python3通过scrapy爬取CSDN指定博主的文章
需求背景
CSDN今年上线了“数据观星”的功能,可以看到最多30天的日访问量趋势。
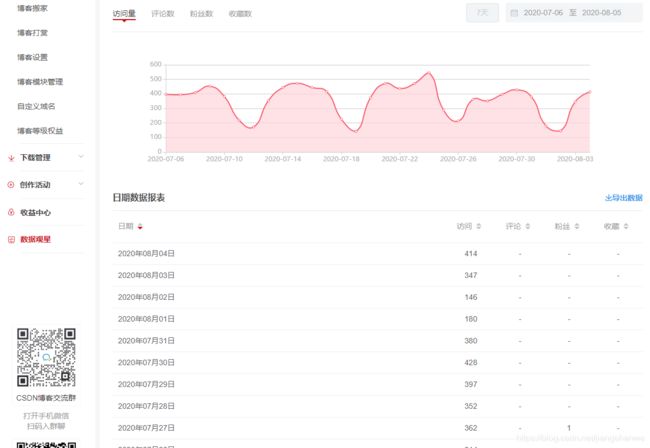
现在想看每一篇文章的日访问情况,只能自己想办法了。于是想到用python来实现这个需求。
每天定时抓取每一篇文章的信息,和前一天阅读数相比,可以计算出前一天的阅读数量,然后存到MySQL数据中,进行下一步的分析。
项目结构
Spider代码
import re
import scrapy
from my_blog.items import MyBlogItem
class CsdnSpiderSpider(scrapy.Spider):
name = 'csdn_spider'
allowed_domains = ['blog.csdn.net']
start_urls = ['http://blog.csdn.net/jiangshanwe']
def parse(self, response):
article_list = response.xpath("//div[@class='article-list']//div[contains(@class, 'article-item-box')]")
for i_item in article_list:
blog_item = MyBlogItem()
blog_item['article_id'] = i_item.xpath(".//@data-articleid").extract_first()
blog_item['type'] = i_item.xpath(".//h4//a//span[1]//text()").extract_first()
blog_item['title'] = i_item.xpath(".//h4//a//text()[2]").extract_first().strip()
# blog_item['content'] = i_item.xpath(".//p[@class='content']//a//text()").extract_first().strip()
blog_item['update_date'] = i_item.xpath(".//span[contains(@class, 'date')]//text()").extract_first().strip()
blog_item['read_count'] = i_item.xpath(".//span[@class='read-num'][1]//text()").extract_first().strip()
blog_item['comments_count'] = i_item.xpath(
".//span[@class='read-num'][2]//text()").extract_first().strip() if i_item.xpath(
".//span[@class='read-num'][2]//text()").extract_first() else 0
yield blog_item
current_page = re.compile(r'var[\s]+currentPage[\s]*=[\s]*(\d*?)[\s]*[\;]').findall(response.text)[0]
page_size = re.compile(r'var[\s]+pageSize[\s]*=[\s]*(\d*?)[\s]*[\;]').findall(response.text)[0]
list_total = re.compile(r'var[\s]+listTotal[\s]*=[\s]*(\d*?)[\s]*[\;]').findall(response.text)[0]
if int(list_total) > (int(current_page) * int(page_size)):
yield scrapy.Request("https://blog.csdn.net/jiangshanwe/article/list/" + str(int(current_page) + 1),
callback=self.parse)
pass
items代码
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class MyBlogItem(scrapy.Item):
# define the fields for your item here like:
article_id = scrapy.Field()
type = scrapy.Field()
title = scrapy.Field()
content = scrapy.Field()
update_date = scrapy.Field()
read_count = scrapy.Field()
comments_count = scrapy.Field()
pass
数据库代码
from sqlalchemy import create_engine, Integer, Column, String
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker
# 创建数据库链接
engine = create_engine("mysql+pymysql://root:[email protected]:3306/csdn_blog?charset=utf8")
# 操作数据库
# 创建session
Session = sessionmaker(bind=engine)
# 声明一个基类
Base = declarative_base()
class ArticleTable(Base):
# 表名称
__tablename__ = 'csdn_article'
id = Column(Integer, primary_key=True, autoincrement=True)
article_id = Column(String(length=20), nullable=True)
type = Column(String(length=40), nullable=True)
title = Column(String(length=255), nullable=True)
update_date = Column(String(length=30), nullable=True)
read_count = Column(Integer, nullable=True) # 当前阅读总数量
comments_count = Column(Integer, nullable=True) # 当前评论总数量
previous_day_read_count = Column(Integer, nullable=True) # 昨天阅读总数量
previous_day_comments_count = Column(Integer, nullable=True) # 昨日评论总数量
previous_day_read_new = Column(Integer, nullable=True) # 昨日新增阅读数量
previous_day_comments_new = Column(Integer, nullable=True) # 昨日新增评论数量
previous_week = Column(Integer, nullable=True) # 昨日星期
# 抓取日期
crawl_date = Column(String(length=30), nullable=False)
crawl_date_time = Column(String(length=30), nullable=False)
if __name__ == '__main__':
# 创建数据表
ArticleTable.metadata.create_all(engine)
Pipeline代码
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from datetime import datetime
from datetime import timedelta
from my_blog.create_table import ArticleTable
from my_blog.create_table import Session
class MyBlogPipeline:
def __init__(self):
# 实例化session
self.mysql_session = Session()
self.current = datetime.today()
self.yesterday = self.current - timedelta(days=1)
def process_item(self, item, spider):
today_query_result = self.mysql_session.query(ArticleTable).filter(
ArticleTable.crawl_date == self.current.strftime('%Y-%m-%d'),
ArticleTable.article_id == item[
'article_id']).first()
if today_query_result:
print('当日已抓取过该篇文章%s:%s:%s' % (item['article_id'], item['title'], self.current))
else:
print('插入文章%s:%s:%s' % (item['article_id'], item['title'], self.current))
previous_day_read_count = 0 # 昨天阅读总数量
previous_day_comments_count = 0 # 昨日评论总数量
previous_day_read_new = 0 # 昨日新增阅读数量
previous_day_comments_new = 0 # 昨日新增评论数量
yesterday_item = self.mysql_session.query(ArticleTable).filter(
ArticleTable.crawl_date == self.yesterday.strftime('%Y-%m-%d'),
ArticleTable.article_id == item[
'article_id']).first()
if yesterday_item:
previous_day_read_count = yesterday_item.read_count
previous_day_comments_count = yesterday_item.comments_count
previous_day_read_new = int(item['read_count']) - (previous_day_read_count or 0)
previous_day_comments_new = int(item['comments_count']) - (previous_day_comments_count or 0)
article = ArticleTable(
article_id=item['article_id'],
type=item['type'],
title=item['title'],
update_date=item['update_date'],
read_count=item['read_count'],
comments_count=item['comments_count'],
crawl_date_time=self.current.strftime('%Y-%m-%d %H:%M:%S'),
crawl_date=self.current.strftime('%Y-%m-%d'),
previous_day_read_count=previous_day_read_count,
previous_day_comments_count=previous_day_comments_count,
previous_day_read_new=previous_day_read_new,
previous_day_comments_new=previous_day_comments_new,
previous_week=int(self.yesterday.strftime("%w"))
)
self.mysql_session.add(article)
self.mysql_session.commit()
return item
settings.py配置
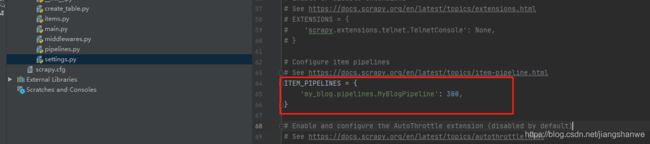
ITEM_PIPELINES配置
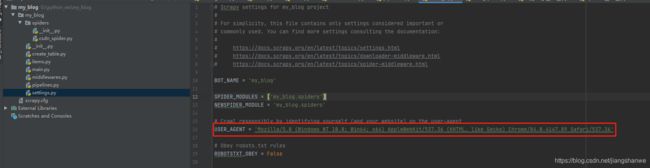
USER_AGENT配置:
最终效果
将工程部署到Linux服务器后,增加定时任务,每天早上6点启动爬虫,并将结果写入到数据库。
数据导出到excel后,使用数据透视表可以快速的查看每篇文章在不同日期的新增访问量
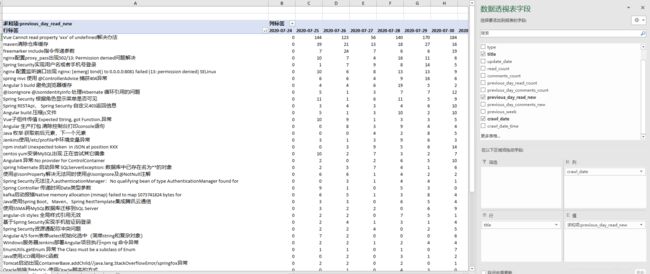
当然,有了这些基础数据后,可以做出更符合自己需求的报表。