数据结构与算法(三)-哈希表
一、哈希表介绍
1.由来
我们知道,数组查询容易,插入和删除困难;链表查询困难,插入和删除容易。数组和链表的优缺点刚好互补,将他们结合起来,就有一种寻址容易,插入删除也容易的数据结构。哈希表就是这样一种数据结构。
2.基本概念
哈希表(也叫散列表),是根据关键码值(Key)(关键码值就是key的Hash值)而直接进行访问的数据结构。给定表M,存在函数f(key),对任意给定的关键字值key,代入函数后若能得到包含该关键字的记录在表中的地址,则称表M为哈希表,函数f(key)为哈希函数(也叫散列函数)。
哈希表是一个节点数组,而一个节点就是一个链表。相当于外层为数组,内层为链表。
装填因子:α= 节点数组的元素个数 / 节点数组的长度。一般为0.6~0.9。为什么需要这个值?因为数据越接近数组最大值,可能产生的冲突越多.
哈希冲突:对不同的关键字可能得到同一散列地址,即k1≠k2,而f(k1)=f(k2)。
均匀散列函数:若对于关键字集合中的任一个关键字,经散列函数映象到地址集合中任何一个地址的概率是相等的,则称此类散列函数为均匀散列函数。
例如:

Key : {14, 19, 5, 7, 21, 1, 13, 0, 18} 散列表: 大小为13 的数组 a[13]; 散列函数: f(x) = x mod 13;
3.hash冲突解决的方案(这里有很多种解决方案)
方案1:
可以直接让关键码值加1,或者加2 ....直到填入到散列表中不出现冲突 ,也就是散列表还没有关键码值填入
方案2:
当方案一的关键码值填入快要占满整个散列表时,就需要给散列表动态扩容,同时散列函数也要发生变化.这样会消耗大量的空间和性能.因为前面已经填入的值要重新计算,这样只适用于固定大小的存储,例如电话号码本,字典,点歌系统
4.设计优化(拉链法):
JDK 1.8以前 ,hashmap的实现,填入同一个散列表表格的关键码值,已单链表链接,兼容了顺序表和链表的特性
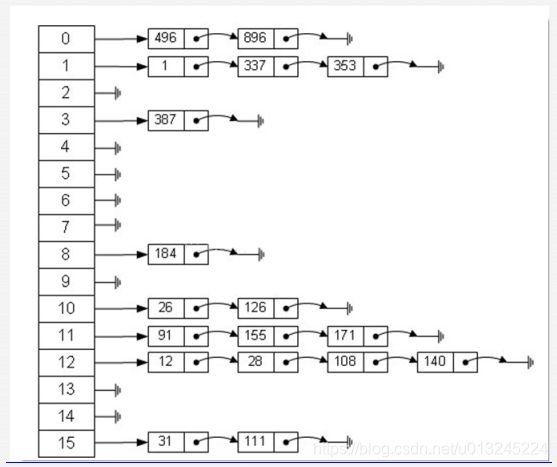
JDK 1.8之后,hashmap的实现,引用了红黑树树.因为如果散列数组很小 ,存的数据很多,可能导致某些散列表的表格上的链表很长,这样如果查找的话就相当于链表的查找,时间复杂度就会越大,假设链表的阈值为1000,当存储的数据超过1000时,那么存取的方式就会转化为红黑树

二、哈希表的实现
1.成员属性
这里手写一个哈希表,基本成员属性如下:
// 默认数组大小16,必须为2的幂
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
// 默认填充因子
static final float DEFAULT_LOAD_FACTOR = 0.75f;
// 节点数组
Node[] table;
// 节点数组的大小
int threshold;
// 插入键值对的个数
int size;
哈希表的扩容很复杂,每次将节点数组增加一倍,为了提高运算效率,使用二进制加法,所以数组大小必须为2的幂,默认数组大小也必须为2的幂。
装填因子越大,越不容易发生哈希冲突,效率越高,内存也越大,所以一般在0.6~0.9。
2.添加
添加的key必须实现hashCode(),否则不能映射地址。
public V put(K k, V v) {
//初始化成员属性
initTable();
//允许key为null
if (k == null) {
return putNullKey(v);
}
//获取hash值
int hash = hash(k);
//映射到数组下标
int index = getIndex(hash, table.length);
//键不可以重复
for (Node node = table[index]; node != null; node = node.next) {
if (hash == node.hash && (node.key == k || node.key.equals(k))) {
V old = node.value;
node.value = v;
return old;
}
}
//添加到哈希表
addEntry(hash, k, v, index);
return null;
}
private void addEntry(int hash, K k, V v, int index) {
//动态扩容
if (size >= threshold && table[index] != null) {
checkSize();
hash = (k == null) ? 0 : hash(k);
index = getIndex(hash, table.length);
}
//获取指定位置的节点
Node e = table[index];
Node newNode = new Node(hash, k, v, e);
table[index] = newNode;
size++;
}
3.删除
public V remove(Object key) {
if (size == 0) {
return null;
}
int hash = (key == null) ? 0 : hash(key);
int index = getIndex(hash, table.length);
//先找到其头结点
Node pre = table[index];
Node now = pre;
//根据key循环查找节点,找到后删除
while (now != null) {
Node next = now.next;
if (hash == now.hash && (now.key == key || (now.key != null && now.key.equals(key)))) {
size--;
if (pre == now) {
table[index] = next;
} else {
pre.next = next;
}
return (now == null) ? null : now.value;
}
pre = now;
now = next;
}
return (now == null) ? null : now.value;
}
4.查找
private Node getEntry(Object key) {
int hash = (key == null) ? 0 : hash(key);
int index = getIndex(hash, table.length);
for (Node node = table[index]; node != null; node = node.next) {
if (hash == node.hash && (node.key == key || node.key.equals(key))) {
return node;
}
}
return null;
}
三、HashMap与HashTable的区别
HashMap与HashTable都属于哈希表,他们的区别在面试中经常被问到,这里来总结一下:
- HashMap异步不安全,效率高;HashTable同步安全,效率低。
- HashMap允许添加空的key,HashTable不允许。
- HashMap继承自抽象类AbstractMap,而HashTable继承自抽象类Dictionary(已废弃)。
- HashMap默认的初始化大小为16,之后每次扩充为原来的2倍;HashTable默认的初始大小为11,之后每次扩充为原来的2n+1。