python数据抓取之pyquery包
最近由于公司业务上的需求,要网络采集一些数据,并格式化以供应用的调取,前期想到用正则表达式来对网页格式串进行过滤和抓取,在进行了一系列尝试之后放弃,
原因是太繁琐了,而且对于每种网页都需要写特定的表达式,不可通用。
后面在查找相关资料时,发现python也提供一个类似jquery的包,叫做pyquery,可用以进行网络抓取,遂安装研究了一下,发现确实挺好用,不用写复杂的表达式即可
对数据进行抓取和过滤。
下面就以一个网页为例,来抓取指定格式的数据,并记录过程。
http://yunvs.com/list/mai_1.html
我要抓取这个网页上的数据,如下图:
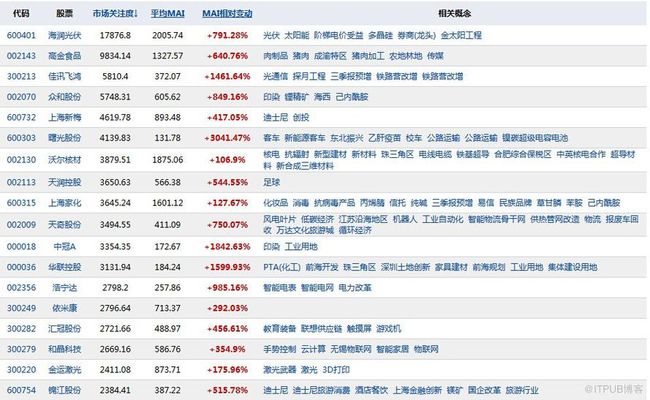
我现在需要抓取股票与概念的关系,以便应用可以方便的通过股票查找其所属的概念,也可以通过热点概念定位相关股票。
那么,应用所需要的数据格式应该是这样的:
股票代码 股票名称 概念名称
002011 盾安环境 多晶硅
002011 盾安环境 分布式能源
002011 盾安环境 核电
002011 盾安环境 核电通风与空气处
002011 盾安环境 太阳能
002011 盾安环境 低碳经济
002011 盾安环境 珠港澳大桥概念
002011 盾安环境 地热
002011 盾安环境 地热能
002011 盾安环境 供热管网改造
002011 盾安环境 疫苗储存
002011 盾安环境 干热岩
但是从网页上我们可以看到,数据是以行的形式来展现的,单只股票后面跟了多个概念,且概念与概念之间以空格为分隔符,所以我们不仅仅要对数据进行抓取,同时还要对其格式进行处理。
下面,我们就通过python的第三方扩展包pyquery来对此网页进行抓取。
1.安装pyquery包
具体的安装过程就不在这里详述了,python的包安装可以通过一个工具叫做easy_install来进行安装和管理,大家百度一下即可得到相关资料。
pyquery包解析html以来lxml包,所以这里要安装pyquery和lxml两个包才可使用pyquery.
pyquery的官网地址: ht tp://pythonhosted.org//pyquery/api.htm l ,上面有详细的每个api的使用方法
2.导入pyquery包
from pyquery import PyQuery as pq
from lxml import etree
3.加载需要解析的数据源
v_source=pq("hello") ---直接加载一个html串
v_source=pq(filename=path_to_html_file) ---加载位于指定路径下的html文件
v_source=pq(url='http://yunvs.com/list/mai_1.html') ---加载url地址直接进行解析
在这里我们就直接使用第三种方式,直接加载网页来进行数据抓取,这样显得更直观和实用。
4.分析要解析的html网页代码
以 http://yunvs.com/list/mai_1.html 为例,我们要抓取股票和概念的数据,那么查看其网页源码,将要解析的代码段摘出来,如下:
可以看到,单只股票的数据都是包含在一个大的 tr标签里面,那么我们第一步过滤就是将网页里面所有的tr段截取出来。
第一步过滤可以这样写:
v_source=pq(url='http://yunvs.com/list/mai_1.html')
v_source('tr') ----这里就是将所有以tr打头的html段过滤出来
想测试的话,可以用以下的语句来输出结果。
for data in v_source('tr'):
print pq(data).html() ---直接输出截取串的html对象,看着更加直观
输出如下:
PS:如果报错UnicodeEncodeError: 'gbk' codec can't encode character,则在程序头部加入字符集支持 #coding=utf-8
基本上我们需要的核心块都被抓取出来了
我们也可以以text文本的方式输出,这样就去掉了html标记
结果如下:
可以看到,我们需要的数据以行记录的形式已经抓取下来了。
如果我们想获取每一行的第一个记录应该如何得到呢?
这里就要分析一下代码了,还是以这段代码为例:
在最外面的tr段中,包含了6个小的td段,我们需要的数据都内嵌在这6个小的td段中,那么我们如果想调出单个td段的对象,可用如下代码测试:
截取一段输出如下:
600315 上海家化 3645.76 1602.69 +127.48% 化妆品 消毒 抗病毒产品 丙烯腈 信托 纯碱 三季报预增 易信 民族品牌 草甘膦 苯胺 己内酰胺
600315 ----eq(0) 组内第一个元素
上海家化 ---eq(1) 组内第二个元素
3645.76 ----eq(2) 组内第三个元素
1602.69 ----eq(3) 组内第四个元素
+127.48% ----eq(4) 组内第五个元素
化妆品 消毒 抗病毒产品 丙烯腈 信托 纯碱 三季报预增 易信 民族品牌 草甘膦 苯胺 己内酰胺 ---组内第六个元素
以上抓取代码解释如下:
pq(data).find('td') 意思是对第一次过滤的 v_source('tr')代码再次在内部进行二次查找,过滤'td'打头的段,可以看到一共有5个。
len(data) 输出代码里面的元素个数
pq(data).find('td').eq(i) 获取此段代码过滤后的第i个元素
从上面的输出可以看到,我们需要的数据就是第1,2,6 三个元素,那么我们的代码可以这样写:
输出结果如下(截取一段):
600401
海润光伏
光伏 太阳能 阶梯电价受益 多晶硅 券商(龙头) 金太阳工程
看到没有,我们需要的信息已经逐渐清晰了,目前股票代码和股票名称已经能解析出来后进行准确的定位,剩下的就是将以空格隔开的概念单个解析出来与股票进行匹配。
有了上面的经验,我们继续观察第一段代码,以便对概念进行第三次解析
可以看到,概念的信息在'td'代码段里面又分了几组,组与组之间以'a'标签进行分隔,那么需要对'td'组内的第6个元素再次进行过滤,可用如下代码进行测试:
v_ind = pq(data).find('td').eq(5)
pq(v_ind).find('a')
以上两段代码是关键,第一行代码用于摘出概念模块的html代码,如下:
第二行代码则用于在上面的代码里面继续过滤以'a'为标签的元素,这样就把之前以空格分隔的数据单个过滤出来了。
从上至下,我们依次得到了股票代码,股票名称以及单个的概念名称,那么我们将这三者组合在一起并输出,可以像这样写代码:
这样,我们在最里面的循环里面即可将股票和概念单对单组合,最后可将结果写入数据库或文件系统中
输出结果如下:
原因是太繁琐了,而且对于每种网页都需要写特定的表达式,不可通用。
后面在查找相关资料时,发现python也提供一个类似jquery的包,叫做pyquery,可用以进行网络抓取,遂安装研究了一下,发现确实挺好用,不用写复杂的表达式即可
对数据进行抓取和过滤。
下面就以一个网页为例,来抓取指定格式的数据,并记录过程。
http://yunvs.com/list/mai_1.html
我要抓取这个网页上的数据,如下图:
我现在需要抓取股票与概念的关系,以便应用可以方便的通过股票查找其所属的概念,也可以通过热点概念定位相关股票。
那么,应用所需要的数据格式应该是这样的:
股票代码 股票名称 概念名称
002011 盾安环境 多晶硅
002011 盾安环境 分布式能源
002011 盾安环境 核电
002011 盾安环境 核电通风与空气处
002011 盾安环境 太阳能
002011 盾安环境 低碳经济
002011 盾安环境 珠港澳大桥概念
002011 盾安环境 地热
002011 盾安环境 地热能
002011 盾安环境 供热管网改造
002011 盾安环境 疫苗储存
002011 盾安环境 干热岩
但是从网页上我们可以看到,数据是以行的形式来展现的,单只股票后面跟了多个概念,且概念与概念之间以空格为分隔符,所以我们不仅仅要对数据进行抓取,同时还要对其格式进行处理。
下面,我们就通过python的第三方扩展包pyquery来对此网页进行抓取。
1.安装pyquery包
具体的安装过程就不在这里详述了,python的包安装可以通过一个工具叫做easy_install来进行安装和管理,大家百度一下即可得到相关资料。
pyquery包解析html以来lxml包,所以这里要安装pyquery和lxml两个包才可使用pyquery.
pyquery的官网地址: ht tp://pythonhosted.org//pyquery/api.htm l ,上面有详细的每个api的使用方法
2.导入pyquery包
from pyquery import PyQuery as pq
from lxml import etree
3.加载需要解析的数据源
v_source=pq("hello") ---直接加载一个html串
v_source=pq(filename=path_to_html_file) ---加载位于指定路径下的html文件
v_source=pq(url='http://yunvs.com/list/mai_1.html') ---加载url地址直接进行解析
在这里我们就直接使用第三种方式,直接加载网页来进行数据抓取,这样显得更直观和实用。
4.分析要解析的html网页代码
以 http://yunvs.com/list/mai_1.html 为例,我们要抓取股票和概念的数据,那么查看其网页源码,将要解析的代码段摘出来,如下:
点击(此处)折叠或打开
- <tr height=\"30\" > <td align=\"center\"><a href=\"http://yunvs.com/600401\" target=\"_blank\">600401</a></td>
- <td align=\"center\"><a href=\"http://yunvs.com/600401\" target=\"_blank\">海润光伏</a></td>
- <td align=\"center\">17876.8</td>
- <td align=\"center\">2005.74</td>
- <td align=\"center\"><font color=\"#C00\"><b>+791.28%</b></font></td>
- <td align=\"left\"><a href=\"http://yunvs.com/theme/t640.html\" target=\"_blank\">光伏</a> <a href=\"http://yunvs.com/theme/t323.html\" target=\"_blank\">太阳能</a> <a href=\"http://yunvs.com/theme/t225.html\" target=\"_blank\">阶梯电价受益</a> <a href=\"http://yunvs.com/theme/t105.html\" target=\"_blank\">多晶硅</a> <a href=\"http://yunvs.com/theme/t285.html\" target=\"_blank\">券商(龙头)</a> <a href=\"http://yunvs.com/theme/t230.html\" target=\"_blank\">金太阳工程</a> </td>
- </tr>
第一步过滤可以这样写:
v_source=pq(url='http://yunvs.com/list/mai_1.html')
v_source('tr') ----这里就是将所有以tr打头的html段过滤出来
想测试的话,可以用以下的语句来输出结果。
for data in v_source('tr'):
print pq(data).html() ---直接输出截取串的html对象,看着更加直观
输出如下:
点击(此处)折叠或打开
- <th width=\"60px\" align=\"center\">代码</th>
- <th width=\"60px\" align=\"center\">股票</th>
- <th width=\"80px\" align=\"center\"><a href=\"http://yunvs.com/list/mai_1.html\">市场关注度↓</a></th>
- <th width=\"65px\" align=\"center\"><a href=\"http://yunvs.com/list/mai_ac_1.html\" style=\"text-decoration:underline\">平均MAI</a></th>
- <th width=\"100px\" align=\"center\"><a href=\"http://yunvs.com/list/mai_mc_1.html\" style=\"text-decoration:underline\">MAI相对变动</a></th>
- <th width=\"530px\" align=\"center\">相关概念</th>
-
- <td align=\"center\"><a href=\"http://yunvs.com/600401\" target=\"_blank\">600401</a></td>
- <td align=\"center\"><a href=\"http://yunvs.com/600401\" target=\"_blank\">海润光伏</a></td>
- <td align=\"center\">17417.6</td>
- <td align=\"center\">2006.94</td>
- <td align=\"center\"><font color=\"#C00\"><b>+767.87%</b></font></td>
- <td align=\"left\"><a href=\"http://yunvs.com/theme/t640.html\" target=\"_blank\">光伏</a> <a href=\"http://yunvs.com/theme/t323.html\" target=\"_blank\">太阳能</a> <a href=\"http://yunvs.com/theme/t225.html\" target=\"_blank\">阶梯电价受益</a> <a href=\"http://yunvs.com/theme/t105.html\" target=\"_blank\">多晶硅</a> <a href=\"http://yunvs.com/theme/t285.html\" target=\"_blank\">券商(龙头)</a> <a href=\"http://yunvs.com/theme/t230.html\" target=\"_blank\">金太阳工程</a> </td>
-
- <td align=\"center\"><a href=\"http://yunvs.com/002143\" target=\"_blank\">002143</a></td>
- <td align=\"center\"><a href=\"http://yunvs.com/002143\" target=\"_blank\">高金食品</a></td>
- <td align=\"center\">10220.3</td>
- <td align=\"center\">1336.69</td>
- <td align=\"center\"><font color=\"#C00\"><b>+664.6%</b></font></td>
- <td align=\"left\"><a href=\"http://yunvs.com/theme/t293.html\" target=\"_blank\">肉制品</a> <a href=\"http://yunvs.com/theme/t290.html\" target=\"_blank\">猪肉</a> <a href=\"http://yunvs.com/theme/t458.html\" target=\"_blank\">成渝特区</a> <a href=\"http://yunvs.com/theme/t862.html\" target=\"_blank\">猪肉加工</a> <a href=\"http://yunvs.com/theme/t1150.html\" target=\"_blank\">农地林地</a> <a href=\"http://yunvs.com/theme/t1020.html\" target=\"_blank\">传媒</a> </td>
-
- <td align=\"center\"><a href=\"http://yunvs.com/002070\" target=\"_blank\">002070</a></td>
- <td align=\"center\"><a href=\"http://yunvs.com/002070\" target=\"_blank\">众和股份</a></td>
- <td align=\"center\">6022.89</td>
- <td align=\"center\">611.21</td>
- <td align=\"center\"><font color=\"#C00\"><b>+885.4%</b></font></td>
- <td align=\"left\"><a href=\"http://yunvs.com/theme/t397.html\" target=\"_blank\">印染</a> <a href=\"http://yunvs.com/theme/t906.html\" target=\"_blank\">锂精矿</a> <a href=\"http://yunvs.com/theme/t1222.html\" target=\"_blank\">海西</a> <a href=\"http://yunvs.com/theme/t211.html\" target=\"_blank\">己内酰胺</a> </td>
-
- <td align=\"center\"><a href=\"http://yunvs.com/300213\" target=\"_blank\">300213</a></td>
- <td align=\"center\"><a href=\"http://yunvs.com/300213\" target=\"_blank\">佳讯飞鸿</a></td>
- <td align=\"center\">5896.39</td>
- <td align=\"center\">374.88</td>
- <td align=\"center\"><font color=\"#C00\"><b>+1472.87%</b></font></td>
- <td align=\"left\"><a href=\"http://yunvs.com/theme/t151.html\" target=\"_blank\">光通信</a> <a href=\"http://yunvs.com/theme/t1157.html\" target=\"_blank\">探月工程</a> <a href=\"http://yunvs.com/theme/t1129.html\" target=\"_blank\">三季报预增</a> <a href=\"http://yunvs.com/theme/t1161.html\" target=\"_blank\">铁路营改增</a> <a href=\"http://yunvs.com/theme/t1161.html\" target=\"_blank\">铁路营改增</a> </td>
-
- <td align=\"center\"><a href=\"http://yunvs.com/600732\" target=\"_blank\">600732</a></td>
- <td align=\"center\"><a href=\"http://yunvs.com/600732\" target=\"_blank\">上海新梅</a></td>
- <td align=\"center\">4529.39</td>
- <td align=\"center\">894.01</td>
- <td align=\"center\"><font color=\"#C00\"><b>+406.64%</b></font></td>
- <td align=\"left\"><a href=\"http://yunvs.com/theme/t80.html\" target=\"_blank\">迪士尼</a> <a href=\"http://yunvs.com/theme/t66.html\" target=\"_blank\">创投</a> </td>
-
- <td align=\"center\"><a href=\"http://yunvs.com/600303\" target=\"_blank\">600303</a></td>
- <td align=\"center\"><a href=\"http://yunvs.com/600303\" target=\"_blank\">曙光股份</a></td>
- <td align=\"center\">4139.83</td>
- <td align=\"center\">131.78</td>
- <td align=\"center\"><font color=\"#C00\"><b>+3041.47%</b></font></td>
- <td align=\"left\"><a href=\"http://yunvs.com/theme/t241.html\" target=\"_blank\">客车</a> <a href=\"http://yunvs.com/theme/t380.html\" target=\"_blank\">新能源客车</a> <a href=\"http://yunvs.com/theme/t459.html\" target=\"_blank\">东北振兴</a> <a href=\"http://yunvs.com/theme/t396.html\" target=\"_blank\">乙肝疫苗</a> <a href=\"http://yunvs.com/theme/t588.html\" target=\"_blank\">校车</a> <a href=\"http://yunvs.com/theme/t147.html\" target=\"_blank\">公路运输</a> <a href=\"http://yunvs.com/theme/t147.html\" target=\"_blank\">公路运输</a> <a href=\"http://yunvs.com/theme/t1266.html\" target=\"_blank\">镍碳超级电容电池</a> </td>
-
- <td align=\"center\"><a href=\"http://yunvs.com/002130\" target=\"_blank\">002130</a></td>
- <td align=\"center\"><a href=\"http://yunvs.com/002130\" target=\"_blank\">沃尔核材</a></td>
- <td align=\"center\">3749.11</td>
- <td align=\"center\">1875.24</td>
- <td align=\"center\"><font color=\"#C00\"><b>+99.93%</b></font></td>
- <td align=\"left\"><a href=\"http://yunvs.com/theme/t174.html\" target=\"_blank\">核电</a> <a href=\"http://yunvs.com/theme/t232.html\" target=\"_blank\">抗辐射</a> <a href=\"http://yunvs.com/theme/t381.html\" target=\"_blank\">新型建材</a> <a href=\"http://yunvs.com/theme/t444.html\" target=\"_blank\">新材料</a> <a href=\"http://yunvs.com/theme/t456.html\" target=\"_blank\">珠三角区</a> <a href=\"http://yunvs.com/theme/t97.html\" target=\"_blank\">电线电缆</a> <a href=\"http://yunvs.com/theme/t1201.html\" target=\"_blank\">铁基超导</a> <a href=\"http://yunvs.com/theme/t704.html\" target=\"_blank\">合肥综合保税区</a> <a href=\"http://yunvs.com/theme/t1159.html\" target=\"_blank\">中英核电合作</a> <a href=\"http://yunvs.com/theme/t58.html\" target=\"_blank\">超导材料</a> <a href=\"http://yunvs.com/theme/t1321.html\" target=\"_blank\">新合成三维材料</a> </td>
-
- <td align=\"center\"><a href=\"http://yunvs.com/002113\" target=\"_blank\">002113</a></td>
- <td align=\"center\"><a href=\"http://yunvs.com/002113\" target=\"_blank\">天润控股</a></td>
- <td align=\"center\">3741.65</td>
- <td align=\"center\">569.31</td>
- <td align=\"center\"><font color=\"#C00\"><b>+557.23%</b></font></td>
- <td align=\"left\"><a href=\"http://yunvs.com/theme/t754.html\" target=\"_blank\">足球</a> </td>
-
- <td align=\"center\"><a href=\"http://yunvs.com/600315\" target=\"_blank\">600315</a></td>
- <td align=\"center\"><a href=\"http://yunvs.com/600315\" target=\"_blank\">上海家化</a></td>
- <td align=\"center\">3638.3</td>
- <td align=\"center\">1602.57</td>
- <td align=\"center\"><font color=\"#C00\"><b>+127.03%</b></font></td>
- <td align=\"left\"><a href=\"http://yunvs.com/theme/t193.html\" target=\"_blank\">化妆品</a> <a href=\"http://yunvs.com/theme/t616.html\" target=\"_blank\">消毒</a> <a href=\"http://yunvs.com/theme/t626.html\" target=\"_blank\">抗病毒产品</a> <a href=\"http://yunvs.com/theme/t50.html\" target=\"_blank\">丙烯腈</a> <a href=\"http://yunvs.com/theme/t383.html\" target=\"_blank\">信托</a> <a href=\"http://yunvs.com/theme/t67.html\" target=\"_blank\">纯碱</a> <a href=\"http://yunvs.com/theme/t1129.html\" target=\"_blank\">三季报预增</a> <a href=\"http://yunvs.com/theme/t1068.html\" target=\"_blank\">易信</a> <a href=\"http://yunvs.com/theme/t593.html\" target=\"_blank\">民族品牌</a> <a href=\"http://yunvs.com/theme/t56.html\" target=\"_blank\">草甘膦</a> <a href=\"http://yunvs.com/theme/t41.html\" target=\"_blank\">苯胺</a> <a href=\"http://yunvs.com/theme/t211.html\" target=\"_blank\">己内酰胺</a> </td>
-
- <td align=\"center\"><a href=\"http://yunvs.com/002009\" target=\"_blank\">002009</a></td>
- <td align=\"center\"><a href=\"http://yunvs.com/002009\" target=\"_blank\">天奇股份</a></td>
- <td align=\"center\">3566.27</td>
- <td align=\"center\">412.28</td>
- <td align=\"center\"><font color=\"#C00\"><b>+765.01%</b></font></td>
- <td align=\"left\"><a href=\"http://yunvs.com/theme/t126.html\" target=\"_blank\">风电叶片</a> <a href=\"http://yunvs.com/theme/t370.html\" target=\"_blank\">低碳经济</a> <a href=\"http://yunvs.com/theme/t460.html\" target=\"_blank\">江苏沿海地区</a> <a href=\"http://yunvs.com/theme/t523.html\" target=\"_blank\">机器人</a> <a href=\"http://yunvs.com/theme/t804.html\" target=\"_blank\">工业自动化</a> <a href=\"http://yunvs.com/theme/t845.html\" target=\"_blank\">智能物流骨干网</a> <a href=\"http://yunvs.com/theme/t742.html\" target=\"_blank\">供热管网改造</a> <a href=\"http://yunvs.com/theme/t362.html\" target=\"_blank\">物流</a> <a href=\"http://yunvs.com/theme/t998.html\" target=\"_blank\">报废车回收</a> <a href=\"http://yunvs.com/theme/t871.html\" target=\"_blank\">万达文化旅游城</a> <a href=\"http://yunvs.com/theme/t451.html\" target=\"_blank\">循环经济</a> </td>
-
- <td align=\"center\"><a href=\"http://yunvs.com/000018\" target=\"_blank\">000018</a></td>
- <td align=\"center\"><a href=\"http://yunvs.com/000018\" target=\"_blank\">中冠A</a></td>
- <td align=\"center\">3354.35</td>
- <td align=\"center\">172.67</td>
- <td align=\"center\"><font color=\"#C00\"><b>+1842.63%</b></font></td>
- <td align=\"left\"><a href=\"http://yunvs.com/theme/t397.html\" target=\"_blank\">印染</a> <a href=\"http://yunvs.com/theme/t1152.html\" target=\"_blank\">工业用地</a> </td>
-
- <td align=\"center\"><a href=\"http://yunvs.com/000036\" target=\"_blank\">000036</a></td>
- <td align=\"center\"><a href=\"http://yunvs.com/000036\" target=\"_blank\">华联控股</a></td>
- <td align=\"center\">3131.94</td>
- <td align=\"center\">184.24</td>
- <td align=\"center\"><font color=\"#C00\"><b>+1599.93%</b></font></td>
- <td align=\"left\"><a href=\"http://yunvs.com/theme/t8.html\" target=\"_blank\">PTA(化工)</a> <a href=\"http://yunvs.com/theme/t282.html\" target=\"_blank\">前海开发</a> <a href=\"http://yunvs.com/theme/t456.html\" target=\"_blank\">珠三角区</a> <a href=\"http://yunvs.com/theme/t494.html\" target=\"_blank\">深圳土地创新</a> <a href=\"http://yunvs.com/theme/t681.html\" target=\"_blank\">家具建材</a> <a href=\"http://yunvs.com/theme/t468.html\" target=\"_blank\">前海规划</a> <a href=\"http://yunvs.com/theme/t1152.html\" target=\"_blank\">工业用地</a> <a href=\"http://yunvs.com/theme/t1155.html\" target=\"_blank\">集体建设用地</a> </td>
-
- <td align=\"center\"><a href=\"http://yunvs.com/002356\" target=\"_blank\">002356</a></td>
- <td align=\"center\"><a href=\"http://yunvs.com/002356\" target=\"_blank\">浩宁达</a></td>
- <td align=\"center\">2798.2</td>
- <td align=\"center\">257.86</td>
- <td align=\"center\"><font color=\"#C00\"><b>+985.16%</b></font></td>
- <td align=\"left\"><a href=\"http://yunvs.com/theme/t412.html\" target=\"_blank\">智能电表</a> <a href=\"http://yunvs.com/theme/t413.html\" target=\"_blank\">智能电网</a> <a href=\"http://yunvs.com/theme/t797.html\" target=\"_blank\">电力改革</a> </td>
-
- <td align=\"center\"><a href=\"http://yunvs.com/300249\" target=\"_blank\">300249</a></td>
- <td align=\"center\"><a href=\"http://yunvs.com/300249\" target=\"_blank\">依米康</a></td>
- <td align=\"center\">2796.64</td>
- <td align=\"center\">713.37</td>
- <td align=\"center\"><font color=\"#C00\"><b>+292.03%</b></font></td>
- <td align=\"left\"></td>
-
- <td align=\"center\"><a href=\"http://yunvs.com/300282\" target=\"_blank\">300282</a></td>
- <td align=\"center\"><a href=\"http://yunvs.com/300282\" target=\"_blank\">汇冠股份</a></td>
- <td align=\"center\">2721.66</td>
- <td align=\"center\">488.97</td>
- <td align=\"center\"><font color=\"#C00\"><b>+456.61%</b></font></td>
- <td align=\"left\"><a href=\"http://yunvs.com/theme/t778.html\" target=\"_blank\">教育装备</a> <a href=\"http://yunvs.com/theme/t857.html\" target=\"_blank\">联想供应链</a> <a href=\"http://yunvs.com/theme/t63.html\" target=\"_blank\">触摸屏</a> <a href=\"http://yunvs.com/theme/t997.html\" target=\"_blank\">游戏机</a> </td>
-
- <td align=\"center\"><a href=\"http://yunvs.com/300279\" target=\"_blank\">300279</a></td>
- <td align=\"center\"><a href=\"http://yunvs.com/300279\" target=\"_blank\">和晶科技</a></td>
- <td align=\"center\">2669.16</td>
- <td align=\"center\">586.76</td>
- <td align=\"center\"><font color=\"#C00\"><b>+354.9%</b></font></td>
- <td align=\"left\"><a href=\"http://yunvs.com/theme/t635.html\" target=\"_blank\">手势控制</a> <a href=\"http://yunvs.com/theme/t405.html\" target=\"_blank\">云计算</a> <a href=\"http://yunvs.com/theme/t653.html\" target=\"_blank\">无锡物联网</a> <a href=\"http://yunvs.com/theme/t577.html\" target=\"_blank\">智能家居</a> <a href=\"http://yunvs.com/theme/t361.html\" target=\"_blank\">物联网</a> </td>
-
- <td align=\"center\"><a href=\"http://yunvs.com/300220\" target=\"_blank\">300220</a></td>
- <td align=\"center\"><a href=\"http://yunvs.com/300220\" target=\"_blank\">金运激光</a></td>
- <td align=\"center\">2411.08</td>
- <td align=\"center\">873.71</td>
- <td align=\"center\"><font color=\"#C00\"><b>+175.96%</b></font></td>
- <td align=\"left\"><a href=\"http://yunvs.com/theme/t524.html\" target=\"_blank\">激光武器</a> <a href=\"http://yunvs.com/theme/t826.html\" target=\"_blank\">激光</a> <a href=\"http://yunvs.com/theme/t483.html\" target=\"_blank\">3D打印</a> </td>
-
- <td align=\"center\"><a href=\"http://yunvs.com/600754\" target=\"_blank\">600754</a></td>
- <td align=\"center\"><a href=\"http://yunvs.com/600754\" target=\"_blank\">锦江股份</a></td>
- <td align=\"center\">2360.15</td>
- <td align=\"center\">387.22</td>
- <td align=\"center\"><font color=\"#C00\"><b>+509.51%</b></font></td>
- <td align=\"left\"><a href=\"http://yunvs.com/theme/t80.html\" target=\"_blank\">迪士尼</a> <a href=\"http://yunvs.com/theme/t84.html\" target=\"_blank\">迪士尼旅游消费</a> <a href=\"http://yunvs.com/theme/t234.html\" target=\"_blank\">酒店餐饮</a> <a href=\"http://yunvs.com/theme/t1029.html\" target=\"_blank\">上海金融创新</a> <a href=\"http://yunvs.com/theme/t441.html\" target=\"_blank\">镁矿</a> <a href=\"http://yunvs.com/theme/t1143.html\" target=\"_blank\">国企改革</a> <a href=\"http://yunvs.com/theme/t733.html\" target=\"_blank\">旅游行业</a> </td>
-
- <td align=\"center\"><a href=\"http://yunvs.com/002619\" target=\"_blank\">002619</a></td>
- <td align=\"center\"><a href=\"http://yunvs.com/002619\" target=\"_blank\">巨龙管业</a></td>
- <td align=\"center\">2285.8</td>
- <td align=\"center\">1446.89</td>
- <td align=\"center\"><font color=\"#C00\"><b>+57.98%</b></font></td>
- <td align=\"left\"><a href=\"http://yunvs.com/theme/t481.html\" target=\"_blank\">城市管网建设</a> <a href=\"http://yunvs.com/theme/t272.html\" target=\"_blank\">农田水利建设</a> <a href=\"http://yunvs.com/theme/t607.html\" target=\"_blank\">防洪排水</a> <a href=\"http://yunvs.com/theme/t1170.html\" target=\"_blank\">高标准农田建设</a> <a href=\"http://yunvs.com/theme/t26.html\" target=\"_blank\">电子信息</a> </td>
-
- <td align=\"center\"><a href=\"http://yunvs.com/002205\" target=\"_blank\">002205</a></td>
- <td align=\"center\"><a href=\"http://yunvs.com/002205\" target=\"_blank\">国统股份</a></td>
- <td align=\"center\">2283.95</td>
- <td align=\"center\">544.05</td>
- <td align=\"center\"><font color=\"#C00\"><b>+319.81%</b></font></td>
- <td align=\"left\"><a href=\"http://yunvs.com/theme/t165.html\" target=\"_blank\">管道管材</a> <a href=\"http://yunvs.com/theme/t272.html\" target=\"_blank\">农田水利建设</a> <a href=\"http://yunvs.com/theme/t321.html\" target=\"_blank\">塑料建材</a> <a href=\"http://yunvs.com/theme/t476.html\" target=\"_blank\">水利设备</a> <a href=\"http://yunvs.com/theme/t481.html\" target=\"_blank\">城市管网建设</a> <a href=\"http://yunvs.com/theme/t652.html\" target=\"_blank\">大额中标</a> <a href=\"http://yunvs.com/theme/t527.html\" target=\"_blank\">消暑抗旱</a> <a href=\"http://yunvs.com/theme/t607.html\" target=\"_blank\">防洪排水</a> <a href=\"http://yunvs.com/theme/t23.html\" target=\"_blank\">MDI(化工)</a> <a href=\"http://yunvs.com/theme/t24.html\" target=\"_blank\">MTBE(化工)</a> <a href=\"http://yunvs.com/theme/t27.html\" target=\"_blank\">PET瓶(化工)</a> <a href=\"http://yunvs.com/theme/t28.html\" target=\"_blank\">PE(化工)</a> <a href=\"http://yunvs.com/theme/t29.html\" target=\"_blank\">PP(化工)</a> <a href=\"http://yunvs.com/theme/t17.html\" target=\"_blank\">HDPE(化工)</a> <a href=\"http://yunvs.com/theme/t12.html\" target=\"_blank\">BDO(化工)</a> <a href=\"http://yunvs.com/theme/t834.html\" target=\"_blank\">沧州本地</a> <a href=\"http://yunvs.com/theme/t30.html\" target=\"_blank\">PS(化工)</a> <a href=\"http://yunvs.com/theme/t235.html\" target=\"_blank\">PBT(化工)</a> <a href=\"http://yunvs.com/theme/t237.html\" target=\"_blank\">PVC(化工)</a> <a href=\"http://yunvs.com/theme/t238.html\" target=\"_blank\">PC(化工)</a> <a href=\"http://yunvs.com/theme/t239.html\" target=\"_blank\">PA(化工)</a> <a href=\"http://yunvs.com/theme/t252.html\" target=\"_blank\">OX(化工)</a> <a href=\"http://yunvs.com/theme/t22.html\" target=\"_blank\">LDPE(化工)</a> <a href=\"http://yunvs.com/theme/t16.html\" target=\"_blank\">DOP(化工)</a> <a href=\"http://yunvs.com/theme/t7.html\" target=\"_blank\">PU(化工)</a> <a href=\"http://yunvs.com/theme/t8.html\" target=\"_blank\">PTA(化工)</a> <a href=\"http://yunvs.com/theme/t1040.html\" target=\"_blank\">新疆建设</a> <a href=\"http://yunvs.com/theme/t916.html\" target=\"_blank\">喀什经济开发区</a> <a href=\"http://yunvs.com/theme/t421.html\" target=\"_blank\">自来水供应</a> </td>
基本上我们需要的核心块都被抓取出来了
我们也可以以text文本的方式输出,这样就去掉了html标记
点击(此处)折叠或打开
- #coding=utf-8
from pyquery import PyQuery as pq
from lxml import etree
from pyquery import PyQuery as pq
from lxml import etree
v_source=pq(url='http://yunvs.com/list/mai_1.html')
for data in v_source('tr'):
print pq(data).text() -----以text文本的方式进行输出 -
结果如下:
点击(此处)折叠或打开
- 代码 股票 市场关注度↓ 平均MAI MAI相对变动 相关概念
- 600401 海润光伏 17417.6 2006.94 +767.87% 光伏 太阳能 阶梯电价受益 多晶硅 券商(龙头) 金太阳工程
- 002143 高金食品 10391.3 1339.54 +675.74% 肉制品 猪肉 成渝特区 猪肉加工 农地林地 传媒
- 002070 众和股份 6022.89 611.21 +885.4% 印染 锂精矿 海西 己内酰胺
- 300213 佳讯飞鸿 5896.39 374.88 +1472.87% 光通信 探月工程 三季报预增 铁路营改增 铁路营改增
- 600732 上海新梅 4529.39 894.01 +406.64% 迪士尼 创投
- 600303 曙光股份 4139.83 131.78 +3041.47% 客车 新能源客车 东北振兴 乙肝疫苗 校车 公路运输 公路运输 镍碳超级电容电池
- 002130 沃尔核材 3749.11 1875.24 +99.93% 核电 抗辐射 新型建材 新材料 珠三角区 电线电缆 铁基超导 合肥综合保税区 中英核电合作 超导材料 新合成三维材料
- 002113 天润控股 3741.65 569.31 +557.23% 足球
- 600315 上海家化 3638.3 1602.57 +127.03% 化妆品 消毒 抗病毒产品 丙烯腈 信托 纯碱 三季报预增 易信 民族品牌 草甘膦 苯胺 己内酰胺
- 002009 天奇股份 3566.27 412.28 +765.01% 风电叶片 低碳经济 江苏沿海地区 机器人 工业自动化 智能物流骨干网 供热管网改造 物流 报废车回收 万达文化旅游城 循环经济
- 000018 中冠A 3354.35 172.67 +1842.63% 印染 工业用地
- 000036 华联控股 3131.94 184.24 +1599.93% PTA(化工) 前海开发 珠三角区 深圳土地创新 家具建材 前海规划 工业用地 集体建设用地
- 002356 浩宁达 2798.2 257.86 +985.16% 智能电表 智能电网 电力改革
- 300249 依米康 2796.64 713.37 +292.03%
- 300282 汇冠股份 2721.66 488.97 +456.61% 教育装备 联想供应链 触摸屏 游戏机
- 300279 和晶科技 2669.16 586.76 +354.9% 手势控制 云计算 无锡物联网 智能家居 物联网
- 300010 立思辰 2452.26 636.86 +285.06% 软件外包 网络安全 饮料包装 网络教育 棱镜计划 在线教育 空中交通管理 电子政务 职业教育 去IOE 阿里巴巴上市 信息安全 高校 智慧医疗 WAPI WAPI 国家安全
- 300220 金运激光 2411.08 873.71 +175.96% 激光武器 激光 3D打印
- 600754 锦江股份 2360.15 387.22 +509.51% 迪士尼 迪士尼旅游消费 酒店餐饮 上海金融创新 镁矿 国企改革 旅游行业
- 600016 民生银行 2338.14 1424.41 +64.15% 股份制银行 海洋工程 二维码 海洋产品养殖 棚户改造 民生电商 奢侈品 人民币升值 农业合作社 电子商务 电商 支付宝 无人岛 互联网金融 三季报预增 聚宝盆 T+0 券商 券商 影子银行 金枪鱼 金枪鱼 泉州金改 余额宝 金改 博鳌 港股互通 微信理财通 儿童节 小额贷款
如果我们想获取每一行的第一个记录应该如何得到呢?
这里就要分析一下代码了,还是以这段代码为例:
点击(此处)折叠或打开
- <tr height=\"30\" > <td align=\"center\"><a href=\"http://yunvs.com/600401\" target=\"_blank\">600401</a></td>
- <td align=\"center\"><a href=\"http://yunvs.com/600401\" target=\"_blank\">海润光伏</a></td>
- <td align=\"center\">17876.8</td>
- <td align=\"center\">2005.74</td>
- <td align=\"center\"><font color=\"#C00\"><b>+791.28%</b></font></td>
- <td align=\"left\"><a href=\"http://yunvs.com/theme/t640.html\" target=\"_blank\">光伏</a> <a href=\"http://yunvs.com/theme/t323.html\" target=\"_blank\">太阳能</a> <a href=\"http://yunvs.com/theme/t225.html\" target=\"_blank\">阶梯电价受益</a> <a href=\"http://yunvs.com/theme/t105.html\" target=\"_blank\">多晶硅</a> <a href=\"http://yunvs.com/theme/t285.html\" target=\"_blank\">券商(龙头)</a> <a href=\"http://yunvs.com/theme/t230.html\" target=\"_blank\">金太阳工程</a> </td>
- </tr>
点击(此处)折叠或打开
- #coding=utf-8
from pyquery import PyQuery as pq
from lxml import etree
from pyquery import PyQuery as pq
from lxml import etree
v_source=pq(url='http://yunvs.com/list/mai_1.html')
for data in v_source('tr'):
print pq(data).text()
for i in range(len(data)):
print pq(data).find('td').eq(i).text() -
截取一段输出如下:
600315 上海家化 3645.76 1602.69 +127.48% 化妆品 消毒 抗病毒产品 丙烯腈 信托 纯碱 三季报预增 易信 民族品牌 草甘膦 苯胺 己内酰胺
600315 ----eq(0) 组内第一个元素
上海家化 ---eq(1) 组内第二个元素
3645.76 ----eq(2) 组内第三个元素
1602.69 ----eq(3) 组内第四个元素
+127.48% ----eq(4) 组内第五个元素
化妆品 消毒 抗病毒产品 丙烯腈 信托 纯碱 三季报预增 易信 民族品牌 草甘膦 苯胺 己内酰胺 ---组内第六个元素
以上抓取代码解释如下:
pq(data).find('td') 意思是对第一次过滤的 v_source('tr')代码再次在内部进行二次查找,过滤'td'打头的段,可以看到一共有5个。
len(data) 输出代码里面的元素个数
pq(data).find('td').eq(i) 获取此段代码过滤后的第i个元素
从上面的输出可以看到,我们需要的数据就是第1,2,6 三个元素,那么我们的代码可以这样写:
点击(此处)折叠或打开
- #coding=utf-8
from pyquery import PyQuery as pq
from lxml import etree
from pyquery import PyQuery as pq
from lxml import etree
v_source=pq(url='http://yunvs.com/list/mai_1.html')
for data in v_source('tr'):
print pq(data).find('td').eq(0).text()
print pq(data).find('td').eq(1).text()
print pq(data).find('td').eq(5).text() -
输出结果如下(截取一段):
600401
海润光伏
光伏 太阳能 阶梯电价受益 多晶硅 券商(龙头) 金太阳工程
看到没有,我们需要的信息已经逐渐清晰了,目前股票代码和股票名称已经能解析出来后进行准确的定位,剩下的就是将以空格隔开的概念单个解析出来与股票进行匹配。
有了上面的经验,我们继续观察第一段代码,以便对概念进行第三次解析
点击(此处)折叠或打开
- <tr height=\"30\" > <td align=\"center\"><a href=\"http://yunvs.com/600401\" target=\"_blank\">600401</a></td>
- <td align=\"center\"><a href=\"http://yunvs.com/600401\" target=\"_blank\">海润光伏</a></td>
- <td align=\"center\">17876.8</td>
- <td align=\"center\">2005.74</td>
- <td align=\"center\"><font color=\"#C00\"><b>+791.28%</b></font></td>
- <td align=\"left\"><a href=\"http://yunvs.com/theme/t640.html\" target=\"_blank\">光伏</a> <a href=\"http://yunvs.com/theme/t323.html\" target=\"_blank\">太阳能</a> <a href=\"http://yunvs.com/theme/t225.html\" target=\"_blank\">阶梯电价受益</a> <a href=\"http://yunvs.com/theme/t105.html\" target=\"_blank\">多晶硅</a> <a href=\"http://yunvs.com/theme/t285.html\" target=\"_blank\">券商(龙头)</a> <a href=\"http://yunvs.com/theme/t230.html\" target=\"_blank\">金太阳工程</a> </td>
- </tr>
点击(此处)折叠或打开
- #coding=utf-8
from pyquery import PyQuery as pq
from lxml import etree
from pyquery import PyQuery as pq
from lxml import etree
v_source=pq(url='http://yunvs.com/list/mai_1.html')
for data in v_source('tr'):
print pq(data).find('td').eq(0).text()
print pq(data).find('td').eq(1).text()
print pq(data).find('td').eq(5).text()
v_ind = pq(data).find('td').eq(5)
for i in range(len(pq(v_ind).find('a'))): --输出概念元祖内以'a'打头标记的元素个数
print pq(v_ind).find('a').eq(i).text() --输出对应的元素
-
pq(v_ind).find('a')
以上两段代码是关键,第一行代码用于摘出概念模块的html代码,如下:
点击(此处)折叠或打开
- <td align=\\\"left\\\"><a href=\\\"http://yunvs.com/theme/t640.html\\\" target=\\\"_blank\\\">光伏</a> <a href=\\\"http://yunvs.com/theme/t323.html\\\" target=\\\"_blank\\\">太阳能</a> <a href=\\\"http://yunvs.com/theme/t225.html\\\" target=\\\"_blank\\\">阶梯电价受益</a> <a href=\\\"http://yunvs.com/theme/t105.html\\\" target=\\\"_blank\\\">多晶硅</a> <a href=\\\"http://yunvs.com/theme/t285.html\\\" target=\\\"_blank\\\">券商(龙头)</a> <a href=\\\"http://yunvs.com/theme/t230.html\\\" target=\\\"_blank\\\">金太阳工程</a> </td>
从上至下,我们依次得到了股票代码,股票名称以及单个的概念名称,那么我们将这三者组合在一起并输出,可以像这样写代码:
点击(此处)折叠或打开
- #coding=utf-8
from pyquery import PyQuery as pq
from lxml import etree
from pyquery import PyQuery as pq
from lxml import etree
v_source=pq(url='http://yunvs.com/list/mai_1.html')
for data in v_source('tr'):
v_code = pq(data).find('td').eq(0).text()
v_name = pq(data).find('td').eq(1).text()
v_ind = pq(data).find('td').eq(5)
for i in range(len(pq(v_ind).find('a'))):
v_indname = pq(v_ind).find('a').eq(i).text()
print v_code
print v_name
print v_indname
-
输出结果如下:
点击(此处)折叠或打开
- 600401
- 海润光伏
- 光伏
- 600401
- 海润光伏
- 太阳能
- 600401
- 海润光伏
- 阶梯电价受益
- 600401
- 海润光伏
- 多晶硅
- 600401
- 海润光伏
- 券商(龙头)
- 600401
- 海润光伏
- 金太阳工程
- 002143
- 高金食品
- 肉制品
- 002143
- 高金食品
- 猪肉
- 002143
- 高金食品
- 成渝特区
- 002143
- 高金食品
- 猪肉加工
- 002143
- 高金食品
- 农地林地
- 002143
- 高金食品
- 传媒
- 002070
- 众和股份
- 印染
- 002070
- 众和股份
- 锂精矿
- 002070
- 众和股份
- 海西
- 002070
- 众和股份
- 己内酰胺
- 300213
- 佳讯飞鸿
- 光通信
- 300213
- 佳讯飞鸿
- 探月工程
- 300213
- 佳讯飞鸿
- 三季报预增
- 300213
- 佳讯飞鸿
- 铁路营改增
- 300213
- 佳讯飞鸿
- 铁路营改增
- 600732
- 上海新梅
- 迪士尼
- 600732
- 上海新梅
- 创投
- 600303
- 曙光股份
- 客车
- 600303
- 曙光股份
- 新能源客车
- 600303
- 曙光股份
- 东北振兴
- 600303
- 曙光股份
- 乙肝疫苗
- 600303
- 曙光股份
- 校车
- 600303
- 曙光股份
- 公路运输
- 600303
- 曙光股份
- 公路运输
- 600303
- 曙光股份
- 镍碳超级电容电池
- 002113
- 天润控股
- 足球
- 002130
- 沃尔核材
- 核电
- 002130
- 沃尔核材
- 抗辐??
- 002130
- 沃尔核材
- 新型建材
- 002130
- 沃尔核材
- 新材料
- 002130
- 沃尔核材
- 珠三角区
- 002130
- 沃尔核材
- 电线电缆
- 002130
- 沃尔核材
- 铁基超导
- 002130
- 沃尔核材
- 合肥综合保税区
- 002130
- 沃尔核材
- 中英核电合作
- 002130
- 沃尔核材
- 超导材料
- 002130
- 沃尔核材
- 新合成三维材料
- 600315
- 上海家化
- 化妆品
- 600315
- 上海家化
- 消毒
- 600315
- 上海家化
- 抗病毒产品
- 600315
- 上海家化
- 丙烯腈
- 600315
- 上海家化
- 信托
- 600315
- 上海家化
- 纯碱
- 600315
- 上海家化
- 三季报预增
- 600315
- 上海家化
- 易信
- 600315
- 上海家化
- 民族品牌
- 600315
- 上海家化
- 草甘膦
- 600315
- 上海家化
- 苯胺
- 600315
- 上海家化
- 己内酰胺
- 002009
- 天奇股份
- 风电叶片
- 002009
- 天奇股份
- 低碳经济
- 002009
- 天奇股份
- 江苏沿海地区
- 002009
- 天奇股份
- 机器人
- 002009
- 天奇股份
- 工业自动化
- 002009
- 天奇股份
- 智能物流骨干网
- 002009
- 天奇股份
- 供热管网改造
- 002009
- 天奇股份
- 物流
- 002009
- 天奇股份
- 报废车回收
- 002009
- 天奇股份
- 万达文化旅游城
- 002009
- 天奇股份
- 循环经济
- 000018
- 中冠A
- 印染
- 000018
- 中冠A
- 工业用地
- 000036
- 华联控股
- PTA(化工)
- 000036
- 华联控股
- 前海开发
- 000036
- 华联控股
- 珠三角区
- 000036
- 华联控股
- 深圳土地创新
- 000036
- 华联控股
- 家具建材
- 000036
- 华联控股
- 前海规划
- 000036
- 华联控股
- 工业用地
- 000036
- 华联控股
- 集体建设用地
- 300010
- 立思辰
- 软件外包
- 300010
- 立思辰
- 网络安全
- 300010
- 立思辰
- 饮料包装
- 300010
- 立思辰
- 网络教育
- 300010
- 立思辰
- 棱镜计划
- 300010
- 立思辰
- 在线教育
- 300010
- 立思辰
- 空中交通管理
- 300010
- 立思辰
- 电子政务
- 300010
- 立思辰
- 职业教育
- 300010
- 立思辰
- 去IOE
- 300010
- 立思辰
- 阿里巴巴上市
- 300010
- 立思辰
- 信息安全
- 300010
- 立思辰
- 高校
- 300010
- 立思辰
- 智慧医疗
- 300010
- 立思辰
- WAPI
- 300010
- 立思辰
- WAPI
- 300010
- 立思辰
- 国家安全
- 002356
- 浩宁达
- 智能电表
- 002356
- 浩宁达
- 智能电网
- 002356
- 浩宁达
- 电力改革
- 300282
- 汇冠股份
- 教育装备
- 300282
- 汇冠股份
- 联想供应链
- 300282
- 汇冠股份
- 触摸屏
- 300282
- 汇冠股份
- 游戏机
- 300279
- 和晶科技
- 手势控制
- 300279
- 和晶科技
- 云计算
- 300279
- 和晶科技
- 无锡物联网
- 300279
- 和晶科技
- 智能家居
- 300279
- 和晶科技
- 物联网
- 600754
- 锦江股份
- 迪士尼
- 600754
- 锦江股份
- 迪士尼旅游消费
- 600754
- 锦江股份
- 酒店餐饮
- 600754
- 锦江股份
- 上海金融创新
- 600754
- 锦江股份
- 镁矿
- 600754
- 锦江股份
- 国企改革
- 600754
- 锦江股份
- 旅游行业
- 600016
- 民生银行
- 股份制银行
- 600016
- 民生银行
- 海洋工程
- 600016
- 民生银行
- 二维码
- 600016
- 民生银行
- 海洋产品养殖
- 600016
- 民生银行
- 棚户改造
- 600016
- 民生银行
- 民生电商
- 600016
- 民生银行
- 奢侈品
- 600016
- 民生银行
- 人民币升值
- 600016
- 民生银行
- 农业合作社
- 600016
- 民生银行
- 电子商务
- 600016
- 民生银行
- 电商
- 600016
- 民生银行
- 支付宝
- 600016
- 民生银行
- 无人岛
- 600016
- 民生银行
- 互联网金融
- 600016
- 民生银行
- 三季报预增
- 600016
- 民生银行
- 聚宝盆
- 600016
- 民生银行
- T+0
- 600016
- 民生银行
- 券商
- 600016
- 民生银行
- 券商
- 600016
- 民生银行
- 影子银行
- 600016
- 民生银行
- 金枪鱼
- 600016
- 民生银行
- 金枪鱼
- 600016
- 民生银行
- 泉州金改
- 600016
- 民生银行
- 余额宝
- 600016
- 民生银行
- 金改
- 600016
- 民生银行
- 博鳌
- 600016
- 民生银行
- 港股互通
- 600016
- 民生银行
- 微信理财通
- 600016
- 民生银行
- 儿童节
- 600016
- 民生银行
- 小额贷款
- 300220
- 金运激光
- 激光武器
- 300220
- 金运激光
- 激光
- 300220
- 金运激光
- 3D打印
来自 “ ITPUB博客 ” ,链接:http://blog.itpub.net/22166274/viewspace-1183937/,如需转载,请注明出处,否则将追究法律责任。
转载于:http://blog.itpub.net/22166274/viewspace-1183937/