基于TensorFlow2.x框架开发机器学习
前言
本文主要对机器学习、神经网络介绍;TensorFlow 框架介绍;带大家搭建 TensorFlow 开发环境;TensorFlow 入门与基本运算;最后基于TensorFlow2 实现对服装图像进行分类。
目录
前言
一、机器学习、神经网络简单介绍
1)机器学习简介
2)解决机器学习问题的步骤
3)神经网络剖析
4)训练神经网络
二、TensorFlow 介绍篇
1)什么是TensorFlow?
2)TensorFlow 特点
3)TensorFlow的发展历程
4)TensorFlow1.0 与TensorFlow2.0 对比
5)TensorFlow2.0 框架、特点
6)TensorFlow 是否受欢迎呢?是否被大家所使用?
三、搭建 TensorFlow 开发环境
四、TensorFlow 入门 认识张量
1)创建张量
2)张量维度转换
3)张量运算
五、TensorFlow 实践
对服装图像进行分类
一、Fashion MNIST数据集
二、探索数据
三、预处理数据
四、建立模型
五、训练模型
六、使用训练有素的模型
七、源代码:
本文参考
一、机器学习、神经网络简单介绍
这里先进行简单的介绍,便于大家对TensorFlow理解;
1)机器学习简介
机器学习是指帮助软件在没有明确的程序或规则的情况下执行任务。对于传统计算机编程,程序员会指定计算机应该使用的规则。但是,机器学习需要另一种思维方式。现实中的机器学习对数据分析的注重程度远高于编码。程序员提供一组样本,然后计算机从数据中学习各种模式。我们可以将机器学习视为“使用数据进行编程”。
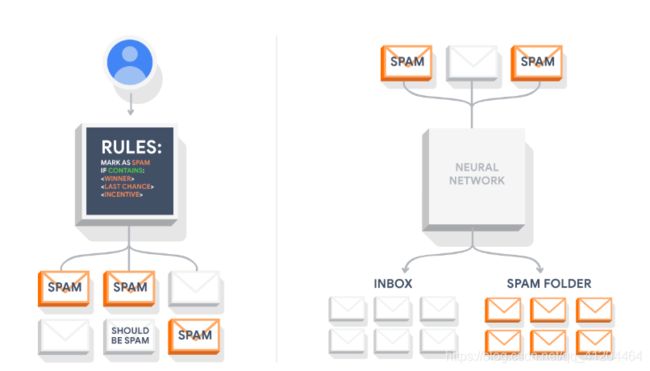
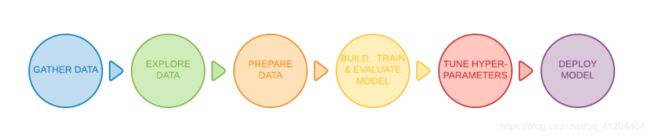
2)解决机器学习问题的步骤
其主要包括六步,分别为:
- 步骤1:收集资料
- 步骤2:浏览数据(同时需要选择模型)
- 步骤3:准备资料
- 步骤4:建立,训练和评估模型
- 步骤5:调整超参数
- 步骤6:部署模型
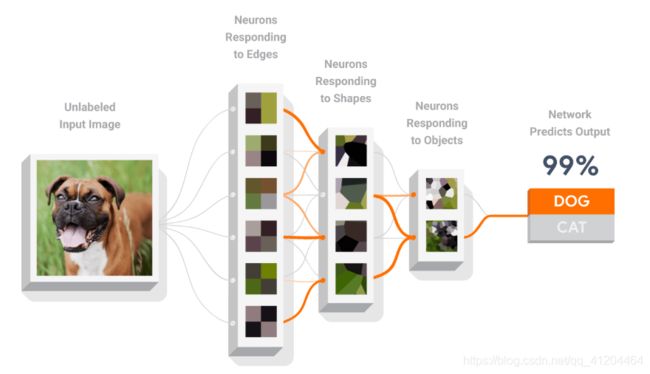
3)神经网络剖析
神经网络是一种可以通过训练来识别各种模式的模型。神经网络由多个层组成,包括输入层和输出层,以及至少一个隐藏层。各层中的神经元会学习越来越抽象的数据表示法。
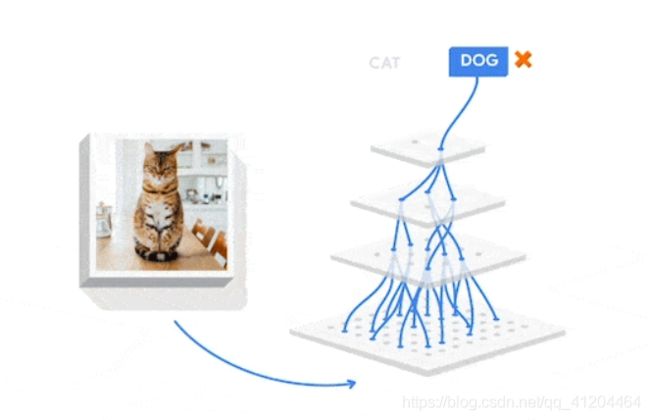
例如,在猫狗分类中,在对一张小狗的图片进行提取特征数据时,在下图中我们看到了检测线条、形状和纹理的神经元。这些表示法(或学习的特征)可以用来对数据进行分类。
输入层:一张小狗的图片
输出层:输出当识别是小狗DOG的把握(99%),当识别是小猫CAT的把握
输入层和输出层之间都是隐藏层;下图中,隐藏层是3层。
4)训练神经网络
神经网络是通过梯度下降法进行训练的。每层的权重都以随机值开始,并且这些权重会随着时间的推移以迭代的方式不断改进,使网络更准确。
我们使用损失函数量化网络的不准确程度,并使用一种名为“反向传播算法”的流程确定每个权重应该增加还是降低以减小损失。
输入一张小猫的图片,识别为小猫CAT时,是正确的; 这时通过“反向传播算法”确定每个权重应该增加,告诉神经网络走这条路是正确的,权重增大后,以后走这边路的可能性会增大,从而减小出现错误的机率;
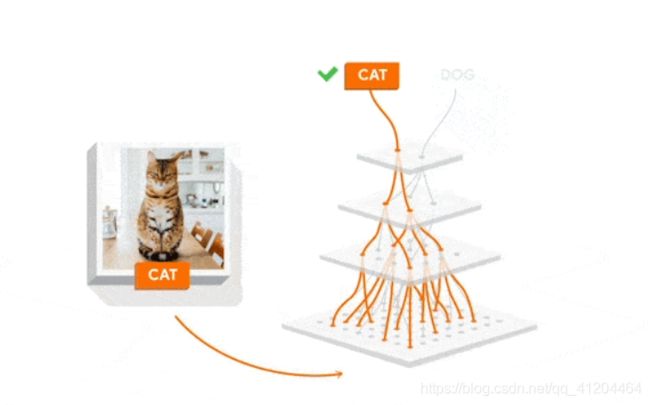
输入一张小猫的图片,识别为小狗DOG时,是错误的;这时通过“反向传播算法”确定每个权重应该降低,告诉神经网络走这条路是错误的,权重降低后,以后走这边路的可能性会减少,从而减小出现错误的机率;(减小损失)
二、TensorFlow 介绍篇
1)什么是TensorFlow?
它是端到端的开源机器学习平台;一个核心开源库,可以帮助我们开发和训练机器学习模型。借助TensorFlow,初学者和专家可以轻松地创建机器学习模型。
我们可以使用 Sequential API 来使用TensorFlow,也可以使用Keras API 调用TensorFlow开源库。
常见问题的解决方案:

https://www.tensorflow.org/overview/?hl=zh_cn
2)TensorFlow 特点
- 轻松地构建模型:可以使用高阶 Keras API 构建和训练模型,该 API 让我们能够轻松地开始使用 TensorFlow 和机器学习。对于大型机器学习训练任务,可以使用 Distribution Strategy API 在不同的硬件配置上进行分布式训练,而无需更改模型定义。
- 可靠地实现机器学习:TensorFlow 都可以助我们轻松地训练和部署模型,支持多种语言和平台。如果需要完整的生产型机器学习流水线,使用 TensorFlow Extended (TFX)。要在移动设备和边缘设备上进行推断,使用 TensorFlow Lite。使用 TensorFlow.js 在 JavaScript 环境中训练和部署模型。
-
具有强大的研究经验:构建和训练先进的模型,并且不会降低速度或性能。借助 Keras Functional API 和 Model Subclassing API 等功能,TensorFlow 可以助我们灵活地创建复杂拓扑并实现相关控制。TensorFlow 还支持强大的附加库和模型生态系统以供我们开展实验,包括 Ragged Tensors、TensorFlow Probability、Tensor2Tensor 和 BERT。
3)TensorFlow的发展历程
2011:DistBelief
2015.11:TensorFlow 0.5.0
2017.02:TensorFlow 1.0
- 高层API,将Keras库整合进其中
- 动态图机制:Eager Execution
- 面向移动智能终端:TensorFlow Lite
- 面向网页前端:TensorFlow.js
- 自动生成计算图:AutoGraph
2019:TensorFlow 2.0
4)TensorFlow1.0 与TensorFlow2.0 对比
从执行机制对比:
TensorFlow1.x ——延迟执行机制(deferred execution)/静态图机制(代码运行效率高,便于优化、程序不够简洁)

TensorFlow2.0 ——动态图机制(Eager Execution)
- 无需首先创建静态图,可以立刻执行计算,并返回结果
- 能够快速的建立和调试模型
- 执行效率不高
a=tf.constant(2,name="input_a")
b=tf.constant(3,name="input_b")
print(a+b)
兼顾易用性和执行效率—— 在程序调试阶段使用动态图,快速建立模型、调试程序;在部署阶段,采用静态图机制,从而提高模型的性能和部署能力
总体对比:
TensorFlow1.x ——重复、冗余的API
- 构建神经网络:tf.slim,tf.layers,tf.contrib.layers,tf.keras
- 混乱,不利于程序共享,维护的成本高
TensorFlow2.0 ——清理 / 整合API
- 清理、整合了重复的API
- 将tf.keras作为构建和训练模型的标准高级API
5)TensorFlow2.0 框架、特点
TensorFlow2.0 架构:
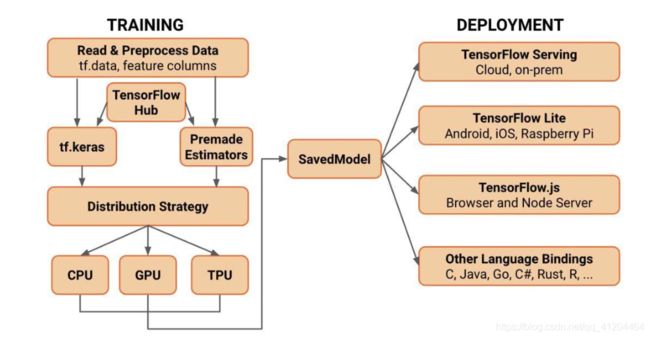
特点:
1、多种环境支持
- 可运行于移动设备、个人计算机、服务器、集群等
- 云端、本地、浏览器、移动设备、嵌入式设备
2、支持分布式模式
- TensorFlow会自动检测GPU和CPU,并充分利用它们并行、分布的执行
3、简洁高效
- 构建、训练、迭代模型:Eager Execution,Keras
- 部署阶段:转化为静态图,提高执行效率。
4、社区支持
6)TensorFlow 是否受欢迎呢?是否被大家所使用?
我们看看下图,使用 TensorFlow 的公司:

不得不说,有这么多巨头公司都使用,说明还是很不错的。
三、搭建 TensorFlow 开发环境
1)Windows系统 之前也写了相关的博客,大家可以参考:
【搭建神经网络开发环境--TensorFlow2框架】Windows系统+ Anaconda+ PyCharm+ Python
2)Linux(Ubuntu系统)
使用 Python 的 pip 软件包管理器安装 TensorFlow;TensorFlow 2 软件包需要使用高于 19.0 的 pip 版本。
# 首先更新pippip install --upgrade pip# 会安装当前最新的CPU和GPU的稳定版本pip install tensorflow
3)TensorFlow docker容器版
TensorFlow Docker 映像已经过配置,可运行 TensorFlow。Docker 容器可在虚拟环境中运行,是设置 GPU 支持的最简单方法
docker pull tensorflow/tensorflow:latest-py3 # 下载最新且稳定的tensorflow镜像docker run -it -p 8888:8888 tensorflow/tensorflow:latest-py3-jupyter # 开始Jupyter服务
四、TensorFlow 入门
前言
Tensorflow的名称直接源自其核心框架Tensor。在Tensorflow中,所有计算都涉及张量。张量是向量代表所有类型数据的n维或矩阵。张量中的所有值都具有具有已知(或部分已知)形状的相同数据类型。数据的形状是矩阵或数组的维数。
TensorFlow中通常使用 张量 (Tensor) 作为的计算对象,最重要的数据单元,它是一个形状为一维或多维数组组成的数值的集合;张量 (Tensor)可以高速运行于GPU和TPU之上,实现神经网络和深度学习中的复杂算法。
认识张量
张量是n维特征向量(即数组)的集合。例如,如果我们有一个2x3矩阵,其值从1到6,则可以这样写:
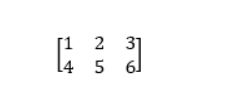
TensorFlow将该矩阵表示为:
[[1,2,3],
[4、5、6]如果创建一个值从1到8的三维矩阵,TensorFlow将该矩阵表示为:
[[[1,2],
[[3,4],
[[5,6],
[[7,8]]
1)创建张量
张量由Tensor类实现,每个张量都是一个Tensor对象; 使用 tf.constant()函数 来创建张量,即:
tf.constant(value, dtype, shape)
- value:数字/Python列表/NumPy数组 (value参数可以是一个常量值,或者一个dtype类型的值列表,或字符串)
- dtype: 元素的数据类型 (如果参数dtype没有指定,那么会从value中自动推断出dtype的值)
- shape: 张量的形状 (shape参数是可选的。如果存在该参数,它会指明生成的张量的维度。如果不存在,则使用value的shape。)
例子1 :使用Python列表来作为参数,创建张量
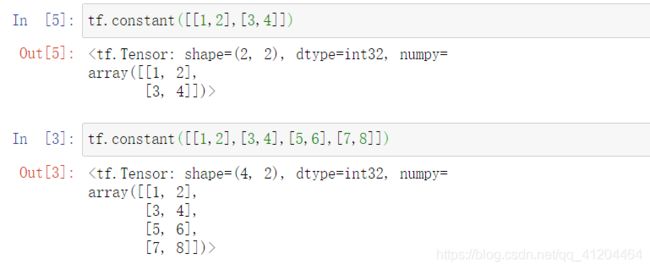
例子2:使用数字来作为参数,创建张量
在常数中,整数默认是:int32 类型 ,浮点数默认是:float32 类型.
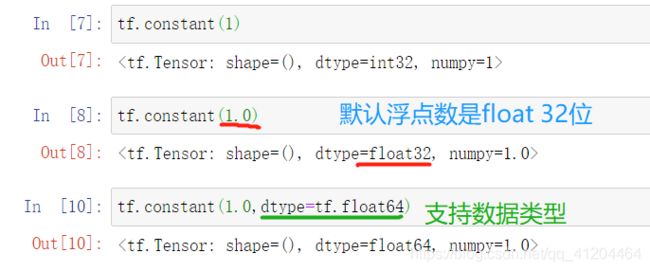
我们可以指出该常数的数据类型,建议指定比默认类型要大,避免出现数据溢出问题;比如一个整数,默认是int32,使用4字节,共4 * 8 =32位来存储,可以指定为float32的类型存储,毕竟float32的存储空间比int32大,就是有点浪费空间,哈哈;
如果一个浮点数x,指定使用int32,这里int32的存储空间无法把x的数据完全存储,导致部分数据溢出。
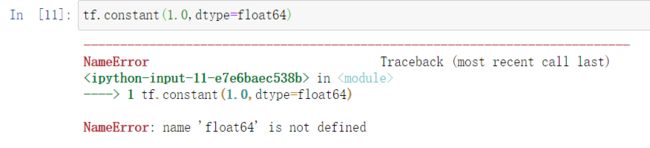
注意:在指定类型中需要使用tensorflow中的类型,例如:tf.int32、tf.float32、tf.float64 等,而不是写dtype=float64 (错误)
小结:数据类型
例子3:使用NumPy数组来作为参数,创建张量
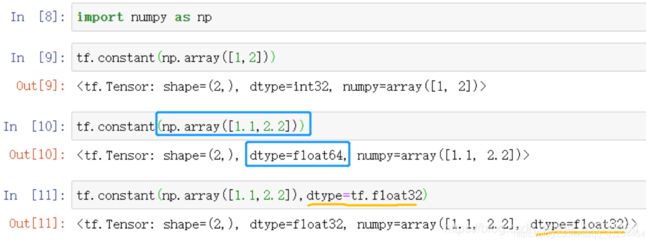
蓝色框框:numpy创建浮点数数组时,默认的浮点型是64位浮点数。当使用NumPy数组创建张量时,TensorFlow会接受数组元素的数据类型,使用64位浮点数保存数据。
橙色线:指明数据类型为32位浮点数
例子4:使用布尔型来作为参数,创建张量
布尔型转换为整型,0: False,1 : True

整型变量转换为布尔型,将非 0 数字都视为 True
例子5:使用字符串来作为参数,创建张量

b:表示这是一个字节串。在Python3中,字符串默认是Unicode编码,因此要转成字节串,就在原来的字符串前面加上一个b
例子6:创建全1张量
tf.ones( shape, dtype= tf.float32 )
默认为32位浮点数
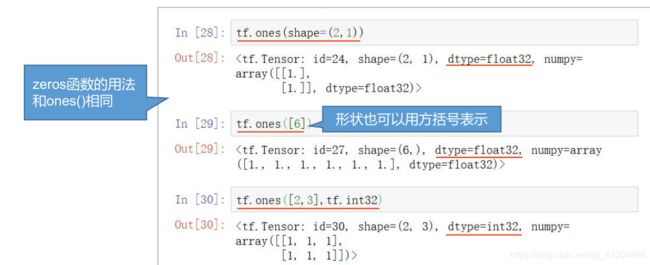
例子7:创建全0张量
tf.zeros( shape, dtype = tf.float32 )
小结 :创建张量

Tensor对象的属性 ——shape、dtype
获得Tensor对象的形状、元素总数和维度

张量和NumPy数组
- 在TensorFlow中,所有的运算都是在张量之间进行的;NumPy数组仅仅是作为输入和输出来使用。
- 张量可以运行于CPU,也可以运行于GPU和TPU,而NumPy数组只能够在CPU中运行;在CPU环境下,张量和 NumPy数组是共享同一段内存的。
- 张量是Tensor Flow中多维数组的载体,用 Tensor对象实现。
- 多维张量在内存中是以一维数组的方式连续存储的。
2)张量维度转换
张量的存储和视图:
多维张量在物理上以一维的方式连续存储;通过定义维度和形状,在逻辑上把它理解为多维张量。
物理组织:实际存储的方式。 逻辑组织:我们定义的格式,看到的视图。当对多维张量进行维度变换时,只是改变了逻辑上索引的方式,没有改变内存中的存储方式。

张量的形状;
张量形状表示每个轴或尺寸上的元素大小。
例如,如果张量的形状为[2,3,4],则表示该张量轴= [0,1,2]且轴上有2个元素= 0,轴上有3个元素= 2和4个元素在轴上= 3。
改变张量的形状:
函数如下,参数解析 tensor:需要改变形状的张量; shape:改变后的形状
tf.reshape (tensor, shape)
备注:tf.reshape函数没有封装到Tensor对象中,前缀是tf,而不是张量对象。
例子1:把一维张量a,转换为三维张量
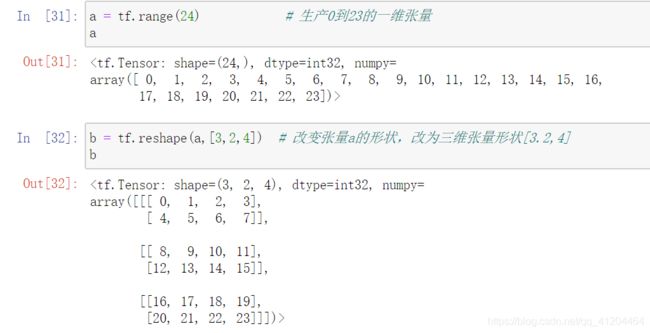
大家可以看下,转换前后张量的总个数是不变的,转换前是一维的24个,转换后还是 3*2*4 = 24个;张量在物理上以一维的方式连续存储的,所以改变张量的形状,也是不改变内存中的存储方式的。
改变形状时,还要计算形状是否合理,是否有指定一定的维度,其他维度自动补全呢?
有的,shape参数=-1:自动推导出长度
例子2:一维张量a,转换为二维张量 3*8的形状
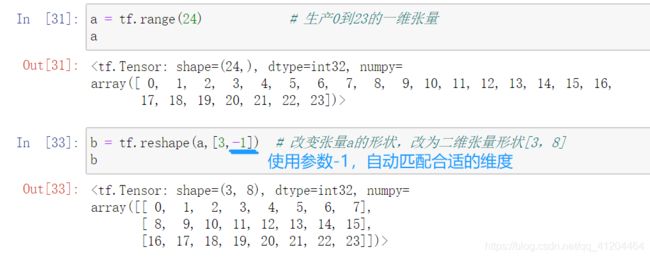
多维张量的轴 :张量的维度
张量轴描述张量的尺寸,例如,如果张量为4维,则表示其轴= [0,1,2,3]
张量的设定维数为n。张量的轴将是轴= [0,1,2,…,n-1]。
张量中的轴的概念和用法,和NumPy数组是一样的;一维张量有一个轴,索引为0;二维张量有二个轴,索引分别为0,1;三维张量有三个轴,索引分别为0,1,2;有时在多维张量中,轴可以是负数,表示从后向前索引。
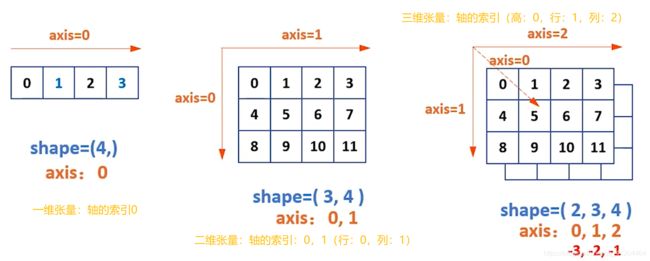
张量轴与形状的关系
假设张量形状为:形状 shape = [x,y,z,…],其轴= [0,1,2,…]

了解轴与形状之间的关系,我们将可以在一些张量流函数中了解aixs参数。
3)张量运算
1)常用的 加 减 乘 除 运算
| 算术操作(函数) | 描 述 |
| tf.add(x, y) | 将张量x 和 张量y逐元素相加 |
| tf.subtract(x, y) | 将张量x 和 张量y逐元素相减 |
| tf.multiply(x, y) | 将张量x 和 张量y逐元素相乘 |
| tf.divide(x, y) | 将张量x 和 张量y逐元素相除 |
上面的运算中,参数分别是参与运算的两个张量;比如:张量a = [1,2,3] ,张量b = [4,5,6]
张量相加:

张量a = [1,2,3] ,张量b = [4,5,6]逐个元素相加,对应:1 + 4 = 5; 2 + 5 = 7; 3 + 6 = 9; 相加结果张量[5,7,9]
张量相减:
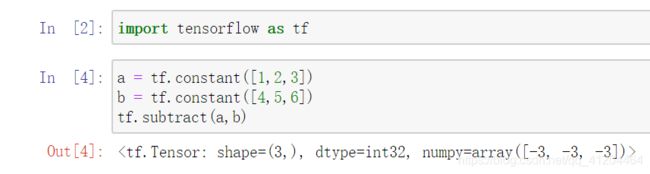
张量a = [1,2,3] ,张量b = [4,5,6]逐个元素相减,对应:1 - 4 = -3; 2 - 5 = -3; 3 - 6 = -3; 相减结果张量[-3,-3,-3]
张量相乘:
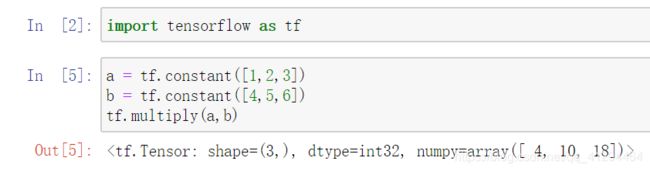
张量a = [1,2,3] ,张量b = [4,5,6]逐个元素相乘,对应:1 x 4 = 4; 2 x 5 = 10; 3 x 6 = 18; 相乘结果张量[4,10,18]
张量相除:

张量a = [1,2,3] ,张量b = [4,5,6]逐个元素相除,对应:1 ÷ 4 = 0.25; 2 ÷ 5 = 0.4; 3 ÷ 6 = 0.5; 相除结果张量[0.25,0.4,0.5]
2)幂指对数运算
| 算术操作 (函数) | 描 述 |
| tf.pow(x, y) | 对张量x 求 张量 y的幂次方 |
| tf.square(x) | 对张量x 逐元素求计算平方 |
| tf.sqrt(x) | 对张量x 逐元素开平方根 |
| tf.exp(x) | 计算e的张量x 次方 |
| tf.math.log(x) | 计算自然对数,底数为e |
【一维张量幂运算】
例如,张量a = [1,2,3],使用tf.pow(a, 3) 求a的3的幂次方,即:对a张量中的每个元素计算了3次方

张量a = [1,2,3] ,逐个元素求3次方,对应:[ 1³ ,2³, 3³ ],即:[ 1, 8, 27]
【二维张量幂运算】
例如,张量a = [ [1,2,3],[4,5,6] ],使用tf.pow(a, 3) 求a的3的幂次方,

张量a = [ [1,2,3],[4,5,6] ] ,逐个元素求3次方,对应:[ [ 1³ ,2³, 3³ ],[ 4³ ,5³, 6³ ] ] 即:[ [ 1, 8, 27], [ 64, 125, 216] ]
例如,张量a = [ [1,2,3],[4,5,6] ],张量b =[ [2,2,2],[3,3,3] ],使用tf.pow(a, b)

张量a = [ [1,2,3],[4,5,6] ] ,逐个元素求张量b中对应元素的次方,对应:[ [ 1²,2², 3² ],[ 4³ ,5³, 6³ ] ] ,即:[[ 1, 4, 9], [ 64, 125, 216]]
3)三角函数和反三角函数运算
| 函数 | 描 述 |
| tf.cos(x) | 三角函数cos |
| tf.sin(x) | 三角函数sin |
| tf.tan(x) | 三角函数tan |
| tf.acos(x) | 反三角函数arccos |
| tf.asin(x) | 反三角函数arcsin |
| tf.atan(x) | 反三角函数arctan |
4)自然指数和自然对数运算
注意:TensorFlow中只有以e为底的自然对数,没有提供以其他数值为底的对数运算函数;而且张量的元素必须是浮点数类型。
自然指数:tf.exp( )

自然对数运算:tf.math.log( ),自然对数在math模块中

5)其他运算

大家可以了解下;
6)重载运算符(针对TensorFlow的张量运算)
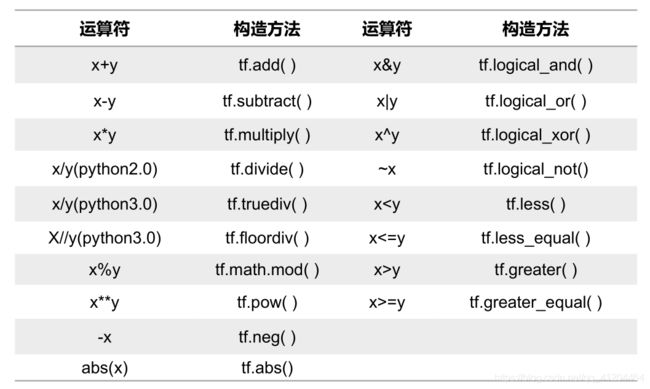
重装后的运算符,还是挺方便的;
例子1:+ 运算(加法)

例子2:* 运算(乘法)

例子3:> 运算(比较运算——大于)

不同维度运算
例子1:一维张量+二维张量
注意:两个张量最后一个维度的长度必须相等
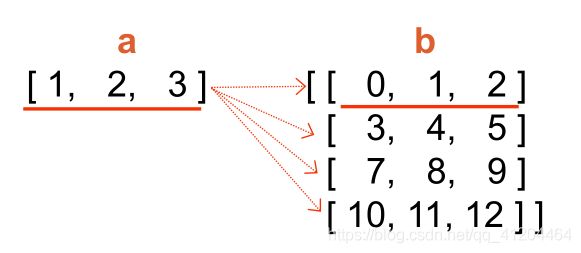
执行加法运算:

例子2:一维张量+三维张量
注意:两个张量最后一个维度的长度必须相等
一维张量a [1,2,3],和三维张量b [ [[1,2,3],[4,5,6]] , [[7,8,9],[10,11,12]] ] ,它们一个维度的长度是相等的,都是3,可以进行运算
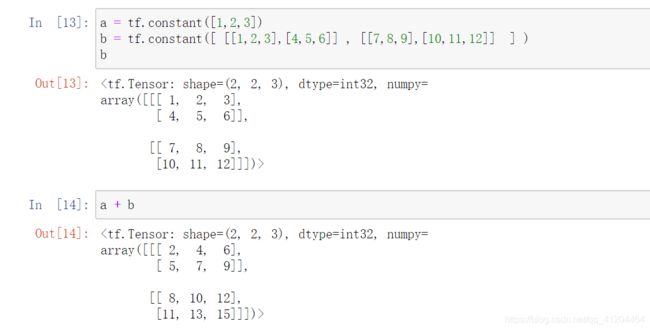
以下是错误示范,在不同维度运算中,两个张量最后一个维度的长度不是相等
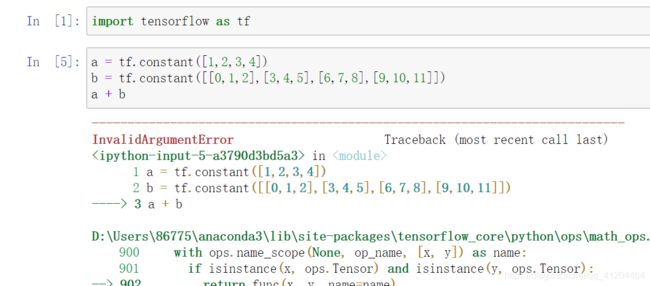
张量a 是一维的,其形状是(4,);张量b 是二维的,它的形状是(4,3);它们最后一个维度的长度不是相等的,即4!=3
五、TensorFlow 实践
这里之前写了些边关于Tensor flow实践的文章,大家可以看一下:
基于神经网络——鸢尾花识别(Iris)
【GitHub开源项目实践】人脸口罩检测
搭建神经网络---可视化 网站
下面介绍一个使用Tensor flow的实践项目:
对服装图像进行分类
前言
基于TensorFlow2.x的框架,使用PYthon编程语言,实现对服装图像进行分类。
思路流程:
- 导入 Fashion MNIST数据
- 集探索数据
- 预处理数据
- 建立模型(搭建神经网络结构、编译模型)
- 训练模型(把数据输入模型、评估准确性、作出预测、验证预测)
- 使用训练有素的模型
一、Fashion MNIST数据集
Fashion MNIST数据集包括一些运动鞋和衬衫等衣物;我们从下图中先看一下:

给不同类别的 运动鞋和衬衫等衣物,进行索引分类;每个图像都映射到一个标签。

不同的类别,对应其索引,先把它们存储在此处以供以后在绘制图像时使用:
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',
'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
二、探索数据
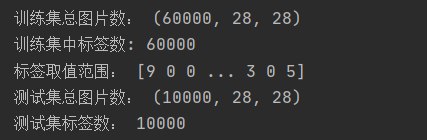
在训练模型之前,我们可以探索数据集的格式。比如:训练集中有60,000张图像,每个图像表示为28 x 28像素。训练集中有60,000个标签;每个标签都是0到9之间的整数。
测试集中有10,000张图像。同样,每个图像都表示为28 x 28像素。测试集包含10,000个图像标签。
探索数据代码:

运行结果:
三、预处理数据
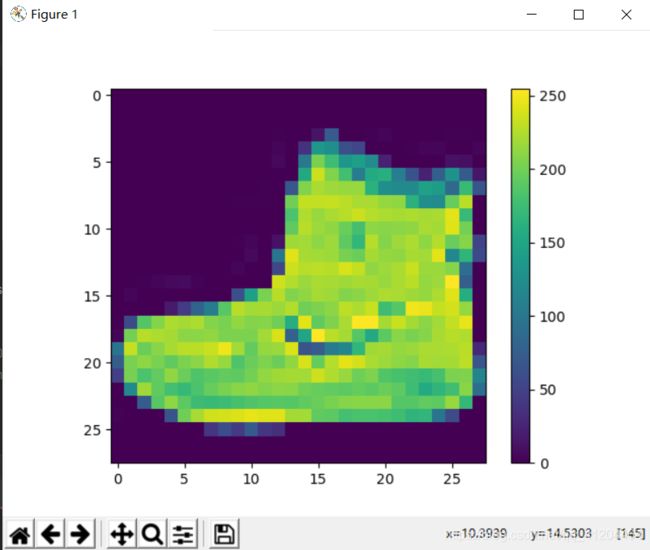
在训练网络之前,必须对数据进行预处理。如果检查训练集中的第一张图像,将看到像素值落在0到255的范围内:
plt.figure()
plt.imshow(train_images[0])
plt.colorbar()
plt.grid(False)
plt.show()查看第一张图像(像素值落在0到255),运行结果:
将这些值缩放到0到1的范围,然后再将其输入神经网络模型。为此,将值除以255。以相同的方式预处理训练集和测试集非常重要:
train_images = train_images / 255.0
test_images = test_images / 255.0为了验证数据的格式正确,并且已经准备好构建和训练网络,让我们显示训练集中的前25张图像,并在每张图像下方显示类别名称。
plt.figure(figsize=(10,10))
for i in range(25):
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(train_images[i], cmap=plt.cm.binary)
plt.xlabel(class_names[train_labels[i]])
plt.show()运行结果:可以看到 训练集中的前25张图像

四、建立模型
建立神经网络需要配置模型的各层(图层),然后编译模型。
1)搭建神经网络结构
神经网络的基本组成部分是图层 。图层(神经网络的结构)将输入到图层中的数据进行提取特征。
深度学习的大部分内容是将简单的层链接在一起。大多数层(例如tf.keras.layers.Dense )具有在训练期间学习的参数。
model = keras.Sequential([
keras.layers.Flatten(input_shape=(28, 28)),
keras.layers.Dense(128, activation='relu'),
keras.layers.Dense(10)
])此网络的第一层tf.keras.layers.Flatten将图像的格式从二维数组(28 x 28像素)转换为一维数组(28 * 28 = 784像素)。可以将这一层看作是堆叠图像中的像素行并将它们排成一行。该层没有学习参数。它只会重新格式化数据。
像素展平后,网络由两个tf.keras.layers.Dense层序列组成。这些是紧密连接或完全连接的神经层。第一Dense层具有128个节点(或神经元)。第二层(也是最后一层)返回长度为10的logits数组。每个节点包含一个得分,该得分指示当前图像属于10个类之一。
2)编译模型
在准备训练模型之前,需要进行一些其他设置。这些是在模型的编译步骤中添加的:
- 损失函数 -衡量训练期间模型的准确性。希望最小化此功能,以在正确的方向上“引导”模型。
- 优化器 -这是基于模型看到的数据及其损失函数来更新模型的方式。
- 指标 -用于监视培训和测试步骤。以下示例使用precision ,即正确分类的图像比例。
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
五、训练模型
训练神经网络模型需要执行以下步骤:
- 将训练数据输入模型。在此示例中,训练数据在
train_images和train_labels数组中。 - 训练过程中该模型会学习关联图像和标签。(找到正确的对应关系,比如a图片,对应a标签,而不是对应c标签)
- 使用训练好后的模型对测试集进行预测。(在本示例中为
test_images数组) - 验证预测是否与
test_labels数组中的标签匹配。
1)把数据输入模型进行训练
要开始训练,请调用model.fit方法:
model.fit(train_images, train_labels, epochs=10)这里训练过程中会迭代10次;
第1次训练:

第2次训练:
..........................3、4、5、6、7、8、9...................训练
第10次训练:
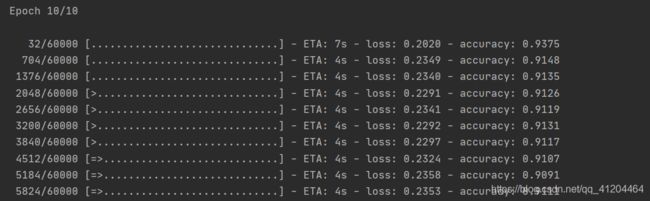
模型训练时,会显示损失和准确性指标。该模型在训练数据上达到约0.91(或91%)的精度。
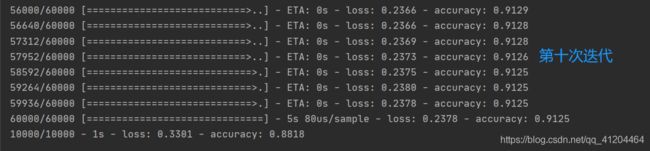
2)评估准确性
比较模型在测试数据集上的表现:
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)
print('\nTest accuracy:', test_acc)运行结果:

测试数据集的准确性略低于训练数据集的准确性。训练准确性和测试准确性之间的差距代表过度拟合 。当机器学习模型在新的,以前看不见的输入上的表现比训练数据上的表现差时,就会发生过度拟合。过度拟合的模型“记忆”训练数据集中的噪声和细节,从而对新数据的模型性能产生负面影响。
解决方案:请参见以下内容:(有兴趣可以看一下)
- 证明过度拟合
- 防止过度拟合的策略
3)作出预测
通过训练模型,可以使用它来预测某些图像。模型的线性输出logits 。附加一个softmax层,以将logit转换为更容易解释的概率。
probability_model = tf.keras.Sequential([model, tf.keras.layers.Softmax()])
predictions = probability_model.predict(test_images)
在这里,模型已经预测了测试集中每个图像的标签。让我们看一下第一个预测:
predictions[0]运行结果:

预测是由10个数字组成的数组。它们代表模型对图像对应于10种不同服装中的每一种的“置信度”。可以看到哪个标签的置信度最高: np.argmax(predictions[0])
输出是 9
因此,模型最有把握认为该图像是短靴/脚踝靴(class_names[9] );检查测试标签表明此分类是正确的:test_labels[0]
输出也是 9
4)验证预测
通过训练模型,可以使用它来预测某些图像。让我们看一下第0张图像,预测和预测数组。正确的预测标签为蓝色,错误的预测标签为红色。该数字给出了预测标签的百分比(满分为100)。
正确的预测标签为蓝色:
i = 0
plt.figure(figsize=(6,3))
plt.subplot(1,2,1)
plot_image(i, predictions[i], test_labels, test_images)
plt.subplot(1,2,2)
plot_value_array(i, predictions[i], test_labels)
plt.show()运行结果:

错误的预测标签为红色:
i = 12
plt.figure(figsize=(6,3))
plt.subplot(1,2,1)
plot_image(i, predictions[i], test_labels, test_images)
plt.subplot(1,2,2)
plot_value_array(i, predictions[i], test_labels)
plt.show()运行结果:
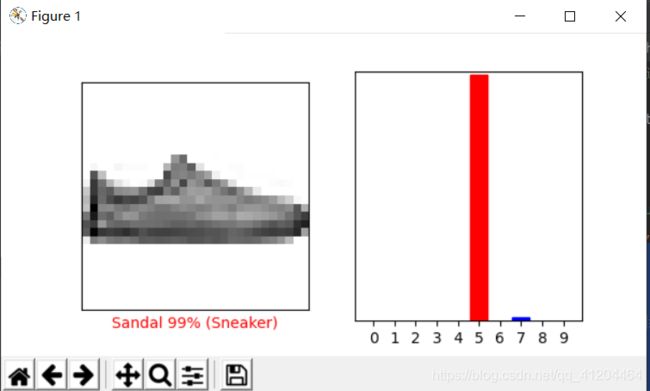
绘制一些带有预测的图像:
# 绘制一些带有预测的图像
# 绘制前X张测试图像,它们的预测标签和真实标签。
# 将正确的预测颜色设置为蓝色,将不正确的预测颜色设置为红色。
num_rows = 5
num_cols = 3
num_images = num_rows*num_cols
plt.figure(figsize=(2*2*num_cols, 2*num_rows))
for i in range(num_images):
plt.subplot(num_rows, 2*num_cols, 2*i+1)
plot_image(i, predictions[i], test_labels, test_images)
plt.subplot(num_rows, 2*num_cols, 2*i+2)
plot_value_array(i, predictions[i], test_labels)
plt.tight_layout()
plt.show()
六、使用训练有素的模型
使用经过训练的模型对单个图像进行预测;先挑一张图片,比如test_images[0],它是这样的:
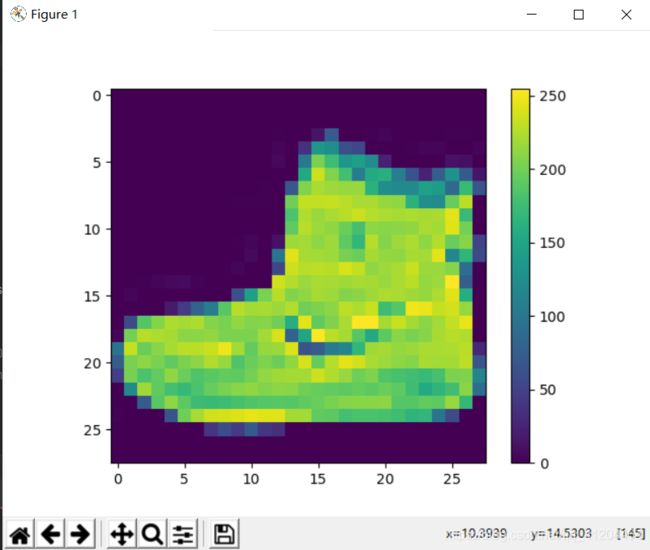
它是短靴/脚踝靴,对应标签是9。下面使用模型进行预测:
# 【6 使用训练有素的模型】
# 使用经过训练的模型对单个图像进行预测。
# 从测试数据集中获取图像。
img = test_images[0]
# 将图像添加到唯一的批处理
img = (np.expand_dims(img,0))
# 为该图像预测正确的标签:
predictions_single = probability_model.predict(img)
print("输出每一个标签的把握:", predictions_single) # 一共10个标签,索引从0,1,2到9
plot_value_array(1, predictions_single[0], test_labels)
_ = plt.xticks(range(10), class_names, rotation=45)
# keras.Model.predict返回一个列表列表-数据批次中每个图像的一个列表。批量获取我们(仅)图像的预测
print("模型预测的结果:", np.argmax(predictions_single[0]))运行结果:

我们可以看到有99.6%的把握认为是标签9,预测正确了,能分辨出是短靴/脚踝靴(标签是9)。
七、源代码:
# 本程序基于TensorFlow训练了一个神经网络模型来对运动鞋和衬衫等衣物的图像进行分类。
# 使用tf.keras (高级API)在TensorFlow中构建和训练模型。
# TensorFlow and tf.keras
import tensorflow as tf
from tensorflow import keras
# Helper libraries
import numpy as np
import matplotlib.pyplot as plt
# 查看当前tensorflow版本
print("当前tensorflow版本", tf.__version__)
# 【1 导入Fashion MNIST数据集】
'''
加载数据集将返回四个NumPy数组:
train_images和train_labels数组是训练集 ,即模型用来学习的数据。
针对测试集 , test_images和test_labels数组对模型进行测试
'''
'''
图像是28x28 NumPy数组,像素值范围是0到255。 标签是整数数组,范围是0到9。这些对应于图像表示的衣服类别 :
标签 类
0 T恤
1 裤子
2 套衫/卫衣
3 连衣裙
4 外衣/外套
5 凉鞋
6 衬衫
7 运动鞋
8 袋子
9 短靴/脚踝靴
'''
fashion_mnist = keras.datasets.fashion_mnist
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()
# 每个图像都映射到一个标签
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',
'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
# 【2 探索数据】
# 在训练模型之前,让我们探索数据集的格式。下图显示了训练集中有60,000张图像,每个图像表示为28 x 28像素
print("训练集总图片数:", train_images.shape)
# 训练集中有60,000个标签
print("训练集中标签数:", len(train_labels))
# 每个标签都是0到9之间的整数
print("标签取值:", train_labels)
# 测试集中有10,000张图像。同样,每个图像都表示为28 x 28像素
print("测试集总图片数:", test_images.shape)
# 测试集包含10,000个图像标签
print("测试集标签数:", len(test_labels))
# 【3 预处理数据】
# 在训练网络之前,必须对数据进行预处理。如果检查训练集中的第一张图像,将看到像素值落在0到255的范围内
plt.figure()
plt.imshow(train_images[0])
plt.colorbar()
plt.grid(False)
plt.show()
# 将这些值缩放到0到1的范围,然后再将其输入神经网络模型。为此,将值除以255。以相同的方式预处理训练集和测试集非常重要:
train_images = train_images / 255.0
test_images = test_images / 255.0
#为了验证数据的格式正确,并且已经准备好构建和训练网络,让我们显示训练集中的前25张图像,并在每张图像下方显示班级名称。
plt.figure(figsize=(10,10))
for i in range(25):
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(train_images[i], cmap=plt.cm.binary)
plt.xlabel(class_names[train_labels[i]])
plt.show()
# 【4 建立模型】
# 建立神经网络需要配置模型的各层,然后编译模型
# 搭建神经网络结构 神经网络的基本组成部分是层 。图层(神经网络结构)从输入到其中的数据中提取表示
# 深度学习的大部分内容是将简单的层链接在一起。大多数层(例如tf.keras.layers.Dense )具有在训练期间学习的参数。
model = keras.Sequential([
keras.layers.Flatten(input_shape=(28, 28)),
keras.layers.Dense(128, activation='relu'),
keras.layers.Dense(10)
])
'''
编译模型
在准备训练模型之前,需要进行一些其他设置。这些是在模型的编译步骤中添加的:
损失函数 -衡量训练期间模型的准确性。您希望最小化此功能,以在正确的方向上“引导”模型。
优化器 -这是基于模型看到的数据及其损失函数来更新模型的方式。
指标 -用于监视培训和测试步骤。以下示例使用precision ,即正确分类的图像比例。
'''
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
# 【5 训练模型】
'''
训练神经网络模型需要执行以下步骤:
1.将训练数据输入模型。在此示例中,训练数据在train_images和train_labels数组中。
2.该模型学习关联图像和标签。
3.要求模型对测试集进行预测(在本示例中为test_images数组)。
4.验证预测是否与test_labels数组中的标签匹配。
'''
# 要开始训练,请调用model.fit方法,之所以这么称呼是因为它使模型“适合”训练数据:
model.fit(train_images, train_labels, epochs=10)
# 比较模型在测试数据集上的表现
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)
print('\nTest accuracy:', test_acc)
# 作出预测 通过训练模型,您可以使用它来预测某些图像。模型的线性输出logits 。附加一个softmax层,以将logit转换为更容易解释的概率。
probability_model = tf.keras.Sequential([model, tf.keras.layers.Softmax()])
predictions = probability_model.predict(test_images)
print(predictions[0])
print(np.argmax(predictions[0]))
print(test_labels[0])
# 以图形方式查看完整的10个类预测。
def plot_image(i, predictions_array, true_label, img):
true_label, img = true_label[i], img[i]
plt.grid(False)
plt.xticks([])
plt.yticks([])
plt.imshow(img, cmap=plt.cm.binary)
predicted_label = np.argmax(predictions_array)
if predicted_label == true_label:
color = 'blue'
else:
color = 'red'
plt.xlabel("{} {:2.0f}% ({})".format(class_names[predicted_label],
100*np.max(predictions_array),
class_names[true_label]),
color=color)
def plot_value_array(i, predictions_array, true_label):
true_label = true_label[i]
plt.grid(False)
plt.xticks(range(10))
plt.yticks([])
thisplot = plt.bar(range(10), predictions_array, color="#777777")
plt.ylim([0, 1])
predicted_label = np.argmax(predictions_array)
thisplot[predicted_label].set_color('red')
thisplot[true_label].set_color('blue')
'''验证预测
通过训练模型,您可以使用它来预测某些图像。
让我们看一下第0张图像,预测和预测数组。正确的预测标签为蓝色,错误的预测标签为红色。该数字给出了预测标签的百分比(满分为100)。'''
i = 0
plt.figure(figsize=(6,3))
plt.subplot(1,2,1)
plot_image(i, predictions[i], test_labels, test_images)
plt.subplot(1,2,2)
plot_value_array(i, predictions[i], test_labels)
plt.show()
i = 12
plt.figure(figsize=(6,3))
plt.subplot(1,2,1)
plot_image(i, predictions[i], test_labels, test_images)
plt.subplot(1,2,2)
plot_value_array(i, predictions[i], test_labels)
plt.show()
# 绘制一些带有预测的图像
# 绘制前X张测试图像,它们的预测标签和真实标签。
# 将正确的预测颜色设置为蓝色,将不正确的预测颜色设置为红色。
num_rows = 5
num_cols = 3
num_images = num_rows*num_cols
plt.figure(figsize=(2*2*num_cols, 2*num_rows))
for i in range(num_images):
plt.subplot(num_rows, 2*num_cols, 2*i+1)
plot_image(i, predictions[i], test_labels, test_images)
plt.subplot(num_rows, 2*num_cols, 2*i+2)
plot_value_array(i, predictions[i], test_labels)
plt.tight_layout()
plt.show()
# 【6 使用训练有素的模型】
# 使用经过训练的模型对单个图像进行预测。
# 从测试数据集中获取图像。
img = test_images[0]
# 将图像添加到唯一的批处理
img = (np.expand_dims(img,0))
# 为该图像预测正确的标签:
predictions_single = probability_model.predict(img)
print("输出每一个标签的把握:", predictions_single) # 一共10个标签,索引从0,1,2到9
plot_value_array(1, predictions_single[0], test_labels)
_ = plt.xticks(range(10), class_names, rotation=45)
# keras.Model.predict返回一个列表列表-数据批次中每个图像的一个列表。批量获取我们(仅)图像的预测
print("模型预测的结果:", np.argmax(predictions_single[0]))
希望对你有帮助;
本文参考:
Tensorflow 官网:https://www.tensorflow.org/
北京大学 课程“人工智能实践:Tensorflow笔记”;
西安科技大学 课程“神经网络与深度学习——Tensorflow2.0实践”;