如何保证消息的可靠性传输(如何处理消息丢失的问题)
我们在使用MQ的时候有个原则:数据不能多一条,不能少一条,不能多就是不能重复消费以及幂等性问题。不能少,就是说这数据不能搞丢。
如果说我们是用mq来传递非常核心的消息,比如说计费扣费的一些消息,计费系统是很重要的一个业务,操作很耗时。实际上我们将计费系统做成异步化,然后中间就是加一个MQ。
以下是消息丢失的一些分析:
这个丢失数据,mq一般分为两种,要么是mq自己弄丢的,要么是我们消费的时候弄丢了。
rabbitmq这种mq,一般来说都是承载公司的核心业务的,数据是绝对不能弄丢的。
1.rabbitmq
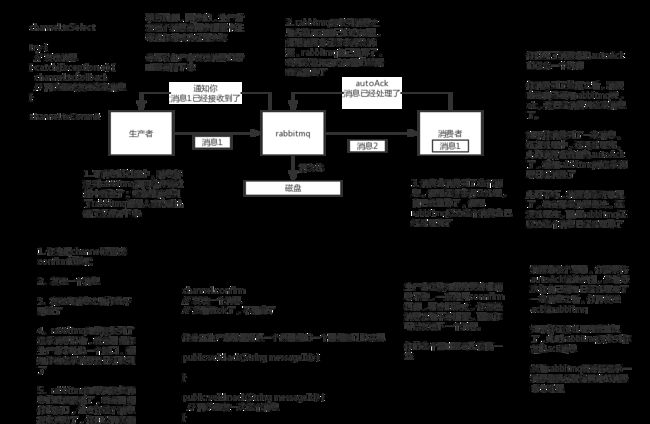
(1)生产者弄丢了数据
生产者将数据发送到rabbitmq的时候,可能数据就在半路给搞丢了,因为网络啥的问题,都有可能。
此时选择用rabbitmq提供的事务功能,就是生产者发送数据之前开启rabbitmq事务,然后发送消息,如果消息没有成功被rabbitmq接收到,那么生产者会收到异常报错,此时就可以回滚事务,然后重试发送消息;如果收到了消息,那么可以提供事务。但是问题是,rabbitmq事务机制一搞,基本上吞吐量会下来,因为太耗性能。
所以一般来说。如果我们要确保说写rabbitmq的消息别丢,可以开启confirm模式,在生产者那里设置开启confirm模式之后,你每次写的消息都会分配一个唯一的id,然后如果写入了rabbitmq中,rabbitmq会给你回传一个ack消息,告诉你这个消息ok。如果rabbitmq没能处理这个消息,会回调你一个nack接口,告诉你这个消息接收失败,你可以重试。而且你可以结合这个机制自己在内存里维护每个消息id的状态,如果超过一定时间还没接收到这个消息的回调,那么我们就可以重发。
事务机制和confirm机制最大的不同在于,事务机制是同步的,我们提交一个事务之后会阻塞在那,但是confirm机制是异步的,我们发送这个消息之后就可以发送下一个消息了,然后那个消息rabbitmq接收了之后会异步回调我们一个接口通知我们这个消息接收到了。
所以一般在生产者这块避免数据丢失都是用confirm机制。
(2)rabbitmq弄丢了数据
面对rabbitmq自己弄丢数据这个问题,我们必须开启rabbitmq的持久化,就是消息写入之后会持久化到磁盘,哪怕是rabbitmq自己挂了,恢复之后会自动读取之前存储的数据,一般数据不会丢。除非极其罕见的是,rabbitmq还没持久化,自己就挂了,可能导致少量数据会丢失,但是这个概率较小。
设置持久化有两个步骤,第一个是创建queue的时候将其设置为持久化,这样就可以保证rabbitmq持久化queue的元数据,但是不会持久化queue里的数据;第二个是发送消息的时候将消息的deliveryMoe设置为2,就是将消息设置为持久化的,此时rabbitmq就会将消息持久化到磁盘上去。必须要同时设置这连个持久化才行,rabbitmq哪怕挂了,再次重启,也会从磁盘上重启恢复queue,恢复这个queue里的数据。
而且持久化可以跟生产者那边的confirm机制配合起来,只有消息被持久化到磁盘之后,才会通知生产者ack,所以哪怕是在持久化到磁盘之前,rabbitmq挂了,数据丢了,生产者收不到ack,你䦹可以自己重发的。
哪怕是我们给rabbitmq开启了持久化机制,也有一种可能,就是这个消息写到了rabbitmq中,但是还没来得及持久化到磁盘上,结果不巧,此时rabbitmq挂了,就会导致内存里的一点数据会丢失。
(3)消费端弄丢失了数据
rabbitmq如果丢失了数据,主要是因为你消费的时候,刚消费到,还没处理,结果进程挂了,比如重启了,那么就尴尬了,rabbitmq认为你都消费了,这数据就丢了。
这个时候得用rabbitmq提供的ack机制,简单来说,就是我们关闭rabbitmq自动ack,可以通过一个api来调用就行,然后每次我们自己代码里面确保处理完的时候,再程序里ack一次。这样的话,如果我们还没处理完就没有ack了。这个时候rabbitmq就会认为我们还没处理完,这个时候rabbitmq就会把这个消息分配给别的consumer去处理,消息是不会丢失的。
2.kafka
(1)消费端弄丢了数据
唯一可能导致消费者弄丢数据的情况,就是说,我们那个消费到了这个消息,然后消费者那边自动提交了offset,让kafka以为你已经消费好了这个消息,其实我们刚准备处理这个消息,还没处理,自己就挂了,此时这条消息就丢了。那么我们这要关闭自动提交offset,在处理完之后自己手动提交offset,就可以保证数据不会丢。但是此时确实还是会重复消费,必须我们刚处理完,还没提交offset,结果自己挂了,此时肯定会重复消费一次,需要我们自己保证幂等性。
(2)kafka弄丢了数据
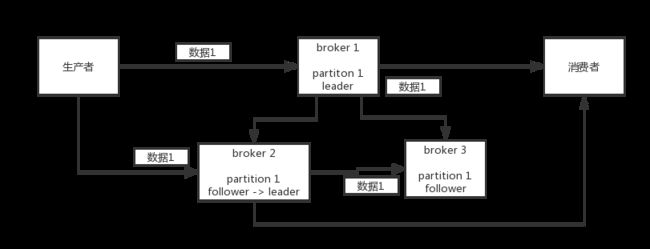
比较常见的一个场景,就是kafka某个broker宕机,然后重新选举partition的leader时。要是此时其他的follower刚好还有些数据没有同步,结果此时leader挂了,然后大家选举某个follower成为leader之后,不就少了一些数据。
这种情况我们需要设置如下四个参数:
给topic设置replication.factor参数:这个值必须大于1,要求每个partition必须有至少两个副本。
在kafka服务端设置min.insync.replicas参数:这个值必须大于1,这个是要求一个leader至少感知到有至少一个follower还跟自己保持联系,没掉队,这样才能确保leader挂了还有一个follower。
在producer端设置acks=all:这个是要求每条数据,必须是写入所有replica之后,才能认为是写成功了。
在producer端设置retries=MAX(很大很大很大的一个值,无限次重试的意思):这个是要求一旦写入失败,就无限重试,卡在这里。
我们生产环境就是按照上述要求配置的,这样配置之后,至少在kafka broker端就可以保证在leader所在broker发生故障,进行leader切换时,数据不会丢失。
(3)生产者丢失数据
如果按照上述的思路设置了ack=all,一定不会丢,要求是,你的leader接收到消息,所有的follower都同步到了消息之后,才认为本次写成功了。如果没满足这个条件,生产者会自动不断的重试,重试无限次。