代码+案例详解:使用Spark处理大数据最全指南(下)
(接上篇)

Spark应用实例
接下来用具体实例解决一些常见的转换。
所研究的数据集是Movielens(https://github.com/MLWhiz/spark_post),该数据集是一个稳定基准数据集。1700部电影中的1000名用户给出了100000份评分,发布于1998年4月。
Movielens数据集包含大量文件,但本文仅处理3个文件:
1. 用户: 此文件名为 “u.user”, 文件中的列如下:
['user_id', 'age', 'sex', 'occupation', 'zip_code']
2. 评分: 此文件名为 “u.data”, 文件中的列如下:
['user_id', 'movie_id', 'rating', 'unix_timestamp']
3. 电影: 此文件名为 “u.item”, 文件中的列如下:
['movie_id', 'title', 'release_date', 'video_release_date', 'imdb_url', and 18 more columns.....]
首先使用主页选项卡上的“导入和浏览数据”将这3个文件导入spark实例。

业务合作伙伴联络我们并要求从这些数据中找出25部评分最高的电影。一部电影会收到多少次评分?
在不同的RDD中加载数据,看看数据包含什么内容吧。
userRDD = sc.textFile("/FileStore/tables/u.user")
ratingRDD = sc.textFile("/FileStore/tables/u.data")
movieRDD = sc.textFile("/FileStore/tables/u.item")
print("userRDD:",userRDD.take(1))
print("ratingRDD:",ratingRDD.take(1))
print("movieRDD:",movieRDD.take(1))
-----------------------------------------------------------
userRDD: ['1|24|M|technician|85711']
ratingRDD: ['196\t242\t3\t881250949']
movieRDD: ['1|Toy Story (1995)|01-Jan-1995||http://us.imdb.com/M/title-exact?Toy%20Story%20(1995)|0|0|0|1|1|1|0|0|0|0|0|0|0|0|0|0|0|0|0']
值得注意的是,回答这个问题需要使用ratingRDD。但是ratingRDD中没有电影名称。
所以必须使用 movie_id合并movieRDD和ratingRDD。
如何在Spark中做到这一点?
以下是使用的代码。其中还使用了一个新的转换leftOuterJoin。请阅读以下代码中的文档和评论。
# Create a RDD from RatingRDD that only contains the two columns of interest i.e. movie_id,rating.
RDD_movid_rating = ratingRDD.map(lambda x : (x.split("\t")[1],x.split("\t")[2]))
print("RDD_movid_rating:",RDD_movid_rating.take(4))
# Create a RDD from MovieRDD that only contains the two columns of interest i.e. movie_id,title.
RDD_movid_title = movieRDD.map(lambda x : (x.split("|")[0],x.split("|")[1]))
print("RDD_movid_title:",RDD_movid_title.take(2))
# merge these two pair RDDs based on movie_id. For this we will use the transformation leftOuterJoin(). See the transformation document.
rdd_movid_title_rating = RDD_movid_rating.leftOuterJoin(RDD_movid_title)
print("rdd_movid_title_rating:",rdd_movid_title_rating.take(1))
# use the RDD in previous step to create (movie,1) tuple pair RDD
rdd_title_rating = rdd_movid_title_rating.map(lambda x: (x[1][1],1 ))
print("rdd_title_rating:",rdd_title_rating.take(2))
# Use the reduceByKey transformation to reduce on the basis of movie_title
rdd_title_ratingcnt = rdd_title_rating.reduceByKey(lambda x,y: x+y)
print("rdd_title_ratingcnt:",rdd_title_ratingcnt.take(2))
# Get the final answer by using takeOrdered Transformation
print "#####################################"
print "25 most rated movies:",rdd_title_ratingcnt.takeOrdered(25,lambda x:-x[1])
print "#####################################"
OUTPUT:
--------------------------------------------------------------------RDD_movid_rating: [('242', '3'), ('302', '3'), ('377', '1'), ('51', '2')]
RDD_movid_title: [('1', 'Toy Story (1995)'), ('2', 'GoldenEye (1995)')]
rdd_movid_title_rating: [('1440', ('3', 'Above the Rim (1994)'))] rdd_title_rating: [('Above the Rim (1994)', 1), ('Above the Rim (1994)', 1)]
rdd_title_ratingcnt: [('Mallrats (1995)', 54), ('Michael Collins (1996)', 92)]
#####################################
25 most rated movies: [('Star Wars (1977)', 583), ('Contact (1997)', 509), ('Fargo (1996)', 508), ('Return of the Jedi (1983)', 507), ('Liar Liar (1997)', 485), ('English Patient, The (1996)', 481), ('Scream (1996)', 478), ('Toy Story (1995)', 452), ('Air Force One (1997)', 431), ('Independence Day (ID4) (1996)', 429), ('Raiders of the Lost Ark (1981)', 420), ('Godfather, The (1972)', 413), ('Pulp Fiction (1994)', 394), ('Twelve Monkeys (1995)', 392), ('Silence of the Lambs, The (1991)', 390), ('Jerry Maguire (1996)', 384), ('Chasing Amy (1997)', 379), ('Rock, The (1996)', 378), ('Empire Strikes Back, The (1980)', 367), ('Star Trek: First Contact (1996)', 365), ('Back to the Future (1985)', 350), ('Titanic (1997)', 350), ('Mission: Impossible (1996)', 344), ('Fugitive, The (1993)', 336), ('Indiana Jones and the Last Crusade (1989)', 331)] #####################################
《星球大战》是Movielens数据集中评分最高的电影。
现在可以使用以下命令在一个命令中完成所有步骤,但现在代码有点乱。
这样做是为了表明Spark的链接功能可以使用,借此绕过变量创建的过程。
print(((ratingRDD.map(lambda x : (x.split("\t")[1],x.split("\t")[2]))).
leftOuterJoin(movieRDD.map(lambda x : (x.split("|")[0],x.split("|")[1])))).
map(lambda x: (x[1][1],1)).
reduceByKey(lambda x,y: x+y).
takeOrdered(25,lambda x:-x[1]))
再来一次。练习:
现在想要使用相同的数据集找到评分最高的25部电影。事实上只需要那些至少有100次评分的电影。
# We already have the RDD rdd_movid_title_rating: [(u'429', (u'5', u'Day the Earth Stood Still, The (1951)'))]
# We create an RDD that contains sum of all the ratings for a particular movie
rdd_title_ratingsum = (rdd_movid_title_rating.
map(lambda x: (x[1][1],int(x[1][0]))).
reduceByKey(lambda x,y:x+y))
print("rdd_title_ratingsum:",rdd_title_ratingsum.take(2))
# Merge this data with the RDD rdd_title_ratingcnt we created in the last step
# And use Map function to divide ratingsum by rating count.
rdd_title_ratingmean_rating_count = (rdd_title_ratingsum.
leftOuterJoin(rdd_title_ratingcnt).
map(lambda x:(x[0],(float(x[1][0])/x[1][1],x[1][1]))))
print("rdd_title_ratingmean_rating_count:",rdd_title_ratingmean_rating_count.take(1))
# We could use take ordered here only but we want to only get the movies which have count
# of ratings more than or equal to 100 so lets filter the data RDD.
rdd_title_rating_rating_count_gt_100 = (rdd_title_ratingmean_rating_count.
filter(lambda x: x[1][1]>=100))
print("rdd_title_rating_rating_count_gt_100:",rdd_title_rating_rating_count_gt_100.take(1))
# Get the final answer by using takeOrdered Transformation
print("#####################################")
print ("25 highly rated movies:")
print(rdd_title_rating_rating_count_gt_100.takeOrdered(25,lambda x:-x[1][0]))
print("#####################################")
OUTPUT:
------------------------------------------------------------
rdd_title_ratingsum: [('Mallrats (1995)', 186), ('Michael Collins (1996)', 318)]
rdd_title_ratingmean_rating_count: [('Mallrats (1995)', (3.4444444444444446, 54))]
rdd_title_rating_rating_count_gt_100: [('Butch Cassidy and the Sundance Kid (1969)', (3.949074074074074, 216))]
#####################################
25 highly rated movies: [('Close Shave, A (1995)', (4.491071428571429, 112)), ("Schindler's List (1993)", (4.466442953020135, 298)), ('Wrong Trousers, The (1993)', (4.466101694915254, 118)), ('Casablanca (1942)', (4.45679012345679, 243)), ('Shawshank Redemption, The (1994)', (4.445229681978798, 283)), ('Rear Window (1954)', (4.3875598086124405, 209)), ('Usual Suspects, The (1995)', (4.385767790262173, 267)), ('Star Wars (1977)', (4.3584905660377355, 583)), ('12 Angry Men (1957)', (4.344, 125)), ('Citizen Kane (1941)', (4.292929292929293, 198)), ('To Kill a Mockingbird (1962)', (4.292237442922374, 219)), ("One Flew Over the Cuckoo's Nest (1975)", (4.291666666666667, 264)), ('Silence of the Lambs, The (1991)', (4.28974358974359, 390)), ('North by Northwest (1959)', (4.284916201117318, 179)), ('Godfather, The (1972)', (4.283292978208232, 413)), ('Secrets & Lies (1996)', (4.265432098765432, 162)), ('Good Will Hunting (1997)', (4.262626262626263, 198)), ('Manchurian Candidate, The (1962)', (4.259541984732825, 131)), ('Dr. Strangelove or: How I Learned to Stop Worrying and Love the Bomb (1963)', (4.252577319587629, 194)), ('Raiders of the Lost Ark (1981)', (4.252380952380952, 420)), ('Vertigo (1958)', (4.251396648044692, 179)), ('Titanic (1997)', (4.2457142857142856, 350)), ('Lawrence of Arabia (1962)', (4.23121387283237, 173)), ('Maltese Falcon, The (1941)', (4.2101449275362315, 138)), ('Empire Strikes Back, The (1980)', (4.204359673024523, 367))]
#####################################
到目前为止,已经讨论过RDD,因为其非常强大。
RDD也可以处理非关系型数据库。
他们让你完成很多无法用SparkSQL完成的事情?
是的,你也可以通过Spark使用 SQL,接下来就谈谈这个。
Spark Datafrmes
Spark为数据科学家提供了DataFrame API来处理关系数据。
请记住,在后台它仍然是所有RDD,这就是本文伊始关注RDD的原因。
下文将从使用Spark DataFrames所需的一些常用功能开始。它的一些句法变化与Pandas很相像。
1. 读取文件
ratings = spark.read.load("/FileStore/tables/u.data",format="csv", sep="\t", inferSchema="true", header="false")
2. 显示文件
使用Spark DataFrames显示文件有两种方式。
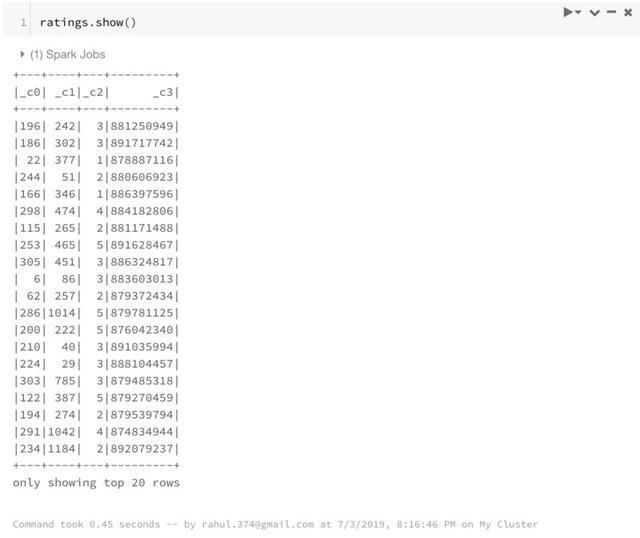
本文倾向于 display,因其看起来更为美观简洁。
3. 改变列名
这是一个好功能,一直都很有用。注意不要遗漏列表前的*。
ratings = ratings.toDF(*['user_id', 'movie_id', 'rating', 'unix_timestamp'])
4. 一些基本统计结果
print(ratings.count()) #Row Count print(len(ratings.columns)) #Column Count --------------------------------------------------------- 100000 4
还可以使用以下方式看到数据帧的统计结果
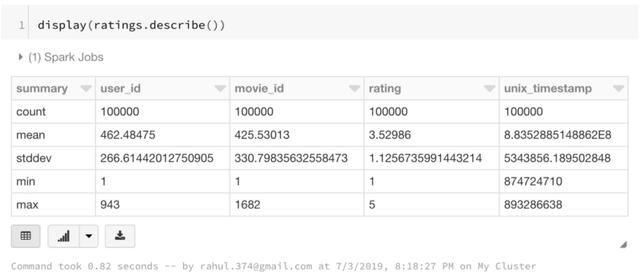
5. 选择部分列
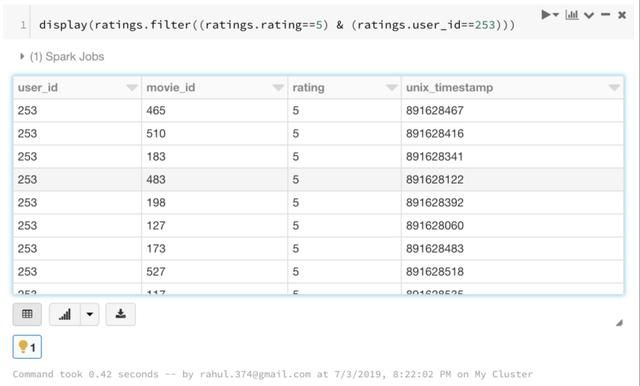
6. 筛选
使用多个条件筛选数据帧:
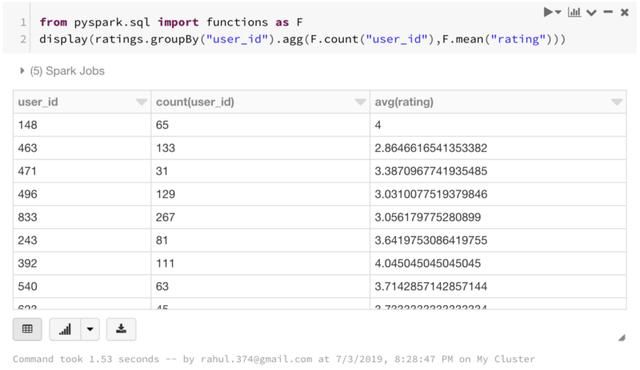
7. Groupby函数
Groupby函数可以与spark数据帧结合使用。操作与pandas groupby函数基本相同,只是需要导入pyspark.sql. functions函数。
from pyspark.sql import functions as F
display(ratings.groupBy("user_id").agg(F.count("user_id"),F.mean("rating")))
本文中已从每个user_id中找到了评分数以及平均评分。
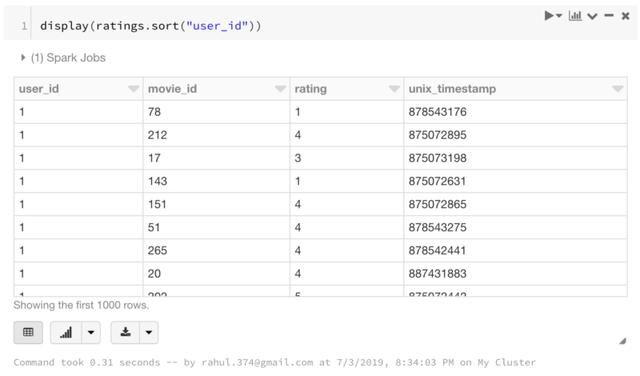
8. 排序
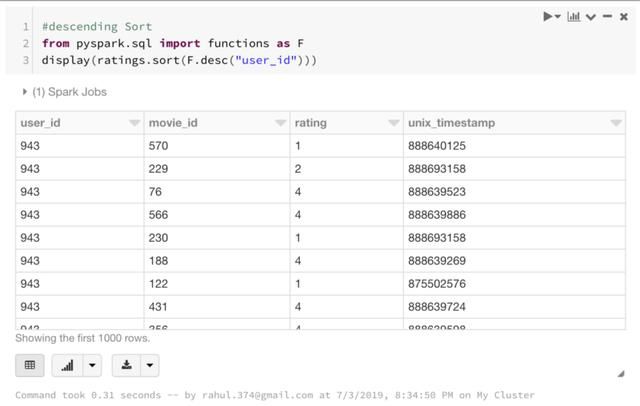
如下所示,还可以使用F.desc函数进行降序排序
使用spark Dataframes数据帧进行增加/合并
无法找到与Spark DataFrames合并的pandas对应项,但SQL可以与与dataframes一起使用,所以可以使用SQL合并dataframes。
试着在Ratings上运行SQL。
首先将ratings df注册到临时表ratings_table,其上可运行sql操作。
如你所见,SQL select语句的结果还是Spark Datadframe。

现在再添加一个Spark Dataframe,观察是否可以使用SQL查询来使用连接:
#get one more dataframe to join
movies = spark.read.load("/FileStore/tables/u.item",format="csv", sep="|", inferSchema="true", header="false")
# change column names
movies = movies.toDF(*["movie_id","movie_title","release_date","video_release_date","IMDb_URL","unknown","Action","Adventure","Animation ","Children","Comedy","Crime","Documentary","Drama","Fantasy","Film_Noir","Horror","Musical","Mystery","Romance","Sci_Fi","Thriller","War","Western"])

现在尝试加入movie_id上的表格,以获得评级表中的电影名。
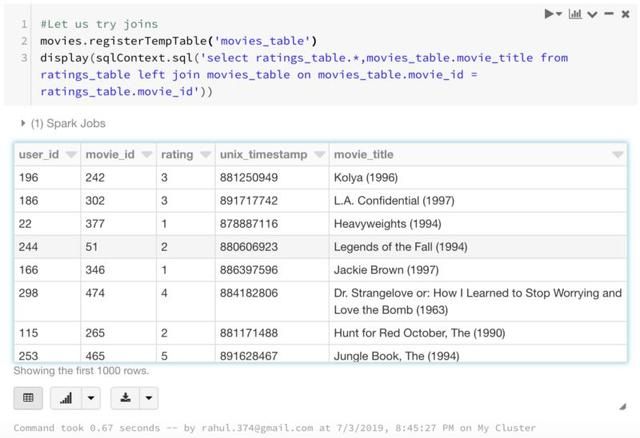
尝试用RDD做之前做的事情。找到评分最高的25部电影:

同时找到拥有超过100票的25部评分最高电影:
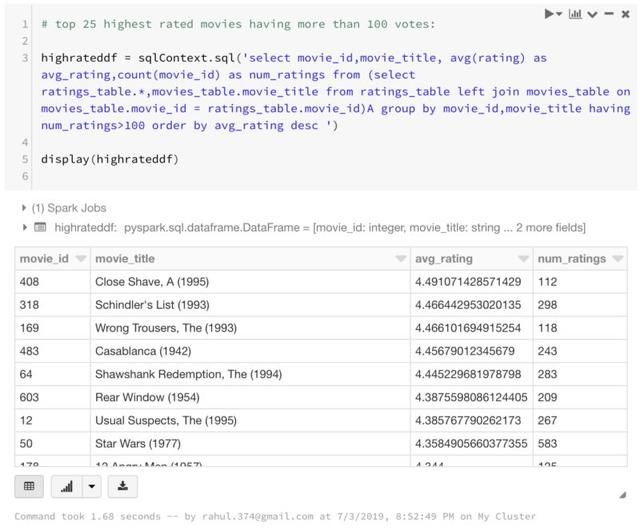
上面的查询中使用了GROUP BY,HAVING和ORDER BY子句以及别名。这表明使用sqlContext.sql可以完成相当复杂的事情。
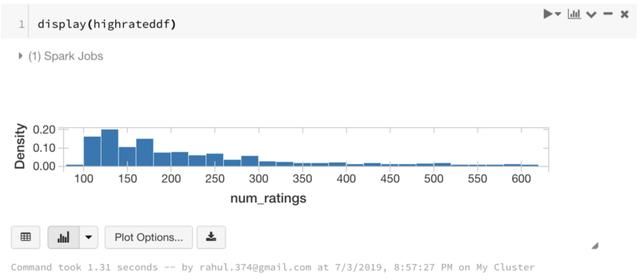
关于Display命令的小提示
还可以使用display命令以在笔记本中显示图表。
选择“绘图选项”时,可以看到更多选项。
Spark Dataframe与RDD的相互转换
有时可能希望Spark Dataframe与RDD的相互转换,这样就可以充分利用这两个不同的功能。
要从DF转换为RDD,只需执行以下操作:

由RDD转换为数据帧:
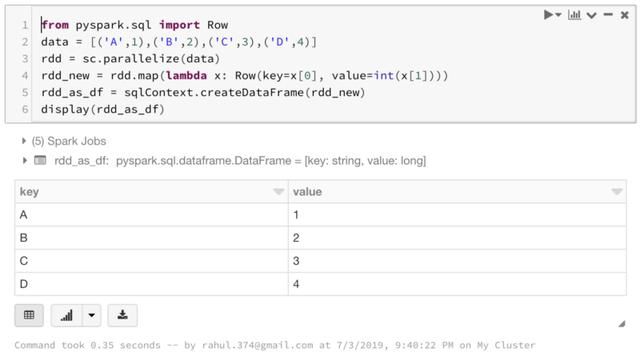
RDD以时间和编码工作上的付出为代价提供更多控制。而Dataframes则提供熟悉的编码平台。但是现在可以在这两者之间来回转换了。
结论
Spark提供了一个界面,在此可以对数据进行转换和操作。Spark还拥有Dataframe API,便于简化数据科学家向大数据的过渡。
GitHub代码传送门:https://github.com/MLWhiz/spark_post?source=post_page---------------------------