汇编程序设计与计算机体系结构软件工程师教程笔记:其它架构
《汇编程序设计与计算机体系结构: 软件工程师教程》这本书是由Brain R.Hall和Kevin J.Slonka著,由爱飞翔译。中文版是2019年出版的。个人感觉这本书真不错,书中介绍了三种汇编器GAS、NASM、MASM异同,全部示例代码都放在了GitHub上,包括x86和x86_64,并且给出了较多的网络参考资料链接。这里只摘记了MASM和NASM,测试代码仅支持Windows和Linux的x86_64。
10. 与处理器及体系结构有关的高级话题
10.2 处理器与系统的性能
系统寄存器:包括下面几组:
(1).控制寄存器(control register):用来表示处理器的模式以及与当前正在执行的任务有关的一些特征:cr0至cr4,其中cr1暂时保留不用;cr8寄存器,也叫作任务优先级寄存器(task priority register, TPR),用来安排外部中断的优先顺序,该寄存器只在64位模式下使用。
(2).内存管理寄存器(memory-management register):用来指出保护模式的描述符表所在的位置:gdtr(Global Descriptor Table Register):全局描述符表寄存器;ldtr(Local Descriptor Table Register):局部描述符表寄存器;idtr(Interrupt Descriptor Table Register):中断描述符表寄存器;tr(Task Register):任务寄存器。
每一个内存管理寄存器都有对应的加载及存储指令,上面的4个寄存器可以分别通过LGDT/SGDT、LLDT/SLDT、LIDT/SIDT及LRT/STR来加载或存储。其中的加载指令仅供系统软件使用,以便将描述符表的线性内存地址载入相应的寄存器。存储指令同样是供系统软件使用的,不过,应用软件在确有必要的时候也可以使用这些指令。
(3).特定于机器的寄存器(Machine-specific register, MSR):用来控制并报告处理器的执行情况。其中某些寄存器与系统调用有明确的关系。
段寄存器(segment register)是一种16位宽的寄存器,代码段(code segment)、数据段(data segment)、栈段(stack segment)以及附加段(extra segment)都有对应的段寄存器,分别称为cs、ds、ss、es,此外,还有两个通用的段寄存器叫做fs与gs,这两者是由Intel 80386所添加的。es是执行MOVS、CPMS及SCAS等字符串操作时默认使用的段寄存器,而fs与gs的用途则没有明确为硬件所定义。
处理器模式:在整个x86时代,处理器模式都随着指令集与系统机能而逐渐演化。下表列出了x86/x86_64所支持的主要几种处理器模式,并写出了首个支持该模式的处理器,以及此模式能够在多大的内存空间中寻址。除了这几种模式外还有其它一些模式,例如系统管理模式以及虚拟8086模式。Intel的开发文档,经常把长模式称为IA-32e。

Intel 8086是一款支持x86指令集的16位处理器,它运行在实模式下,这意味着软件能够直接访问物理内存空间、I/O通道以及周边硬件。之所以不限制访问是因为软件有时要直接与硬件沟通,例如在系统启动的时候。
当前的x86及x86_64处理器为了保持向后兼容,确实会以实模式来发起boot流程,但是很快就会切换到保护模式或长模式。这些处理器大多通过UEFI来配置硬件,不过,也可以用老式的BIOS方式来配置。
从Intel 80286开始,所有的x86处理器都支持保护模式,这也是32位x86系统的默认模式。Intel 80386完善了该模式并解决了存在的问题。当前的处理器所支持的保护模式正是从386演化而来的。
AMD Opteron处理器支持长模式,从而可以使用x86_64指令集中的指令以及与之相关的寄存器。该模式必须搭配64位操作系统。长模式之下有几种小模式(sub-mode, 子模式),其中64位模式(64-bit Mode)适用于64位程序,而兼容模式(Compatibility Mode)则是一种增强版的保护模式,适用于32位及16位程序。在不使用长模式的情况下,x86_64处理器是可以支持实模式及保护模式的。
内存模型:计算机系统所用的内存模型要根据可以使用的处理器模式以及操作系统的支持情况来决定。常见的两种模型叫做分段(segmented)模型及平面(flat)模型。分段内存模型会把地址空间分成不同的区段或者说段落,以供程序中的各个部分使用,例如数据可以放在一个区段中,代码可以放在另一个区段中。这种模型通过段基址加偏移量的方式来指定内存地址。平面内存模型会把整个内存空间展示成一块连续的区域以供开发者及程序来使用,这种模型也叫做线性(linear)模型。所有的内存地址都是直接以它在线性空间中的位置来确定的,而不通过段与段中的偏移量确定。大多数计算机架构都采用平面内存模型,而x86架构则在这两种模型之间摇摆。
这两种模型的目标都是把逻辑地址(也就是抽象的引用)映射成物理地址(也就是实际的位置)。对于x86来说,16位系统使用分段内存模型,实模式下的32位系统也是如此。保护模式下实际使用的同样是分段模型,但看起来却跟平面模型一样。x86_64使用平面内存模型。
x86在32位保护模式下的寻址方式与实模式既有相似之处又有所不同。首先,它用的还是分段内存模型,但由于引入了一些抽象机制,因此整个内存空间看上去好像是个线性的模型。其中一种抽象机制是描述符,另一种是分页。
当前很多x86处理器都是从实模式开始运行的,但很快就会切换到保护模式。在启动过程中系统会设定描述符,例如中断描述符表(Interrupt Descriptor Table, IDT)、全局描述符表(Global Descriptor Table, GDT)、局部描述符表(Local Descriptor Table, LDT)、任务状态段(Task State Segment, TSS)描述符,以及一个代码段描述符(Code Segment Descriptor)与一个数据段描述符(Data Segment Descriptor)。其中,GDT与LDT是用来详细描述内存段的数据结构,可以指出内存段的基址、大小与访问权限。GDT针对的是全局及共享区段,而每个运行中的程序/进程则有其各自的LDT可以使用。TSS用来存放任务所涉及的寄存器值、I/O权限及栈指针,以便支持多任务处理(multitasking, 尤其是暂停及切换任务)。
指令指针寄存器(ip/eip)指向处理器即将获取并加以执行的下一条指令所在的地址。然而x86的ip/eip中所保存的这个地址实际上是个针对代码段而言的偏移量,因此必须把该值与cs结合起来才能够确定处理器获取指令时所依据的实际地址,也就是说要根据cs:ip/cs:eip来判断。其中,cs是代码段的段选择器,ip/eip是以偏移量形式所表示的指令地址。
分页技术给x86系统的地址转换过程又添加了一层抽象机制。当前的各种操作系统都在使用分页机制,这意味着cr0的PG位(也就是31号位)处于置位状态(其值是1)。启用分页之后,系统要通过cr3寄存器把线性虚拟地址(linear virtual address)转换成物理地址。cr3中有一个字段用来保存当前任务的首个页目录所在的物理地址。
32位的x86采用多级分页机制。它的页面(page, 页)大小一般是4KB,在系统中以连续内存空间的形式出现。如果开启了(Page Size Extension, 页面大小扩展)也就是cr4寄存器的4号位,那么系统就支持2MB及4MB的页面。页表(page table)是含有1024个元素的数组,其中每个元素都占据32个二进制位,这意味着整个页表的大小是4KB,刚好可以放入内存页面中。页表里的每个元素都指向某个页面所在的物理地址。在页面与页表之上还有一种更大的结构叫做页目录(page directory),是个包含1024个元素的数组,而且其中的每个元素同样占据32个二进制位,这些元素均指向某个页表所在的物理地址。下图演示了x86分页机制的结构安排以及32位虚拟地址的解读方式:

系统获取到某个虚拟地址之后,要按照下列方式来确定数据的物理位置。首先,根据cr3找到当前页目录的基址。然后把虚拟地址的高10位(也就是22至31号位)当成索引,在页目录中查找与该索引相对应的元素,并根据该元素的取值找到对应的页表所在的基址。接下来,把虚拟地址的中间10位(也就是12至21号位)当成索引,在页表中查找与该索引相对应的元素,并根据该元素的取值找到对应的内存页面所在的基址。最后,把虚拟地址的低12位(也就是0至11号位)当成索引,在页面中查找与该索引相对应的元素,这个元素正是虚拟地址所指代的那份数据。
这种32位的虚拟地址使得4GB(也就是2^32个字节)的内存空间可以当成一个平面的模型来用,从而令程序数据能够以页面文件的形式出现在该空间中。系统会按照相应的方式解读虚拟地址,并结合cr3寄存器的内容确定其物理地址。页面文件保存在辅助存储器中,并按需移动到主存及缓存中。如果要找的数据不在主存或缓存里,那么就称为页缺失(page fault),此时系统会从辅助存储器中获取相应的页面。启用了分页机制之后,分段就显得不那么重要了,因为每个程序都有自己的空间可以使用,而且能够以虚拟地址的形式引用该空间中的每个位置。
分页对于程序和用户来说是透明的。在启用了分页的平面模型中,虚拟地址当成线性地址空间中的线性地址来看待。这样的线性空间会分成不同的页面,这些页面会与物理内存中的帧(frame)对应起来(这些帧是用来保存页面的)。
64位的x86_64架构在寻址的时候几乎完全抛开了分段机制。长模式下是不进行分段的,而那些段寄存器在这种模式下的用法也各有不同。cs、ds、ss与es寄存器,要么强行设为0x0h,要么当成零来对待(也就是说,无论取什么值,一律视为0),同时可寻址的空间也由2^32上升到2^64,这使得代码、数据与栈都可以出现在一个平面的地址空间中。x86_64的分页机制在原有的三层结构上又加了一层。此时的cr3不直接指向页目录,而是指向页目录指针表(page directory pointer table),系统会通过该表中的元素(或者说指针)来确定对应的页目录所在的位置。查询页表与查询页目录时所用的索引都从10位降成了9位,多出来的这两位正是用来查询指针表的。
10.3 中断与系统调用
软件中断:中断(interrupt)是针对处理器而发的信号,用来表示某种必须立刻予以关注的情况。它可以分为硬件中断与软件中断两大类。软件中断(software interrupt, 软中断)的一种形式是应用程序主动给处理器发信号,可以通过很多办法来实现,例如可以用INT指令明确地产生软件中断。还有一种形式叫做异常(exception)或陷阱(trap),这表示处理器在执行指令的过程中遇到了某种状况,而当前正在运行的应用程序却没有处理或不能处理该状况。
硬件中断(hardware interrupt):也会给处理器发信号,但这个信号并不是由软件发出的,而是由某个与系统相通信的设备通过中断请求线(interrupt request line, IRQ line)所发。IRQ line使得处理器能够与硬件设备相通信。处理器用一些号码来表示通过IRQ line所发出的硬件中断。这些IRQ line是用可编程的中断控制器(Programmable interrupt controller, PIC)连接到处理器上的。
通过INT进行系统调用(旧方法):明确地通过中断来执行任务是一种老式的做法,用于在16/32位x86系统中完成某些工作,他们都通过INT指令来执行系统调用。系统调用(system call)是向操作系统内核(operating system kernel)所发出的请求,旨在使系统完成某件事情。有些情况下,这种请求是通过API发出的,例如Windows系统就是这样。32位的Unix/Linux系统通过int 80h做系统调用,Microsoft Dos用的是int 21h,后续版本的Windows(例如Windows 2000、Windows XP)用的是int 2Eh。
通过int 80h处理系统调用时,遵循如下流程:
(1).执行INT指令;
(2).处理器把运行级别从PL3(应用程序级别)切换到PL0(内核级别);
(3).通过IDT(Interrupt Descriptor Table, 中断描述符表)中的相关描述符找到与INT 80h对应的例程;
(4).把控制权交给内核,以便处理由系统调用号(system call number)所表示的请求;
(5).处理该请求;
(6).将优先级重新设为PL3;
(7).把控制权返还给调用INT指令的程序。
通过SYSENTER、SYSCALL及程序库/API进行系统调用(新方法):SYSENTER与SYSEXIT指令以及SYSCALL与SYSRET指令,并不像CALL与RET指令那样是调用与返回的关系,而是用来在PL0与PL3之间切换。
系统调用的处理方式经常在变化,就连同一个操作系统的不同版本之间可能都会有所区别,甚至在操作系统与版本均相同的情况下,也还是有可能因为各种各样的细节而产生差异。
INVOKE命令可以在32位版的MASM代码中使用,但是不能用在64位版的MASM代码中。如果要针对Microsoft x64编程,那么必须先把参数放入适当的位置,然后通过CALL指令来实现系统调用。
尽量通过程序库或API来执行系统调用而不要直接使用汇编指令。这样做有两大优势:代码写起来更为一致,而且便于移植。
各平台以及同一个平台的不同版本可能会用不同的方式来提升系统调用的速度。总之,系统例程会以很多种方式加以抽象,而且抽象方式也在逐渐变化。
11. 其它架构
11.2 CISC与RISC:指令集架构通常可以分为复杂与精简两种。复杂指令集(Complex Instruction Set Computing, CISC)架构中的指令长度不一。之所以称为复杂指令集,是因为某条指令可能会执行多项任务(例如既访问内存中的某个位置又执行算术运算)。反之,精简指令集(Reduced Instruction Set Computing, RISC)架构中的指令长度通常都一样,而且每条指令只执行一项任务(例如要么访问内存中的某个位置,要么将两个寄存器相加,但不会身兼二职)。
这种把运算操作(例如加法ADD)与内存访问相分离的设计叫做加载/存储设计(load/save design)。RISC架构采用的就是这种设计,这意味着它必须用专门的指令将操作数载入内存,或是将其保存到内存中。例如要想执行ADD运算,首先必须从内存中获取操作数并将其放在寄存器中,然后把两个寄存器相加,最后将结果放回内存。这种设计实际上使得RISC系统的寄存器比CISC系统更多,由于它的静态RAM较多而动态RAM较少,因此可以节省空间及耗电量,这很适合用在移动设备与嵌入式设备中。
CISC采用的不是加载/存储设计,因为它的操作指令还有可能要负责访问内存。仍然以ADD运算为例,CISC指令集中用来执行该运算的指令可以把某个寄存器中的操作数与内存中某个位置上的操作数直接相加。由于CISC处理器会频繁地访问动态内存,因此高速缓存就显得相当重要,只有把它做好才能提升速度与效率。在当前的架构设计中,RISC与CISC都通过大量的晶体管来实现解码器、逻辑单元及微码(microcode)机制。微码是一种依照具体的处理器而设定的逻辑,通常位于预留的高速内存中。它会把机器指令与系统操作翻译成一系列电路级的操作。微码可以视为一个经过编程的层,它定义了某条指令究竟应该怎样在硬件上执行。CISC与RISC架构的例子如下表所示:

如果不考虑指令流水线这一因素,那么RISC与CISC系统之间的区别主要体现在指令长度与内存访问上。前者的指令长度是固定的而且大多数指令会在一个时钟周期内执行完毕,而后者的指令长度则不固定,由于指令较为复杂,因此许多指令要花费多个时钟周期才能执行完。这是理论上的差别,从实际角度来看,由于这两种处理器均会运用一些增强技术,因此它们在同一个时钟周期内其实都是可以执行多条指令的。
精简指令集不一定意味着指令的数量少,而复杂指令集也不一定意味着指令的数量多。RISC系统倾向于减少专门针对某种数据类型的指令。CISC系统通常会用专门的指令来支持字符串等更为复杂的数据类型。
11.3 更多架构:
ARM:本来是Acorn RISC Machines的缩写,但现在已经成了ARM Holdings公司的名字。该公司研发了多种RISC处理器架构。
ARM架构有三个不同的profile(配置):Application(A, 应用)、Realtime(R, 实时)及Microcontroller(M, 微控制器)。A系列的profile最为流行,32位与64位处理器中都有采用这种profile的产品,用在运行用户应用程序的设备上。R系列都是32位处理器,这种profile适合用在实时的,或者对安全要求很高的系统中,例如交通工具与医疗设备。M系列也是32位的,这种profile适用于单片机,通常出现在Arduino及NXP生产的单片机板上。
x86架构的处理器有保护模式与长模式之分,与之类似,ARM处理器也可以运行在各种模式下。其中用户模式主要给非特权的处理任务使用,此外还有10种特权模式用来执行中断及异常等任务。大多数ARM处理器都采用”获取(fetch)--解码(decode)--执行(execute)”这样的传统三阶段流水线,不过,最近出现的几种版本,如ARM8与ARM9,装配有更为复杂的流水线。
ARM处理器支持哪些寄存器,要看它的核心是32位还是64位,此外还要看是否支持Thumb指令集(一种采用16位编码的ARM指令集)以及它使用的是哪种VFP(Vector Floating-Point unit, 向量浮点运算单元)。下面给出用户模式中两套最为常见的组合:
(1).AArch32:16个32位的寄存器r0~r15,其中r13用作栈指针(Stack Pointer, SP),r14用作链接寄存器(Link Register, LR),用来保存函数调用的返回地址,r15用作程序计数器(Program Counter, PC)。此外还有一个32位的寄存器叫做当前程序状态寄存器(Current Program Status Register, CPSR),其中包含一些与处理器管理有关的二进制位以及一些与算术有关的标志。许多32位ARM核心都配有这样一种VFP,它有16个或32个64位的浮点寄存器,可以存放单精度或双精度值。
(2).AArch64:31个64位的通用寄存器x0~x30,它们的32位形式为w0~w30,其中w29用作帧指针(Frame Pointer, FP),x30用作LR。此外还有专门的SP寄存器、PC寄存器,以及32个128位的FPU寄存器。同时使用Advanced SIMD extension(也被称为NEON)指令集,支持8位、16位、32位及64位的整数,此外也支持单精度及双精度SIMD运算。
尽管AArchh64的内存空间与地址都是64位,但指令依然是32位的。其中的操作数可以是32位也可以是64位。不同的ARM核心可能会采用不同的设计方案与增强技术。
AVR:是一种高级的(增强的)8位RISC架构,它由Atmel所开发。AVR是把程序与数据分别存放在两块内存中 。它的所有内存空间都呈线性排布(内存空间是平面的)。
RISC-V:是一种开源的RISC架构。它的指令集用的是可伸缩的地址空间(例如可以是32位、64位或128位),其指令编码的长度也同样可以伸缩。
System-z/Architecture:IBM,采用CISC设计。
11.4 量子架构(quantum architecture):量子系统所使用的能源却是光子能这样更为基本的能源,这些光子是离散量,也可以说是量子。于是,量子架构指的就是根据基本粒子来构建信息单位和通信单位的架构。量子架构的信息单位是量子位(qubit),它是量子数位。
12. 硬件与电子元件
12.2 电学基础:
基本的物理量:包括电流(current)、电压(voltage)、电功率(power)以及电阻(resistance)。这些基本的物理量及其单位如下表所示:

电流可以定义成电子通过某个点的速度。用安培(Ampere, Amp)做电流的单位可以更好地描述它的强度(intensity)。安培数越大,意味着通过导线的电子流动得越快。通过某个点的电流为1安培,意味着每秒钟大约有6.24*10^18个电子通过该点。
电压指的是两个点之间的电位差,有的时候也叫做电势差(electrical potential difference),它的单位是伏特(Volt)。
功率是电流所做的总功,单位是瓦特(Watt, 简称瓦)。电功率与电压及电流的关系:P=I*E。
电阻是电流因为材料、环境或元件等因素而受到的阻碍。由于现实中的导体都不完美,因此,电能总会在传输过程中有所流失。不过,某些情况下可能会人为地提升电阻,以确保某个元件的电能可以达到必要的水平。电阻的单位是欧姆(Ohm, 简称欧)。欧姆定律:E=I*R。
电通常以两种形式输送,这就是交流(alternating current, AC)和直流(direct current, DC)。墙上的插座输出的一般是交流电,它的电流方向总是不停地改变。大多数电子设备所用的电是直流电,它通常用正电压来表示。交流电之所以成为家庭用电的标准形式,是因为它的传输效率较高(三相交流电采用较小的中性导线,减轻了发电机与电动机的摩擦,并且也无须设计复杂的电动机)而成本较低。
12.3 电子元件:
供电设备:要把插座输出的120V交流电输送给需要在适当的直流电压下工作的各种计算机设备,就必须改变电流的形式。这项电流处理工作由两个电子元件负责,它们都位于计算机的电源供应器中,无论是台式机的电源盒还是笔记本电脑用的类似砖块的电源都具备这样两个元件。这就是变压器(transformer)与整流器(rectifier)。
变压器:是一种通过电磁感应(electromagnetic induction)来提升或降低交流电压的元件,它把120V的电压降低到计算机内部元件能够承受的程度。电源供应器通常包含两个或三个变压器,用来降低各种信号的电压,使得计算机内部的元件都能够得到各自所要求的电力。
电压降低后,需要用另一个元件将其从交流变为直流,这个元件就是整流器,它使得电流只朝着一个方向流动。除此之外它还有另一项职能,就是确保电流不会反向流动。
逆变器的功能与变压器相反,它是把直流电转换成交流电。
电阻器:由于导线与电容都不可能用完全理想的材料来制作,因此,任何电路中都有电阻。某些电路还需要进一步降低电流,因此会人为地增加电阻。这种减缓电子流动的元件叫做电阻器(resistor)。电阻器的电阻值各有不同。这些值以欧姆为单位,并通过电阻器上的色环(color band)来表示。典型的电阻器标有4个色环。与电池一样,电阻或其它元件之间也可以串联或并联。串联时电流不变,电压等于各电阻的电压之和,并联时电压不变,电流等于各电阻的电流之和。还有一种电阻器是可变电阻器,它也经常称为电位器,这种电阻器的电阻是可以改变的。
二极管:控制电流方向以防其回流的元件就是二极管(diode)。二极管的原理是:它在其中一个方向上具备低电导(conductance)或零电导,而在另外一个方向上则具备高电导或无穷电导。也可以换一种说法,从电阻的角度来描述:它在其中一个方向上具备高电阻或无穷电阻,而在另外一个方向上则具备低电阻或零电阻。
电容器(capacitor):是一种临时存储电荷的元件。电路中的电容器通常用来过滤电流。它的另一项功能是用来确保:无论电力来源是否稳定(例如是否会突降或激增),电路中的下一个元件总能获得适当的电压。由于很多电子元件都对功率波动较为敏感,因此需要由电容器来减缓这种波动,以延长这些元件的寿命。只要电容器中还有电荷(也就是电子还未耗尽),就能够起到稳定功率的作用。由于不同的电子元件需要的电压不一样,因此电容器也分为很多种。它们要按照存储电子的能力,也就是电容量(capacitance)来划分。
晶体管(transistor):这是一种可以当作信号放大器或开关来用的元件,当代的电子设备都在这种基本元件的基础上构建而成。目前的计算机所使用的晶体管是由硅制作的。晶体管的三个极(terminal)叫做基极(base)、发射极(emitter)、集电极(collector)。给基极通电可以令发射极与集电极之间形成通路,从而使电流得以通过。放大程度与施加给基极的电压成正比。晶体管的发射极与集电极之间有时导电有时不导电,这种特性,就是半导体(semiconductor, semi-前缀表示”半”)一词的来源。
12.4 集成电路:把前面的那些电子元件合起来可以构成电路,以完成某种任务。
以下测试代码是通过CPUID指令来判断个人机上的处理器是否支持某些指令功能:
int test_cpuid()
{
// reference: https://github.com/brianrhall/Assembly/tree/master/Appendices/Appendix_G_Using%20CPUID/Program_G.1/x86_64
#ifdef _MSC_VER
std::bitset<32> features1; // standard features in EDX
std::bitset<32> features2; // standard features in ECX
std::bitset<32> eFeatures1; // extended features in EBX
std::bitset<32> eFeatures2; // extended features in EDX
int cpu_info[4]; // for returns in EAX[0], EBX[1], ECX[2], EDX[3]
__cpuid(cpu_info, 1); // functionID = 1 (EAX = 1)
features1 = cpu_info[3]; // standard features1 = EDX
features2 = cpu_info[2]; // standard features2 = ECX
__cpuidex(cpu_info, 7, 0); // functionID = 1 (EAX = 7), subfunctionID = 0 (ECX = 0)
eFeatures1 = cpu_info[1]; // extended features1 = EBX
__cpuid(cpu_info, 0x80000001); // functionID = 80000001h (EAX = 80000001h)
eFeatures2 = cpu_info[3]; // extended features2 = EDX
#else
std::bitset<64> features1; // standard features in RDX
std::bitset<64> features2; // standard features in RCX
std::bitset<64> eFeatures1; // extended features in RBX
std::bitset<64> eFeatures2; // extended features in RDX
asm("movq $1, %%rax \n\t" // RAX = 1
"cpuid \n\t" // execute CPUID
"movq %%rdx, %[features1] \n\t"
"movq %%rcx, %[features2] \n\t"
"movq $7, %%rax \n\t" // RAX = 7
"xorq %%rcx, %%rcx \n\t" // RCX = 0
"cpuid \n\t"
"movq %%rbx, %[eFeatures1] \n\t"
"movq $0x80000001, %%rax \n\t" // RAX = 80000001h
"cpuid \n\t"
"movq %%rdx, %[eFeatures2] \n\t"
:[features1] "=m"(features1), // outputs
[features2] "=m"(features2),
[eFeatures1] "=m"(eFeatures1),
[eFeatures2] "=m"(eFeatures2)
: // inputs
: "rax", "%rbx", "%rcx", "%rdx" // clobbered registers
);
#endif
// binary output of features, output in reverse due to Little-Endian
fprintf(stdout, "===== CPUID bits (right-to-left) =====\n");
#ifdef _MSC_VER
std::cout << features1 << " -- EDX bits, EAX=1\n"; // fprintf(stdout, "%s\n", features1.to_string().c_str());
std::cout << features2 << " -- ECX bits, EAX=1\n";
std::cout << eFeatures1 << " -- EBX bits, EAX=7 & ECX=0\n";
std::cout << eFeatures2 << " -- EDX bits, EAX=80000001h\n\n";
#else
std::cout << features1 << " -- RDX bits, RAX=1\n";
std::cout << features2 << " -- RCX bits, RAX=1\n";
std::cout << eFeatures1 << " -- RBX bits, RAX=7 & RCX=0\n";
std::cout << eFeatures2 << " -- RDX bits, RAX=80000001h\n\n";
#endif
auto support = [](int i) {
if (i == 1) return "Yes";
else return "No";
};
fprintf(stdout, "===== CPU Features =====\n");
fprintf(stdout, "x87 FPU: %s\n", support(features1[0])); // FPU
fprintf(stdout, "SYSENTER/SYSEXIT: %s\n", support(features1[11])); // SEP (SYSENTER/SYSEXIT)
fprintf(stdout, "MMX: %s\n", support(features1[23])); // MMX
fprintf(stdout, "SSE: %s\n", support(features1[25])); // SSE
fprintf(stdout, "SSE2: %s\n", support(features1[26])); // SSE2
fprintf(stdout, "SSE3: %s\n", support(features2[0])); // SSE3
fprintf(stdout, "SSSE3: %s\n", support(features2[9])); // SSSE3
fprintf(stdout, "FMA3: %s\n", support(features2[12])); // FMA3
fprintf(stdout, "SSE4.1: %s\n", support(features2[19])); // SSE4.1
fprintf(stdout, "SSE4.2: %s\n", support(features2[20])); // SSE4.2
fprintf(stdout, "AVX: %s\n", support(features2[28])); // AVX
fprintf(stdout, "F16C: %s\n", support(features2[29])); // F16C (half-precision)
fprintf(stdout, "RDRAND: %s\n", support(features2[30])); // RDRAND (random number generator)
fprintf(stdout, "===== Extended Features =====\n");
fprintf(stdout, "AVX2: %s\n", support(eFeatures1[5])); // AVX2
fprintf(stdout, "AVX512f: %s\n", support(eFeatures1[16])); // AVX512f
fprintf(stdout, "AVX512dq: %s\n", support(eFeatures1[17])); // AVX512dq
fprintf(stdout, "RDSEED: %s\n", support(eFeatures1[18])); // RDSEED
fprintf(stdout, "AVX512ifma: %s\n", support(eFeatures1[21])); // AVX512ifma
fprintf(stdout, "===== More Extended Features ======\n");
fprintf(stdout, "SYSCALL/SYSRET: %s\n", support(eFeatures2[11])); // SYSCALL/SYSRET
return 0;
} 在Windows上执行结果如下:
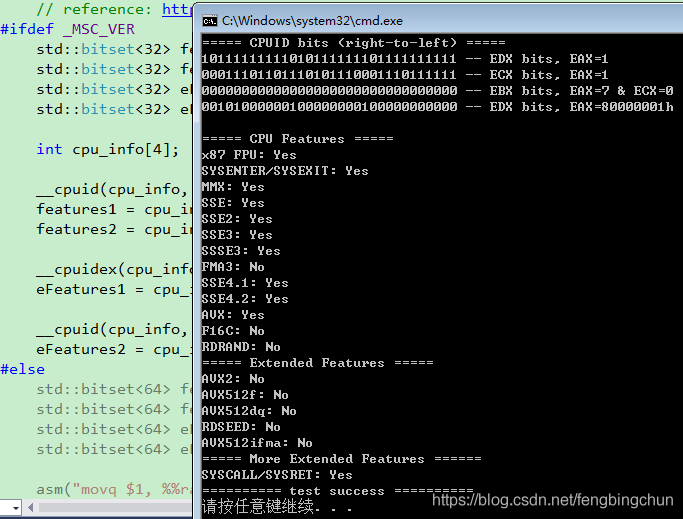
在Linux上执行结果如下:
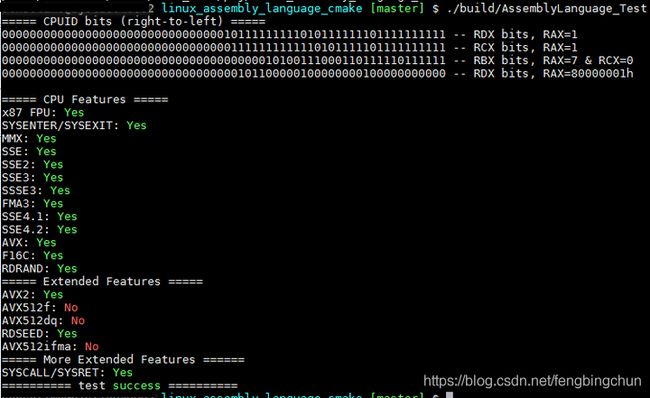
GitHub:https://github.com/fengbingchun/CUDA_Test