sum << endl;
return 0;
}
}
}
return 0;
}
T2 扫雷游戏
题目点击→计蒜客 [NOIP2015] 扫雷游戏
题目描述
扫雷游戏是一款十分经典的单机小游戏。在 n n n 行 m m m 列的雷区中有一些格子含有地雷(称之为地雷格),其他格子不含地雷(称之为非地雷格)。玩家翻开一个非地雷格时,该格将会出现一个数字——提示周围格子中有多少个是地雷格。游戏的目标是在不翻出任何地雷格的条件下,找出所有的非地雷格。
现在给出 n n n 行 m m m 列的雷区中的地雷分布,要求计算出每个非地雷格周围的地雷格数。
注:一个格子的周围格子包括其上、下、左、右、左上、右上、左下、右下八个方向上与之直接相邻的格子。
输入格式
输入文件第一行是用一个空格隔开的两个整数 n n n 和 m m m ,分别表示雷区的行数和列数。
接下来 n n n 行,每行 m m m 个字符,描述了雷区中的地雷分布情况。字符’*’表示相应格子是地雷格,字符’?’表示相应格子是非地雷格。相邻字符之间无分隔符。
输出格式
输出文件包含 n n n 行,每行 m m m 个字符,描述整个雷区。用’*’表示地雷格,用周围的地雷个数表示非地雷格。相邻字符之间无分隔符。
数据范围
对于 100 % 100\% 100% 的数据, 1 ≤ n ≤ 100 , 1 ≤ m ≤ 100 1 \le n \le 100, 1 \le m \le 100 1≤n≤100,1≤m≤100。
T2分析
简单模拟题,其实也是送分题,每次找到一个地雷之后,把他周围的所有数字全部 + 1 +1 +1 就可以了
#include
using namespace std;
const int N = 1e2 + 9;
char a[N][N];
int f[N][N];
int dx[] = {1, -1, 0, 0, 1, -1, 1, -1};
int dy[] = {0, 0, -1, 1, 1, -1, -1, 1};
int main() {
int n, m;
cin >> n >> m;
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= m; j++) {
cin >> a[i][j];
if (a[i][j] == '*') {
for (int k = 0; k < 8; k++) {
int x = i + dx[k];
int y = j + dy[k];
f[x][y]++;
}
}
}
}
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= m; j++) {
if (a[i][j] == '*') {
cout << '*';
} else {
cout << f[i][j];
}
}
cout << endl;
}
return 0;
}
T3 求和
题目点击→ 计蒜客 [NOIP2015] 求和
题目描述
一条狭长的纸带被均匀划分出了 n n n 个格子,格子编号从 1 1 1 到 n n n。每个格子上都染了一种颜色 c o l o r i color_i colori 用 [ 1 , m ] [1,m] [1,m] 当中的一个整数表示),并且写了一个数字 n u m b e r i number_i numberi。
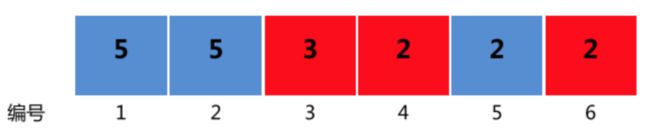
定义一种特殊的三元组: ( x , y , z ) (x,y,z) (x,y,z),其中 x , y , z x,y,z x,y,z 都代表纸带上格子的编号,这里的三元组要求满足以下两个条件:
-
x , y , z x,y,z x,y,z 是整数, x < y < z , y − x = z − y x
-
c o l o r x = c o l o r z color_x=color_z colorx=colorz
满足上述条件的三元组的分数规定为 ( x + z ) × ( n u m b e r x + n u m b e r z ) (x+z) \times (number_x+number_z) (x+z)×(numberx+numberz)。整个纸带的分数规定为所有满足条件的三元组的分数的和。这个分数可能会很大,你只要输出整个纸带的分数除以 10 , 007 10,007 10,007 所得的余数即可。
输入格式
第一行是用一个空格隔开的两个正整数 n n n 和 m , n m,n m,n 表纸带上格子的个数, m m m 表纸带上颜色的种类数。
第二行有 n n n 用空格隔开的正整数,第 i i i 数字 n u m b e r number number 表纸带上编号为 i i i 格子上面写的数字。
第三行有 n n n 用空格隔开的正整数,第 i i i 数字 c o l o r color color 表纸带上编号为 i i i 格子染的颜色。
输出格式
共一行,一个整数,表示所求的纸带分数除以 10 , 007 10,007 10,007 所得的余数。
数据范围
对于第 1 1 1 组至第 2 2 2 组数据, 1 ≤ n ≤ 100 1 \le n \le 100 1≤n≤100, 1 ≤ m ≤ 5 1 \le m \le 5 1≤m≤5;
对于第 3 3 3 组至第 4 4 4 组数据, 1 ≤ n ≤ 3000 1 \le n \le 3000 1≤n≤3000, 1 ≤ m ≤ 100 1 \le m \le 100 1≤m≤100;
对于第 5 5 5 组至第 6 6 6 组数据, 1 ≤ n ≤ 100000 1 \le n \le 100000 1≤n≤100000, 1 ≤ m ≤ 100000 1 \le m \le 100000 1≤m≤100000,且不存在出现次数超过 20 20 20 的颜色;
对于全部 10 10 10 组数据, 1 ≤ n ≤ 100000 1 \le n \le 100000 1≤n≤100000, 1 ≤ m ≤ 100000 1 \le m \le 100000 1≤m≤100000, 1 ≤ c o l o r i ≤ m 1 \le color_i \le m 1≤colori≤m, 1 ≤ n u m b e r i ≤ 100000 1 \le number_i \le 100000 1≤numberi≤100000。
样例说明
样例1:
纸带如题目描述中的图所示。
所有满足条件的三元组为: ( 1 , 3 , 5 ) (1,3,5) (1,3,5), ( 4 , 5 , 6 ) (4,5,6) (4,5,6)。
所以纸带的分数为 ( 1 + 5 ) × ( 5 + 2 ) + ( 4 + 6 ) × ( 2 + 2 ) = 42 + 40 = 82 (1+5) \times (5+2)+(4+6) \times (2+2)=42+40=82 (1+5)×(5+2)+(4+6)×(2+2)=42+40=82。
T3分析
观察数据范围,首先前两组 n ≤ 100 n \leq 100 n≤100 所以直接 O ( n 3 ) O(n^3) O(n3) 暴力即可获得 20 % 20\% 20% 分
继续观察题目要求,可以看到首先我们要满足第一个条件 y − x = z − y y - x = z - y y−x=z−y,左右移动后可以得到式子 x + z = 2 ∗ y x + z = 2 *y x+z=2∗y 从这里我们可以知道, 2 ∗ y 2 * y 2∗y 必然是一个偶数,而 x + z = 2 ∗ y x + z = 2 * y x+z=2∗y 那就意味着 x , z x,z x,z 要么同是奇数要么同是偶数,当然如果不理解这个其实自己举个例子也就能发现了
继续往后看可以发现,我们所需要计算的贡献是跟 y y y 无关的,所以第一个式子可以得到一个结论, x , z x,z x,z 是同奇同偶的,在这个条件下我们可以发现,任意两个奇偶性相同的 x , z x,z x,z 必然存在一个 y y y 使得 y − x = z − y y - x = z - y y−x=z−y ,所以也就意味着只要奇偶性相同的两个数字 x , z x,z x,z 就一定可以满足 第一个条件
在有了这个条件后,其实 40 % 40\% 40% 的分数就可以获得了,只要暴力枚举 x , z x,z x,z 即可获得 40 % 40\% 40% 的分数
接下来看第二个条件,也就是 c o l o r x = c o l o r z color_x = color_z colorx=colorz,也就是说只要 x , z x,z x,z 奇偶性相同,并且颜色相同,那这组 x , z x,z x,z 就可以作为一组三元组的解,将贡献加到答案中
其实 60 % 60\% 60% 的数据也在提示这一点,接下来的考虑方向应该是颜色!
所以我们可以先将纸带进行奇偶的区分,将奇数部分和偶数部分单独取出,对于两部分分别取出颜色相同的所有元素,这部分所有元素就是可以任意两两组合成合法三元组的 x , z x,z x,z ,那我们现在要做的就是计算这组元素的贡献和
假设我们取出一组元素,比如取出一组同一个颜色的奇数元素,将这组元素的下标看做 a 1 , a 2 . . . a_1,a_2... a1,a2... 这组元素的 n u m b e r number number 看做 n 1 , n 2 . . . n_1,n_2... n1,n2... ,任意两两组合计算贡献,可以得到如下式子
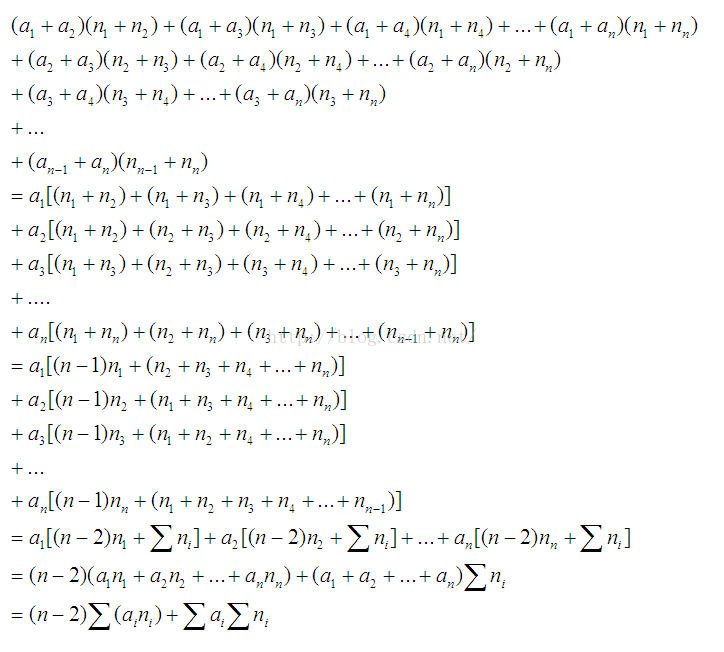
化简后的结果就是快速计算这组贡献和的方法,所以这里只需要在分别讨论奇偶的情况下,记录下同一个颜色的前缀下标和,前缀数字和,前缀数字乘下标的和,即可 O ( n ) O(n) O(n) 计算出结果
#include
#include
#include
#include
#include
using namespace std;
long long n,m,num[100005],cont[2][100005],cl;
long long sum1[3][100005],sum2[3][100005];
long long ans;
int main(){
scanf("%lld%lld",&n,&m);
for(int i = 1; i <= n; i++){
scanf("%lld",&num[i]);
}
for(int i = 1; i <= n; i++){
scanf("%lld",&cl);
if(i % 2 == 1){
ans = (ans + sum1[0][cl] % 10007 + i * sum1[1][cl] % 10007 + num[i] * sum1[2][cl] % 10007 + cont[0][cl] * i * num[i] % 10007) % 10007;
sum1[0][cl] = (sum1[0][cl] + num[i]*i) % 10007;
sum1[1][cl] = (sum1[1][cl] + num[i]) % 10007;
sum1[2][cl] = (sum1[2][cl] + i) % 10007;
cont[0][cl]++;
} else {
ans = (ans + sum2[0][cl] % 10007 + i * sum2[1][cl] % 10007 + num[i] * sum2[2][cl] % 10007 + cont[1][cl] * i * num[i] % 10007) % 10007;
sum2[0][cl] = (sum2[0][cl] + num[i] * i) % 10007;
sum2[1][cl] = (sum2[1][cl] + num[i]) % 10007;
sum2[2][cl] = (sum2[2][cl] + i) % 10007;
cont[1][cl]++;
}
}
printf("%lld",ans % 10007);
}
T4 推销员
点击查看→ 计蒜客 [NOIP2015] 推销员
题目描述
阿明是一名推销员,他奉命到螺丝街推销他们公司的产品。螺丝街是一条死胡同,出口与入口是同一个,街道的一侧是围墙,另一侧是住户。螺丝街一共有 N N N 家住户,第i家住户到入口的距离为 S i S_i Si 米。由于同一栋房子里可以有多家住户,所以可能有多家住户与入口的距离相等。阿明会从入口进入,依次向螺丝街的 X X X 家住户推销产品,然后再原路走出去。
阿明每走 1 1 1 米就会积累 1 1 1 点疲劳值,向第 i i i 家住户推销产品会积累 A i A_i Ai 点疲劳值。阿明是工作狂,他想知道,对于不同的 X X X ,在不走多余的路的前提下,他最多可以积累多少点疲劳值。
输入格式
第一行有一个正整数 N N N ,表示螺丝街住户的数量。
接下来的一行有 N N N 个正整数,其中第 i i i 个整数 S i S_i Si 表示第 i i i 家住户到入口的距离。数据保证 S 1 ≤ S 2 ≤ … ≤ S n < 1 0 8 S_1 \le S_2 \le … \le S_n<10^8 S1≤S2≤…≤Sn<108。
接下来的一行有 N N N 个正整数,其中第 i i i 个整数 A i A_i Ai 表示向第i户住户推销产品会积累的疲劳值。数据保证 A i < 1 0 3 A_i<10^3 Ai<103。
输出格式
输出 N N N行,每行一个正整数,第i行整数表示当 X = i X=i X=i 时,阿明最多积累的疲劳值。
数据范围
对于 20 % 20\% 20% 的数据, 1 ≤ N ≤ 20 1 \le N \le 20 1≤N≤20;
对于 40 % 40\% 40% 的数据, 1 ≤ N ≤ 100 1 \le N \le 100 1≤N≤100;
对于 60 % 60\% 60% 的数据, 1 ≤ N ≤ 1000 1 \le N \le 1000 1≤N≤1000;
对于 100 % 100\% 100% 的数据, 1 ≤ N ≤ 100000 1 \le N \le 100000 1≤N≤100000。
样例说明
样例1:
X = 1 X=1 X=1: 向住户 5 5 5 推销,往返走路的疲劳值为 5 + 5 5+5 5+5,推销的疲劳值为 5 5 5 ,总疲劳值为 15 15 15。
X = 2 X=2 X=2 : 向住户 4 4 4 、 5 5 5 推销,往返走路的疲劳值为 5 + 5 5+5 5+5 ,推销的疲劳值为 4 + 5 4+5 4+5 ,总疲劳值为 5 + 5 + 4 + 5 = 19 5+5+4+5=19 5+5+4+5=19。
X = 3 X=3 X=3: 向住户 3 3 3 、 4 4 4、 5 5 5 推销,往返走路的疲劳值为 5 + 5 5+5 5+5 ,推销的疲劳值 3 + 4 + 5 3+4+5 3+4+5,总疲劳值为 5 + 5 + 3 + 4 + 5 = 22 5+5+3+4+5=22 5+5+3+4+5=22。
X = 4 X=4 X=4 : 向住户 2 2 2、 3 3 3、 4 4 4、 5 5 5 推销,往返走路的疲劳值为 5 + 5 5+5 5+5 ,推销的疲劳值 2 + 3 + 4 + 5 2+3+4+5 2+3+4+5,总疲劳值 5 + 5 + 2 + 3 + 4 + 5 = 24 5+5+2+3+4+5=24 5+5+2+3+4+5=24。
X = 5 X=5 X=5 : 向住户 1 1 1、 2 2 2、 3 3 3、 4 4 4、 5 5 5 推销,往返走路的疲劳值为 5 + 5 5+5 5+5,推销的疲劳值 1 + 2 + 3 + 4 + 5 1+2+3+4+5 1+2+3+4+5,总疲劳值 5 + 5 + 1 + 2 + 3 + 4 + 5 = 25 5+5+1+2+3+4+5=25 5+5+1+2+3+4+5=25。
样例2:
X = 1 X=1 X=1 :向住户 4 4 4 推销,往返走路的疲劳值为 4 + 4 4+4 4+4 ,推销的疲劳值为 4 4 4 ,总疲劳值 4 + 4 + 4 = 12 4+4+4=12 4+4+4=12。
X = 2 X=2 X=2 :向住户 1 1 1、 4 4 4 推销,往返走路的疲劳值为 4 + 4 4+4 4+4 ,推销的疲劳值为 5 + 4 5+4 5+4 ,总疲劳值 4 + 4 + 5 + 4 = 17 4+4+5+4=17 4+4+5+4=17 。
X = 3 X=3 X=3 :向住户 1 1 1 、 2 2 2、 4 4 4 推销,往返走路的疲劳值为 4 + 4 4+4 4+4 ,推销的疲劳值为 5 + 4 + 4 5+4+4 5+4+4,总疲劳值 4 + 4 + 5 + 4 + 4 = 21 4+4+5+4+4=21 4+4+5+4+4=21 。
X = 4 X=4 X=4 :向住户 1 1 1、 2 2 2、 3 3 3、 4 4 4 推销,往返走路的疲劳值为 4 + 4 4+4 4+4,推销的疲劳值为 5 + 4 + 3 + 4 5+4+3+4 5+4+3+4,总疲劳值 4 + 4 + 5 + 4 + 3 + 4 = 24 4+4+5+4+3+4=24 4+4+5+4+3+4=24。或者向住户 1 1 1、 2 2 2、 4 4 4、 5 5 5 推销,往返走路的疲劳值为 5 + 5 5+5 5+5 ,推销的疲劳值为 5 + 4 + 4 + 1 5+4+4+1 5+4+4+1 ,总疲劳值 5 + 5 + 5 + 4 + 4 + 1 = 24 5+5+5+4+4+1=24 5+5+5+4+4+1=24。
X = 5 X=5 X=5 :向住户 1 1 1、 2 2 2、 3 3 3、 4 4 4、 5 5 5 推销,往返走路的疲劳值为 5 + 5 5+5 5+5 ,推销的疲劳值为 5 + 4 + 3 + 4 + 1 5+4+3+4+1 5+4+3+4+1 ,总疲劳值 5 + 5 + 5 + 4 + 3 + 4 + 1 = 27 5+5+5+4+3+4+1=27 5+5+5+4+3+4+1=27 。
T4分析
前 40 % 40\% 40% 分的数据有各种奇怪的做法…都可以
注意这里有句话 不走多余的路,所以简单分析一下题目就可以得到题意: N N N 选 X X X 的贡献其实就是对于我们所选的 X X X 家,总的疲劳值是 2 ∗ m a x ( s [ i ] ) + ∑ a [ i ] 2 * max(s[i]) +\sum a[i] 2∗max(s[i])+∑a[i]
那么正过来想,对于 X = 1 X = 1 X=1 的时候必然是选最大的 2 ∗ s [ i ] + a [ i ] 2 * s[i] + a[i] 2∗s[i]+a[i]
那么接着往下, X = 2 X = 2 X=2 其实无非就是在 X = 1 X = 1 X=1 的前提下,再选一家推销,而这里可以发现,如果上一次选的是 n o w now now,这次选 i i i 则可以发现,如果选在上一次选的左边,即 i < n o w i < now i<now 那贡献只有 a [ i ] a[i] a[i] 而如果选在右边即 i > n o w i > now i>now,贡献则是 a [ i ] + 2 ∗ ( s [ i ] − s [ n o w ] ) a[i] + 2 * (s[i] - s[now]) a[i]+2∗(s[i]−s[now])
而 X = 2 X = 2 X=2 的最大值必然存在于这两种情况里,所以由此可以推导出,每一步都可以这样来选
当然也可以倒过来验证这个思想,对于 X = N X = N X=N 时,必然是所有人都选,在这个前提下考虑 X = N − 1 X = N - 1 X=N−1
我们当然是去掉贡献最小的,就会得到 X = N − 1 X = N - 1 X=N−1 时的最大贡献值,继续往下每次减去最小影响的那户人即可
所以这个贪心思路无疑是没有问题的,那么接下来就是如何实现的问题了,对于现在处于第 n o w now now 家时,我们可以发现,对于 i < n o w i < now i<now 的所有住户只要求出最大的 a [ i ] a[i] a[i] 即可这一步我们完全可以用一个优先队列或者堆来维护
而右边部分我们要维护的则是 2 ∗ ( s [ i ] − s [ n o w ] ) + a [ i ] 2 * (s[i] - s[now]) + a[i] 2∗(s[i]−s[now])+a[i],每次在两种情况中选取最大值即可
当然这里存在一种特殊情况,那就是如果左边和右边两边对当前这一步的贡献值一样,该选哪一边?
其实取取谁都一样,这个很容易证明,我们当前处于 n o w now now,现在有 k 1 < n o w k1 < now k1<now 和 k 2 > n o w k2 > now k2>now 同时满足当前贡献最大的情况,那么我们这一步如果选 k 1 k1 k1,那必然会使得 k 2 k2 k2 的影响变得更大,因为距离更远了,所以我们下一步必然会选 k 2 k2 k2,而如果这一步选的是 k 2 k2 k2, k 1 k1 k1 本就是左边 a [ i ] a[i] a[i] 中最大的,虽然选取 k 2 k2 k2 后会使得处于左边的数变多,但是原本在 n o w now now 右边的点在额外附加了 2 ∗ ( s [ i ] − n o w ) 2*(s[i] - now) 2∗(s[i]−now) 之后的 a [ i ] a[i] a[i] 都没有 a [ k 1 ] a[k1] a[k1] 大,那就算点变多了,左边最大的依旧是 k 1 k1 k1,所以下一步必然会选择 k 1 k1 k1
这里如果右边的点不使用优先队列维护的话,时间复杂度最好情况下是 O ( n l o g n ) O(nlogn) O(nlogn),最坏情况下是 O ( n 2 ) O(n^2) O(n2) 看数据,有可能因为常数部分会被卡超时,如果数据较为平均则能卡过去
#include
using namespace std;
const int maxn=100010;
int n, s[maxn], a[maxn], curr, maxL, ans;
struct Node{
int i, v;
bool operator < (const Node& a)const{
return v < a.v;
}
}node,maxR;
priority_queueqR;
priority_queueqL;
int main(){
scanf("%d", &n);
for(int i = 1; i <= n; i++){
scanf("%d", &s[i]);
}
for(int i = 1; i <= n; i++){
scanf("%d",&a[i]);
}
for(int i = 1; i <= n; i++){
node.i = i;
node.v = 2 * s[i] + a[i];
qR.push(node);
}
for(int x = 1; x <= n; x++){
maxL = maxR.v = 0;
if(!qL.empty()){
maxL = qL.top();
}
while(!qR.empty() && qR.top().i <= curr){
qR.pop();
}
if(!qR.empty()){
maxR=qR.top();
}
if(maxL < maxR.v - 2 * s[curr]){//当两者相等时取哪边都一样
ans += maxR.v - 2 * s[curr];
for(int k = curr + 1; k < maxR.i; k++){
qL.push(a[k]);
}
curr = maxR.i;
qR.pop();
} else {
ans += maxL;
qL.pop();
}
printf("%d\n",ans);
}
return 0;
}