Spark数据倾斜解决方案
1.聚合源数据
咱们现在,做一些聚合的操作,groupByKey、reduceByKey;groupByKey,说白了,就是拿到每个key对应的values;reduceByKey,说白了,就是对每个key对应的values执行一定的计算。现在这些操作,比如groupByKey和reduceByKey,包括之前说的join。都是在spark作业中执行的。
spark作业的数据来源,通常是哪里呢?90%的情况下,数据来源都是hive表(hdfs,大数据分布式存储系统)。hdfs上存储的大数据。hive表,hive表中的数据,通常是怎么出来的呢?有了spark以后,hive比较适合做什么事情?hive就是适合做离线的,晚上凌晨跑的,ETL(extract transform load,数据的采集、清洗、导入),hive sql,去做这些事情,从而去形成一个完整的hive中的数据仓库;说白了,数据仓库,就是一堆表。
spark作业的源表,hive表,其实通常情况下来说,也是通过某些hive etl生成的。hive etl可能是晚上凌晨在那儿跑。今天跑昨天的数据。
1.1.先在hive etl中将数据以key聚合,value成一条数据
数据倾斜,某个key对应的80万数据,某些key对应几百条,某些key对应几十条;现在,咱们直接在生成hive表的hive etl中,对数据进行聚合。比如按key来分组,将key对应的所有的values,全部用一种特殊的格式,拼接到一个字符串里面去,比如“key=sessionid, value: action_seq=1|user_id=1|search_keyword=火锅|category_id=001;action_seq=2|user_id=1|search_keyword=涮肉|category_id=001”。
对key进行group,在spark中,拿到key=sessionid,values
spark中,可能对这个操作,就不需要执行shffule操作了,也就根本不可能导致数据倾斜。
或者是,对每个key在hive etl中进行聚合,对所有values聚合一下,不一定是拼接起来,可能是直接进行计算。reduceByKey,计算函数,应用在hive etl中,每个key的values。
1.2.聚合源数据的第二种方案
你可能没有办法对每个key,就聚合出来一条数据;
那么也可以做一个妥协;对每个key对应的数据,10万条;有好几个粒度,比如10万条里面包含了几个城市、几天、几个地区的数据,现在放粗粒度;直接就按照城市粒度,做一下聚合,几个城市,几天、几个地区粒度的数据,都给聚合起来。比如说
city_id date area_id
select ... from ... group by city_id
尽量去聚合,减少每个key对应的数量,也许聚合到比较粗的粒度之后,原先有10万数据量的key,现在只有1万数据量。减轻数据倾斜的现象和问题。
2.过滤导致倾斜的key
如果你能够接受某些数据,在spark作业中直接就摒弃掉,不使用。比如说,总共有100万个key。只有2个key,是数据量达到10万的。其他所有的key,对应的数量都是几十。
这个时候,你自己可以去取舍,如果业务和需求可以理解和接受的话,在你从hive表查询源数据的时候,直接在sql中用where条件,过滤掉某几个key。
那么这几个原先有大量数据,会导致数据倾斜的key,被过滤掉之后,那么在你的spark作业中,自然就不会发生数据倾斜了。
3.提高shuffle操作reduce端的并行度
将reduce task的数量,变多,就可以让每个reduce task分配到更少的数据量,这样的话,也许就可以缓解,或者甚至是基本解决掉数据倾斜的问题。
4.使用随机key实现双重聚合
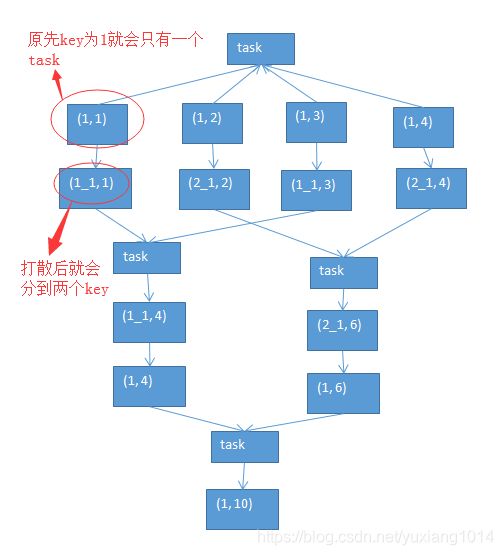
4.1.原理
4.2.使用场景
如:groupByKey,reduceByKey等比较适合使用这种方式;join,咱们通常不会这样来做,后面会讲三种,针对不同的join造成的数据倾斜的问题的解决方案。
第一轮聚合的时候,对key进行打散,将原先一样的key,变成不一样的key,相当于是将每个key分为多组;
先针对多个组,进行key的局部聚合;接着,再去除掉每个key的前缀,然后对所有的key,进行全局的聚合。
对groupByKey、reduceByKey造成的数据倾斜,有比较好的效果。
如果说,之前的第一、第二、第三种方案,都没法解决数据倾斜的问题,那么就只能依靠这一种方式了。
5.reduce join转成map join
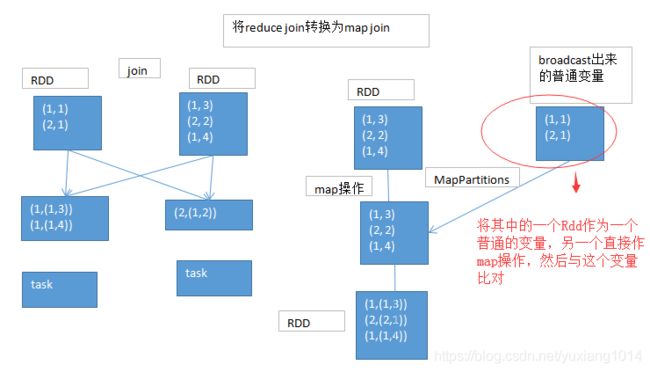
5.1.原理
5.2. reduce join转换为map join,适合在什么样的情况下,可以来使用?
如果两个RDD要进行join,其中一个RDD是比较小的。一个RDD是100万数据,一个RDD是1万数据。(一个RDD是1亿数据,一个RDD是100万数据)
其中一个RDD必须是比较小的,broadcast出去那个小RDD的数据以后,就会在每个executor的block manager中都驻留一份。要确保你的内存足够存放那个小RDD中的数据
这种方式下,根本不会发生shuffle操作,肯定也不会发生数据倾斜;从根本上杜绝了join操作可能导致的数据倾斜的问题;
对于join中有数据倾斜的情况,大家尽量第一时间先考虑这种方式,效果非常好;如果某个RDD比较小的情况下。
5.3. 不适合的情况:
两个RDD都比较大,那么这个时候,你去将其中一个RDD做成broadcast,就很笨拙了。很可能导致内存不足。最终导致内存溢出,程序挂掉。
而且其中某些key(或者是某个key),还发生了数据倾斜;此时可以采用最后两种方式。
对于join这种操作,不光是考虑数据倾斜的问题;即使是没有数据倾斜问题,也完全可以优先考虑,用我们讲的这种高级的reduce join转map join的技术,不要用普通的join,去通过shuffle,进行数据的join;完全可以通过简单的map,使用map join的方式,牺牲一点内存资源;在可行的情况下,优先这么使用。
不走shuffle,直接走map,是不是性能也会高很多?这是肯定的。
6.sample采样倾斜key进行两次join
这个方案的实现思路,跟大家解析一下:其实关键之处在于,将发生数据倾斜的key,单独拉出来,放到一个RDD中去;就用这个原本会倾斜的key RDD跟其他RDD,单独去join一下,这个时候,key对应的数据,可能就会分散到多个task中去进行join操作。
就不至于说是,这个key跟之前其他的key混合在一个RDD中时,肯定是会导致一个key对应的所有数据,都到一个task中去,就会导致数据倾斜。
7.使用随机数以及扩容表进行join