对C语言类型转换总结及求校验和的教训
首先,先讲signed 和unsigned之间的转换。
很明显,实际上这两个类型之间的转换并没有并没有改变存储器中所存储的数据,但是由于有符号数的正负数的存储方式不同,其转换为实际的数值时所表现出来的值就有可能引起很大的差异,因而类型转换之后所表现出来的值很可能不同。下面举例说明:
signed char a = -1,假设计算机采用补码形式存放(大多数情况下都是这样存储),那么其存储序列应为:1111 1111;
当转换为unsigned char b = a结果会是怎样呢?其在计算机中的存储序列
仍然为:1111 1111 ;由于是无符号数,故其实际值为255,那么显然,所表示的实际值不一样。当然,若是正数,有符号与无符号的转换,其表现出的实际值应该是一样的。
那么,这里先来个小总结:有符号数与无符号数之间的转换并不会影响存储器中的数据(即01序列),而会很有可能影响的是所表示出来的实际值。
说白了,有符号与无符号之间的转换,相当于改变了计算机系统对他们的认知方式,不同的认知方式会带来不同的认知结果。
接着,谈谈小字节类型向大字节类型的转换(这里指有符号与有符号类型转换,无符号与无符号类型转换)小字节类型转换为大字节类型时,要注意的问题就是多出的高位的填充。
先来谈谈小字节有符号与大字节有符号类型转换,大字节类型多出的字节的位全部用小字节类型的最高位填充,这样保证了数值转换后的一致性。
比如,signed char a = -1,转换为signed int b =a;a在存储时的补码为1111 1111,那么b应该为:1111 1111 1111 1111 1111 1111 1111 1111;故b=a=-1.
同样的,signed char a = 1,转换为signed char b= a时;a在存储器的补码为0000 0001;那么b应该为0000 0000 0000 0000 0000 0000 00000001;故b=a=1;
接下来谈谈小字节无符号与大字节无符号类型转换,大字节类型多出的字节的位全部用0填充,这样也保证了转换后的数值的一致性。比如,unsigned char a=1, unsigned int b=a;a的储存的序列为:0000 0001;那么b的应为:0000 0000 0000 0000 0000 0000 00000001;显然c=a=1。
这里再来个小结,小字节类型向大字节类型的转换通常都能保证数值不发生改变,相对安全,但在嵌入式的开发中补充的位却很值得注意,不然很容易导致很隐秘的错误,下面有我亲身经历的悲剧。而反过来大字节类型向小字节类型的转换则十分危险。
我遇到的在嵌入式方面的情况(有些情况下类型转换后表现出的实际值可能相同,但是若这高位拓展不清楚,很容易因为副作用导致错误):
先看这段代码:
Buf = (char*)malloc(buf_size);
a= Buf;
unsigned int checksum = 0;
for(i = 0; i < buf_size; i++)
checksum += (unsigned int) *a++;
这段代码的本意是想对Buf的数据求校验和checksum,注意checksum是unsignedint 型的,而buffer是char型,的这段代码真的能够实现求检验和吗?
答案是不能,表面看起来是能而已,让我们一起来看看其究竟是怎么不能。buffer是char型的,故取出的数据是char型的,假设为*a=0xf1,那么强制类型转换之后得到的是什么呢?先转化为signed int型,即0xfffffff1;再转换为unsined int型,即0xfffffff1;很明显通过高位的符号拓展,高位填充了很多的1,那么求出来的校验和必然是错误的。
如果我们改成这样就正确了:
Buf = (unsignedchar *)malloc(buf_size);
a = Buf;
unsignedint checksum = 0;
for(i= 0; i < buf_size; i++)
checksum+= (unsigned int) *a++;
这次buffer是unsignedchar型的,故取出的数据是unsignedchar型的,仍然假设为*a=0xf1,那么强制类型转换之后得到的是unsignedint型,即0x000000f1;很明显通过高位的符号拓展,高位填充了很多的0,那么这样求出的结果应该是正确的了。
再看看另一种方法:
Buf = (char*)malloc(buf_size);
a = Buf;
unsignedint checksum = 0;
unsignedchar tm = 0;
for(i= 0; i < buf_size; i++) {
tm= (unsigned char)*a;
a++;
checksum+= tm;
}
buffer是char型的,故取出的数据是char型的,假设为*a=0xf1,那么强制类型转换之后得到的是什么呢?先转化为unsignedint型,即0xf1;然后再由unsignedint型隐含转换为unsinedint型,即0x000000f1;很明显通过高位的符号拓展,高位填充了很多的0,故得出的校验和也应该是正确的。
以上的方法都不好,我们并不推荐像这样或者经常使用强制类型转换,应该如下面这样来求校验和:
Buf = (unsigned char *)malloc(buf_size);
a = Buf;
for(i = 0; i < data_size; i++)
checksum+= (0x000000FF) & *a++;
通过按位与操作来实现避免了类型转换带来的副作用。
参考图标:
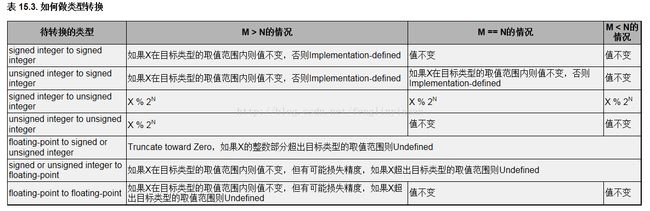
图标摘自:http://learn.akae.cn/media/ch15s03.html
以上是本人的一些个人见解,希望可以搬到一些人。由于本人知识水平有限,难免有错误之处,希望大家宽容并指出,我定会虚心学习,共同进步。
转载请注明出处。