- 前言
- 复杂度分析
- 编码
- 常规
- 变种
- 局限性
- 声明
前言
概念:二分查找(Binary Search)算法,一种针对有序数据集合的查找算法,也叫折半查找算法。
思想:二分查找针对的是一个有序的数据集合( 升序或降序 ),查找思想有点类似分治思想。每次都通过跟区间的中间元素对比,将待查找的区间缩小为之前的一半,直到找到要查找的元素,或者区间被缩小为 0
步骤: 定义 low,high,mid指针,分别指向首尾中间 3 个位置,value 是我们要查找的值
进行如下算法
(1)当arr[mid] = value 时,找到则返回 mid下标
(2)当arr[mid] < value 时,说明目标元素在经由mid分割的右区间,故将区间起始位置 low 赋值为mid+1
(3)当arr[mid] > value 时,说明目标元素在经由mid分割的左区间,故将区间结束位置 high 赋值为mid-1
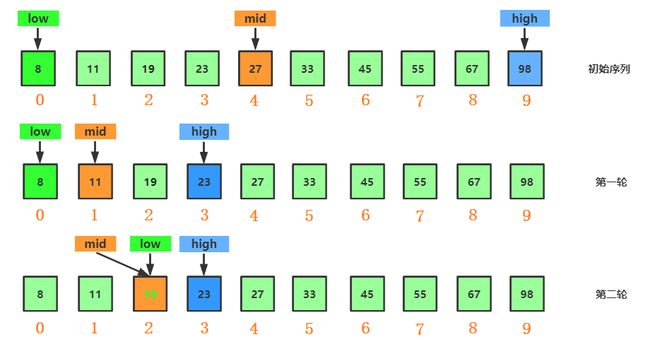
图解:
以有序集合 {8,11,19,23,27,33,45,55,67,98}为例,以查找值 value = 19进行分析
复杂度分析
假设数据规模是 n,每一轮查找数据规模都会缩小一半,也就是会除以2。最好的情况就是,在初始化就找到,最坏情况下,直到查找区间被缩小为空,才停止。
查找的区间变化是 —— $n$、$\frac{n}{2}$、$\frac{n}{4}$、$\frac{n}{8}$、... 、$\frac{n}{2^k}$, 可以看出来,这是一个等比数列。其中 $\frac{n}{2^k}$ = $1$ 时, k 的值就是总共缩小的次数。而每一次缩小操作只涉及两个数据的大小比较,所以,经过了 k 次区间缩小操作,时间复杂度就是 O(k)。通过 $\frac{n}{2^k}$ = $1$ ,我们可以求得 $k$ = $\log_2n$,所以时间复杂度就是 O(logn)
优点:高效的二分查找,拥有惊人的查找速度,因为 logn 是一个非常“恐怖”的数量级,即便 n 非常非常大,对应的 logn 也很小。比如 n 等于 2 的 32 次方,这个数很大了吧?大约是 42 亿。也就是说,如果我们在 42 亿个数据中用二分查找一个数据,最多需要比较 32 次
编码
常规
迭代法实现
/**
* 迭代法实现
* @param arr
* @param value
* @return
*/
public static int binarySerach1(int[] arr, int value) {
//头部指针
int low = 0;
//尾部指针
int high = arr.length - 1;
while (low <= high){
int mid = low + ((high - low) >> 1);
if (arr[mid] == value){
return mid;
}else if (arr[mid] > value){
high = mid - 1;
}else {
low = mid + 1;
}
}
return -1;
}
注意点:
-
循环退出条件:注意是 low <= high,而不是 low < high
-
mid 的取值问题:
-
mid =( low + high)/2这种写法是有问题的。因为如果 low 和 high 比较大的话,两者之和就有可能会溢出 -
改进的方法是将 mid 的计算方式写成
low + (high - low)/2 -
将除法运算改为位运算,因为相比除法运算来说,计算机处理位运算要快得多
-
递归法实现
/**
* 递归法
* @param arr
* @param value
* @return
*/
public static int binarySerach2(int[] arr, int value){
return bsearch(arr,0,arr.length -1,value);
}
private static int bsearch(int[] arr, int low, int high, int value) {
if (low > high) return -1;
int mid = low + ((high - low) >> 1);
if (arr[mid] == value) {
return mid;
} else if (arr[mid] > value) {
return bsearch(arr, low, mid-1, value);
} else {
return bsearch(arr, mid+1, high, value);
}
}
变种
1、查找第一个值等于给定值的元素
上面实现的二分查找算法实比较简单的需求,是有一定局限性的,例如,它是默认元素是不重复的。那么,假设有序结合是存在重复元素的,那么用上面的算法来解决肯定是有问题的。以有序数组{1,3,4,5,6,8,8,8,11,18},其中,a[5],a[6],a[7] 的值都等于 8,是重复的数据。我们希望查找第一个等于 8 的数据,也就是下标是 5 的元素。配图如下:

编码:
public static int binarySerach3(int[] arr, int value) {
int low = 0;
int high = arr.length - 1;
while (low <= high) {
int mid = low + ((high - low) >> 1);
if (arr[mid] > value) {
high = mid - 1;
} else if (arr[mid] < value) {
low = mid + 1;
} else {
if ((mid == 0) || (arr[mid - 1] != value)) return mid;
else high = mid - 1;
}
}
return -1;
}
重点:从第11行代码才是算法的重点,前面的代码和之前的思路是一样的,在第11行代码开始就不同了,我们的需求是查找第一个值等于给定值的元素,那么只要注意两个地方就可以了
mid == 0,这说明找到的值是数组下标 0 位置的值,也就是起点位置,那么肯定就是第一个值了- 如果
mid前一位的值不是要匹配的value,那么说明找到的就是第一个值,否则,high指向mid - 1,重新比较
2、查找最后一个值等于给定值的元素
还是以有序数组{1,3,4,5,6,8,8,8,11,18},其中,a[5],a[6],a[7] 的值都等于 8,是重复的数据。我们希望查找最后个等于 8 的数据,也就是下标是 7 的元素。
编码:
/**
* 查找最后一个值等于给定值的元素
* @param arr
* @param value
* @return
*/
public static int binarySerach4(int[] arr, int value) {
int low = 0;
int high = arr.length - 1;
while (low <= high) {
int mid = low + ((high - low) >> 1);
if (arr[mid] > value) {
high = mid - 1;
} else if (arr[mid] < value) {
low = mid + 1;
} else {
if ((mid == arr.length - 1) || (arr[mid + 1] != value)) return mid;
else high = mid + 1;
}
}
return -1;
}
这个变种的案例与第一个很相似,稍微修改一下第11行后边的代码条件即可,不做详细分析
3、查找第一个大于等于给定值的元素
我们再来看另外一类变形问题。在有序数组中,查找第一个大于等于给定值的元素。比如,数组中存储的这样一个序列:{3,4,6,7,10},如果查找第一个大于等于 5 的元素,那就是 6。
编码:
/**
* 变种三: 查找第一个大于等于给定值的元素
* @param arr
* @param value
* @return
*/
public static int binarySerach3(int[] arr, int value) {
int low = 0;
int high = arr.length - 1;
while (low <= high) {
int mid = low + ((high - low) >> 1);
if (arr[mid] >= value) {
if ((mid == 0) || (arr[mid - 1] < value)) return mid;
else high = mid - 1;
} else {
low = mid + 1;
}
}
return -1;
}
重点:该变种也是寻找的第一个的值,同变种一的查找逻辑是一样的,只是将匹配值value改成查找比比值value大的,将arr[mid] >= value统一处理
4、查找最后一个小于等于给定值的元素
仍然以有效序列{3,4,6,7,10}为例,查找最后一个小于等于给定值的元素,如果给定值是5,那查找处理的就是就是 4。
/**
* 变种四: 查找第一个大于等于给定值的元素
* @param arr
* @param value
* @return
*/
public static int binarySerach4(int[] arr, int value) {
int low = 0;
int high = arr.length - 1;
while (low <= high) {
int mid = low + ((high - low) >> 1);
if (arr[mid] > value) {
high = mid - 1;
} else {
if ((mid == arr.length - 1) || (arr[mid + 1] > value)) return mid;
else low = mid + 1;
}
}
return -1;
}
思路和上面的大致一样,就不作分析了
局限性
二分查找的时间复杂度是 O(logn),查找数据的效率非常高。不过,并不是什么情况下都可以用二分查找,它的应用场景是有很大局限性的。那什么情况下适合用二分查找,什么情况下不适合呢?
1、二分查找依赖的是顺序表结构,简单点说就是数组
那二分查找能否依赖其他数据结构呢?比如链表。答案是不可以的,主要原因是二分查找算法需要按照下标随机访问元素。我们在数组和链表那两节讲过,数组按照下标随机访问数据的时间复杂度是 O(1),而链表随机访问的时间复杂度是 O(n)。所以,如果数据使用链表存储,二分查找的时间复杂就会变得很高。
2、二分查找针对的是有序数据
二分查找对这一点的要求比较苛刻,数据必须是有序的。如果数据没有序,我们需要先排序。排序的时间复杂度最低是 O(nlogn)。所以,如果我们针对的是一组静态的数据,没有频繁地插入、删除,我们可以进行一次排序,多次二分查找。这样排序的成本可被均摊,二分查找的边际成本就会比较低。
所以,二分查找只能用在插入、删除操作不频繁,一次排序多次查找的场景中。针对动态变化的数据集合,二分查找将不再适用。
3、数据量太小不适合二分查找。
如果要处理的数据量很小,完全没有必要用二分查找,顺序遍历就足够了。比如我们在一个大小为 10 的数组中查找一个元素,不管用二分查找还是顺序遍历,查找速度都差不多。只有数据量比较大的时候,二分查找的优势才会比较明显。
不过,这里有一个例外。如果数据之间的比较操作非常耗时,不管数据量大小,我都推荐使用二分查找。比如,数组中存储的都是长度超过 300 的字符串,如此长的两个字符串之间比对大小,就会非常耗时。我们需要尽可能地减少比较次数,而比较次数的减少会大大提高性能,这个时候二分查找就比顺序遍历更有优势。
4、数据量太大也不适合二分查找。
二分查找的底层需要依赖数组这种数据结构,而数组为了支持随机访问的特性,要求内存空间连续,对内存的要求比较苛刻。比如,我们有 1GB 大小的数据,如果希望用数组来存储,那就需要 1GB 的连续内存空间。
注意这里的“连续”二字,也就是说,即便有 2GB 的内存空间剩余,但是如果这剩余的 2GB 内存空间都是零散的,没有连续的 1GB 大小的内存空间,那照样无法申请一个 1GB 大小的数组。而我们的二分查找是作用在数组这种数据结构之上的,所以太大的数据用数组存储就比较吃力了,也就不能用二分查找了。
声明
参考资料:王争 —《数据结构与算法之美》 、 排序的最低时间复杂度为什么是O(nlogn)
文章为原创,欢迎转载,注明出处即可
个人能力有限,有不正确的地方,还请指正
本文的代码已上传github,欢迎star —— GitHub地址