招银网科面试题汇总part2
1. (数据库)左连接,右连接,全连接,内连接
左连接:全称是左外连接,是外连接中的一种。 左(外)连接,左表(a_table)的记录将会全部表示出来,而右表(b_table)只会显示符合搜索条件的记录。右表记录不足的地方均为NULL。
右连接:全称是右外连接,是外连接中的一种。与左(外)连接相反,右(外)连接,左表(a_table)只会显示符合搜索条件的记录,而右表(b_table)的记录将会全部表示出来。左表记录不足的地方均为NULL。
全连接:
Union:对两个结果集进行并集操作,不包括重复行,同时进行默认规则的排序;
Union All:对两个结果集进行并集操作,包括重复行,不进行排序;
内连接:组合两个表中的记录,返回关联字段相符的记录,也就是返回两个表的交集部分。
交叉连接:将会返回被连接的两个表的笛卡尔积,返回结果的行数等于两个表行数的乘积。
外连接包括左连接,右连接,全连接。
2. (数据库)存储过程和函数的区别
- 存储函数的限制比较多,例如不能用临时表,只能用表变量,而存储过程的限制较少,存储过程的实现功能要复杂些,而函数的实现功能针对性比较强。
- 返回值不同。存储函数必须有返回值,且仅返回一个结果值;存储过程可以没有返回值,但是能返回结果集(out,inout)。
- 调用时的不同。存储函数嵌入在SQL中使用,可以在select 存储函数名(变量值);存储过程通过call语句调用 call 存储过程名。
- 参数的不同。存储函数的参数类型类似于IN参数,没有类似于OUT和INOUT的参数。存储过程的参数类型有三种,IN、out和INOUT:
a. in:数据只是从外部传入内部使用(值传递),可以是数值也可以是变量
b. out:只允许过程内部使用(不用外部数据),给外部使用的(引用传递:外部的数据会被先清空才会进入到内部),只能是变量
c. inout:外部可以在内部使用,内部修改的也可以给外部使用,典型的引用传递,只能传递变量。
3. (数据库)事务的特性
- 原子性:原子性是指事务包含的所有操作要么全部成功,要么全部失败回滚,因此事务的操作如果成功就必须要完全应用到数据库,如果操作失败则不能对数据库有任何影响。
- 一致性:一致性是指事务必须使数据库从一个一致性状态变换到另一个一致性状态,也就是说一个事务执行之前和执行之后都必须处于一致性状态。
- 隔离性:隔离性是当多个用户并发访问数据库时,比如操作同一张表时,数据库为每一个用户开启的事务,不能被其他事务的操作所干扰,多个并发事务之间要相互隔离。即要达到这么一种效果:对于任意两个并发的事务T1和T2,在事务T1看来,T2要么在T1开始之前就已经结束,要么在T1结束之后才开始,这样每个事务都感觉不到有其他事务在并发地执行。
- 持久性:持久性是指一个事务一旦被提交了,那么对数据库中的数据的改变就是永久性的,即便是在数据库系统遇到故障的情况下也不会丢失提交事务的操作。
4. 多态可以用引用实现吗?
可以。可以通过指针和引用可以实现多态,而对象不可以。
在一个类的实例中,只会存放非静态的成员变量。 如果该类中存在虚函数的话,再多加一个指向虚函数列表指针vptr。
内存分布大致如下:
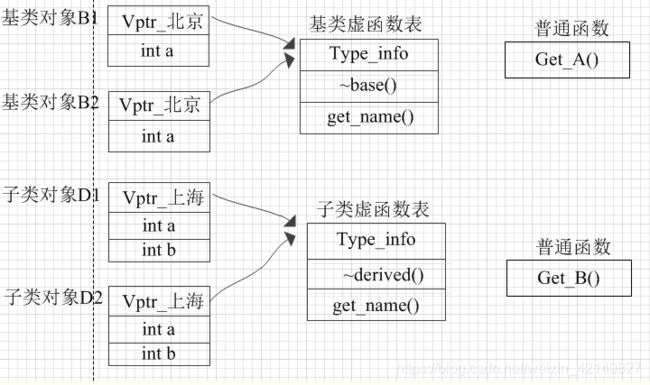
- 类对象中,只有成员变量与vptr.
- 普通成员函数在内存的某一位置放着。它们与c语言中定义的普通函数没有区别。 当我们通过对象或对象指针调用普通成员函数时, 编译器会拿到它。怎么拿到呢?当然是通过名字了,编译器都会对我们写的函数的名字进行修饰映射,让它们变成内存中唯一的函数名。
- 无论基类还是子类,每一种类类型的虚函数表只有一份,它里面存放了基类的类型信息和指向基类中的虚函数的指针。 某一类类型的所有对象都指向了相同的虚函数表。
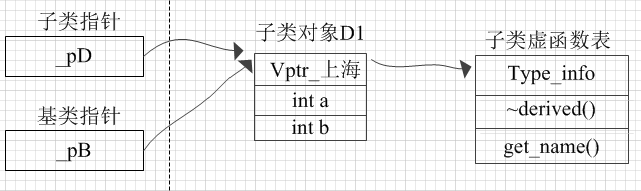
对指针的赋值,仅仅是让基类指针_pB指向的子类对象的地地址。 当我们使用基类指针调用GetName()*函数(该函数是虚函数,它的地址在函数表中)时, 会由_pB指向的地址找到子类的虚函数表指针vptr_*上海,再由vptr_上海在虚函数表中找到子类的GetName(),从而调用它。就这样实现了多态。
一个类对象里面的vptr永远不会变,永远都会指向所属类型的虚函数表。通过对象调用虚函数时,就没有必要进行动态解析了,编译器直接在编译时就可以确认具体调用哪一个函数了,因此没有所谓的多态。
引用本质上也是通过指针的解引用来实现的。
5. 如果子类中的虚函数与父类中虚函数的参数列表不一致,会发生什么?
子类重定义父类成员函数:
- 函数名,返回类型,参数都相同时:调用子类成员函数
- 函数名,返回类型相同,参数不同:重新定义继承函数,原来的函数被隐藏
- 重定义继承方法:应确保与原来的原型完全一致
虚函数复写:(覆盖)(返回值类型必须相同) - 参数列表相同
- 参数列表不同:对虚函数重新定义
在类继承中,重定义,重载。重定义函数名相同,返回类型必须相同,参数列表可以相同,可以不同;重载,函数名相同,返回类型和参数列表至少一个不同。
只要子类出现与父类同名的函数,子类就不会继承父类同名函数(隐藏)。当该同名函数在父类声明为虚函数时(virtual),称为重写(覆盖),非虚函数时,称为重定义。
6. 哈希表查找和二叉树查找时间复杂度
o(1)
若二叉树为平衡的,近似于折半查找,o(log2n);若二叉树完全不平衡,其深度可达到n,查找效率为o(n),退化为顺序查找。一般的,二叉排序树的查找性能在O(Log2n)到O(n)之间。因此,为了获得较好的查找性能,就要构造一棵平衡的二叉排序树。
7. (操作系统)线程和进程
根本区别:进程是操作系统资源分配的基本单位,而线程是任务调度和执行的基本单位,也是程序执行的最小单位。
在开销方面:每个进程都有独立的代码和数据空间(程序上下文),程序之间的切换会有较大的开销;线程可以看做轻量级的进程,同一类线程共享代码和数据空间,每个线程都有自己独立的运行栈和程序计数器(PC),线程之间切换的开销小。
所处环境:在操作系统中能同时运行多个进程(程序);而在同一个进程(程序)中有多个线程同时执行(通过CPU调度,在每个时间片中只有一个线程执行)。
内存分配方面:系统在运行的时候会为每个进程分配不同的内存空间;而对线程而言,除了CPU外,系统不会为线程分配内存(线程所使用的资源来自其所属进程的资源),线程组之间只能共享资源。
包含关系:没有线程的进程可以看做是单线程的,如果一个进程内有多个线程,则执行过程不是一条线的,而是多条线(线程)共同完成的;线程是进程的一部分,所以线程也被称为轻权进程或者轻量级进程。
通信:线程之间通信更方便,同一个进程下,线程共享全局变量,静态变量等数据,进程之间的通信需要以通信的方式(IPC)进行;(但多线程程序处理好同步与互斥是个难点)
安全性:多进程程序更安全,生命力更强,一个进程死掉不会对另一个进程造成影响(源于有独立的地址空间),多线程程序更不易维护,一个线程死掉,整个进程就死掉了(因为共享地址空间)
8.(操作系统)进程间通信
进程间通信主要包括管道, 系统IPC(包括消息队列,信号量,共享存储), SOCKET。
1. 管道(pipe)及有名管道(named pipe)
管道可用于具有亲缘关系进程间的通信,有名管道除了具有管道所具有的功能外,它还允许无亲缘关系进程间的通信。
(1) 普通管道:半双工(数据只能在一个方向上流动);只能用于用于具有亲缘关系进程间的通信;可被看作特殊的文件,可以用read,write等函数。但不属于任何文件系统,只存在于内存中。
(2) 命名管道(FIFO):可在无关的进程之间交换数据;有路径名与之相关联,以一种特殊设备文件的形式存在于文件系统中。
2. 系统IPC:
(1)消息队列 (message queue):消息队列是消息的链接表,它克服了上两种通信方式中信号量有限的缺点,具有写权限得进程可以按照一定得规则向消息队列中添加新信息;对消息队列有读权限得进程则可以从消息队列中读取信息。
消息队列提供了一种从一个进程向另一个进程发送一个数据块的方法。 每个数据块都被认为含有一个类型,接收进程可以独立地接收含有不同类型的数据结构。我们可以通过发送消息来避免命名管道的同步和阻塞问题。但是消息队列与命名管道一样,每个数据块都有一个最大长度的限制。
(2)信号量:信号量以保护临界资源为目的,但他本身也是个临界资源;他控制多个进程对共享资源的访问,通常描述临界资源当中,临界资源的数量,常常被当做锁来使用,防止一个进程访问另外一个进程正在使用的资源。
(3)信号:信号是在软件层次上对中断机制的一种模拟,是一种异步通信方式。信号可以直接进行用户空间进程和内核进程之间的交互,内核进程也可以利用它来通知用户空间进程发生了哪些系统事件。如果该进程当前并未处于执行态,则该信号就由内核保存起来,直到该进程恢复执行再传递给它;如果一个信号被进程设置为阻塞,则该信号的传递被延迟,直到其阻塞被 取消时才被传递给进程。
(4)共享内存:信号量以保护临界资源为目的,但他本身也是个临界资源;他控制多个进程对共享资源的访问,通常描述临界资源当中,临界资源的数量,常常被当做锁来使用,防止一个进程访问另外一个进程正在使用的资源。
优点:共享内存区是最快的IPC形式,不同于管道和消息队列等通信方式,它一旦这样的内存映射到共享它的进程的地址空间,这些进程间数据传递不再涉及到内核,换句话说是进程不再通过执行进入内核的系统调用来传递彼此的数据。
3. 套接字(socket):
这是一种更为一般得进程间通信机制,它可用于网络中不同机器之间的进程间通信,应用非常广泛。
9.(操作系统)线程间通信
- 全局变量:通过全局变量进行通信,要对该变量加关键字volatile
volatile(易变的):每次从内存中去读这个值,而不是因编译器优化从缓存的地方读取 - 互斥量:互斥器的功能和临界区域很相似。区别是:Mutex所花费的时间比Critical Section多的多,但是Mutex是核心对象(Event、Semaphore也是),可以跨进程使用,而且等待一个被锁住的Mutex可以设定 TIMEOUT,不会像Critical Section那样无法得知临界区域的情况,而一直死等。
- 信号量:Semaphore的现值代表的意义是目前可用的资源数,如果Semaphore的现值为1,表示还有一个锁定动作可以成功。
- 事件:用事件(Event)来同步线程是最具弹性的了。一个事件有两种状态:激发状态和未激发状态。也称有信号状态和无信号状态。事件又分两种类型:手动重置事件和自动重置事件。手动重置事件被设置为激发状态后,会唤醒所有等待的线程,而且一直保持为激发状态,直到程序重新把它设置为未激发状态。自动重置事件被设置为激发状态后,会唤醒“一个”等待中的线程,然后自动恢复为未激发状态。所以用自动重置事件来同步两个线程比较理想。
10.(计算机网络)TCP和UDP的区别
1、TCP面向连接(如打电话要先拨号建立连接);UDP是无连接的,即发送数据之前不需要建立连接。
2、TCP提供可靠的服务。也就是说,通过TCP连接传送的数据,无差错,不丢失,不重复,且按序到达;UDP尽最大努力交付,即不保证可靠交付。
3、TCP面向字节流,实际上是TCP把数据看成一连串无结构的字节流;UDP是面向报文的。
UDP没有拥塞控制,因此网络出现拥塞不会使源主机的发送速率降低(对实时应用很有用,如IP电话,实时视频会议等)
4、每一条TCP连接只能是点到点的;UDP支持一对一,一对多,多对一和多对多的交互通信。
5、TCP首部开销20字节;UDP的首部开销小,只有8个字节。
6、TCP的逻辑通信信道是全双工的可靠信道,UDP则是不可靠信道。