数据结构 : 顺序表和链表
顺序表
- 顺序表: 空间连续、支持随机访问、物理上是连续的
- 概念:顺序表是用一段物理地址连续的存储单元依次存储数据元素的线性结构,一般情况下采用数组存储。在数组上完成数据的增删查改。
- 顺序表一般可以分为:
静态顺序表:使用定长数组存储
动态顺序表:使用动态开辟的数组存储
// 顺序表的静态存储
#define N 100
typedef int SLDataType;
typedef struct SeqList
{
SLDataType array[N]; // 定长数组
size_t size; // 有效数据的个数
}SeqList;
// 顺序表的动态存储
typedef struct SeqList
{
SLDataType* array; // 指向动态开辟的数组
size_t size ; // 有效数据个数
size_t capicity ; // 容量空间的大小
}SeqList;
- 接口实现
静态顺序表只适用于确定知道要存储多少数据的场景。空间开辟的大小不好控制,容易浪费或不够用。 因此,现实中基本都使用动态顺序表,根据需要动态的分配空间大小。
SeqList.h
# pragma once //防止被包含多次,多次展开
#include SeqList.c
#include "SeqList.h"
#include 缺点:
1、在头部或者中间插入、删除数据时,效率很低,(需要挪数据,然后插入或者覆盖),删除时间复杂度是O(N)
2、增容
代价大(开一个更大的空间,再拷贝过去,释放旧空间)
浪费空间(两倍增长:100个数据,若需要插入第101个数据,就会浪费99的空间)
链表
-
概念:链表是一种物理存储结构上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。
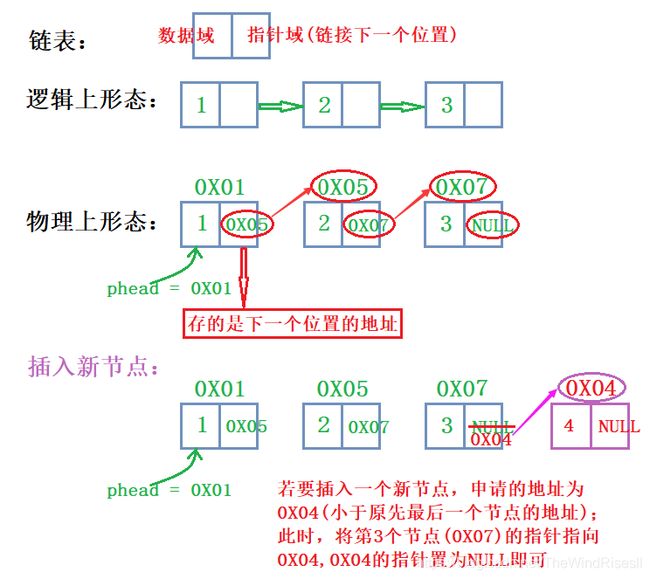
-
链表物理上不是连续的,独立的,用指针可以链起来
-
链表有数据域、指针域(链接下一个位置),直至指针为空即结束,前一个节点存储的是下一个节点的地址 ; 用一个申请一个,没有空间浪费
-
单向链表 :前面一个节点可以找到后一个节点,后一个节点不能找到前一个节点
劣势 :从后往前不好找,以节点为单位存储,不支持随机访问 -
双向链表
不带头:从第一个节点开始就是有效节点
带头:第一个节点占位,接下来才是有效节点
循环、不循环… (八种) -
无头单向非循环链表: 结构简单,一般不会单独用来存数据。实际中更多是作为其他数据结构的子结构,如哈希桶、图的邻接表等等。另外这种结构在笔试面试中出现很多
-
带头双向循环链表: 结构最复杂,一般用在单独存储数据。实际中使用的链表数据结构,都是带头双向循环链表
尾插
- 先开辟一个新的空间存储将要插入的节点(newnode),然后判断待插入的节点(plt)是否为空,若为空,找第一个节点_head,直接把plt->_head指向新节点即可;若不为空,找最后一个节点,引入节点cur,cur去找链表plt的最后一个节点,没找到之前,cur依次往后找,cur = cur->_next ;直至cur->_next == NULL 时就找到了最后一个节点,再把最后的节点指向新节点(newnode)即可
void SListPushBack(SList* plt, SLTDateType x)
{
assert(plt);
//先申请内存空间
SListNode* newnode = (SListNode*)malloc(sizeof(SListNode));
newnode->_data = x;
newnode->_next = NULL;
//1.为空
if (plt->_head == NULL)
{
plt->_head = x;
}
//2.不为空
else
{
SListNode* cur = plt->_head;
while (cur->_next != NULL)
{
cur = cur->_next;
}
cur->_next = newnode;
}
}
头插
- 注意插入新节点的时候,不能直接用头指向新节点,如果这么干的话,那么头节点里原先存储的第一个节点的地址就找不到了,因此头插时一定要注意这一点!!!
- 先将新节点的_next指向原来的第一个节点的地址(头节点存的就在原来的第一个节点的地址);在把头节点指向新节点即可
void SListPushFront(SList* plt, SLTDateType x)
{
assert(plt);
SListNode* newnode = (SListNode*)malloc(sizeof(SListNode));
newnode->_data = x;
newnode->_next = NULL;
//空不空均如此
newnode->_next = plt->_head; //第一个节点的地址存储在头里(plt->_head)
plt->_head = newnode;
}
头删
- 设cur指向第一个节点、cur->_next指向第二个节点;将_head指向第二个节点(cur->_next),把第一个节点删除即可
void SListPopFront(SList* plt, SLTDateType x)
{
assert(plt);
if (plt == NULL)
{
return;
}
else
{
SListNode* cur = plt->_head;
plt->_head = cur->_next;
free(cur);
cur = NULL;
}
}
尾删
+找尾:cur->_next->_next == NULL (不能直接将最后一个置为空,这样容易造成原链表倒数第二个节点的_next存在野指针的问题)
- 如果链表为空,则没什么可删的,直接返回即可;
- 如果链表只有一个节点,则删除这个节点即可,然后把plt->_next置为空,防止野指针
- 如果有多个节点,则可以借助cur->_next->_next找到最后一个节点,删除最后一个节点,再把倒数第二个节点的_next置为空,防止野指针
void SListPopBack(SList* plt, SLTDateType x)
{
assert(plt);
SListNode* cur = plt->_head;
//为空节点
if (cur == NULL)
{
return;
}
//只有一个节点,刚好删除它
else if (cur->_next == NULL)
{
free(cur);
plt->_head = NULL;
}
//多个节点
else
{
while (cur->_next->_next != NULL)
{
cur = cur->_next;
}
free(cur->_next);
cur->_next = NULL;
}
}
//C++库里,双向链表-list/单链表-forward_list
//单链表的头插头删时间复杂度均为O(1),这是常用的,比如哈希表里的应用
//单链表缺陷偏多,出的题目比较多,陷阱多一些
//头插用双向链表更容易解决;单链表常用于在节点的后面插入
void SListFind(SList* plt, SLTDateType x)
{
assert(plt);
SListNode* cur = plt->_head;
while (cur != NULL)
{
if (cur->_data = x)
{
return cur;
}
cur = cur->_next;
}
return NULL;
}
//newnode得先指向pos的下一个位置,然后pos再指向newnode
void SListInsertAfter(SListNode* pos,
SLTDateType x)
{
assert(pos);
SListNode* newnode =
(SListNode*)malloc(sizeof(SListNode));
newnode->_data = x;
newnode->_next = NULL;
newnode->_next = pos->_next;
pos->_next = newnode;
}
void SListEraseAfter(SListNode* pos)
{
assert(0);
if (pos->_next == NULL)
{
return;
}
else
{
SListNode* next = pos->_next;
pos->_next = next->_next;
free(next);
next = NULL;
}
}
//删除目标值
void SListRemove(SList* plt, SLTDateType x)
{
assert(plt);
SListNode* prev = NULL;
SListNode* cur = plt->_head;
while (cur != NULL)
{
if (cur->_data == x)
{
if (prev == NULL) //头删(cur->_data == x)
{
plt->_head = cur->_next;
}
prev->_next = cur->_next;
free(cur);
cur = NULL;
return;
}
else
{
prev = cur;
cur = cur->_next;
}
}
}
【小结】
-
链表:以节点为单位存储,不支持随机访问,从后往前不好找。 任意位置插入删除时间复杂度为O(1)
-
链表是一种常见的基础数据结构,是一种线性表,但是并不会按线性的顺序存储数据,而是在每一个节点的里存到下一个节点的指针。
-
由于不是必须按照顺序存储的,链表在插入的时候可以达到O(1)的复杂度,比另一种线性表——顺序表快多,但是查找一个节点或者访问特定编号的节点则需要O(N)的时间,而顺序表相应的时间复杂度分别是O(log n)、O(1)
-
链表结构可以克服数组链表预先知道数据大小的缺点,链表结构可以充分利用计算机内存空间,实现灵活的内存动态管理,但是链表失去了数组随机读取的优点,同时链表由于增加了结点的指针域,空间开销比较大
-
链表允许插入和移除表上任意位置上的节点,但是不允许随机存取。链表有很多种不同类型:单向链表、双向链表、循环链表
-
链表还可以衍生出循环链表、静态链表、双链表等。对于链表使用,需要注意头结点的使用。