Mysql&&&&JDBC
JavaWeb
什么是JavaWeb?
使用Java语言开发互联网项目,简单理解:使用Java语言开发网站
数据库 DateBase 简称:DB
什么数据库?
用于存储和管理数据的仓库
数据库的特点:
1.持久化存储数据的,其实数据库就是一个文件系统
2.方便存储和管理数据
3.使用了统一的方式操作数据库 SQL
MySQL :开源免费的数据库,小型的数据库,已经被Oracle收购,MySQL6.x版本也开始收费

MySQL的卸载
1.去MySQL的安装目录找到my.ini文件
datadir=“C:/ProgramData/MySQL/MySQL Server 5.5/Data/”
2.卸载mysql
3.删除C:/ProgramData目录下的MySQL文件夹
MySQL服务 后天程序 没有页面
通过:window10 控制面板->系统和安全->管理工具->服务
第二种:
win+r service.msc 也可以打开服务
net stop mysql 命令:结束MySQL的服务
net start mysql 命令:启动MySQL的服务
MySQL登录:
1.mysql -uroot -p密码
2.mysql -hip -uroot -p连接目标的密码
3.mysql --host=ip --user=root --password=连接目标的密码
MySQL退出:
1.exit
2.quit
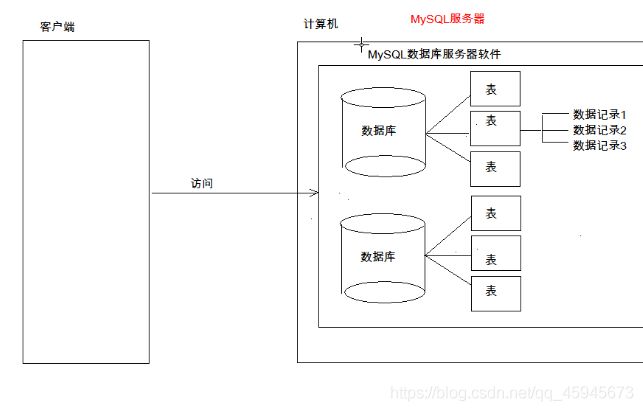
MySQL的目录
1.mysql安装目录
配置文件 my.ini
2.MySQL数据目录
数据库:文件夹
表:文件
数据:文件的内容
SQL
什么是SQL?
structured Query Language:结构化查询语言
其实就是定义了操作所有关系性数据库的规则(DBMS)
每一种数据库操作的方式存在不一样的地方 称为方言
SQL通用语法
1.SQL语句可以单行或多行书写,以分号结尾
2.可以使用空格和缩进来增加语句的可延续
3.MySQL数据的SQL语句不区分大小写,关键字建议使用大写
3中注释
单行注释:-- 注释内容 或 # 注释内容 (MySQL特有)
多行注释:/* 注释 */
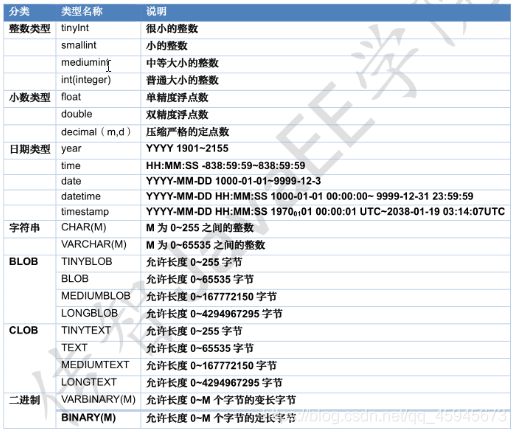
SQL分类

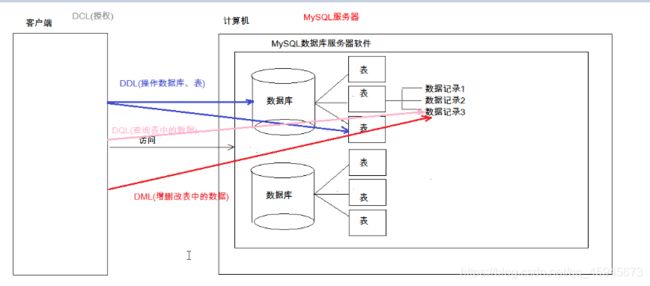
DDL:操作数据库,表
1.操作数据库:CRUD
1.C(create ):创建
create database 数据库名称;
创建数据库,判断不存在,在创建;
create database if not exists 数据库名称;
创建数据库,并指定字符集
create database 数据库名称,character 字符集名称
创建db4数据库,判断是否存在,并制定字符集gbk
create database db4 if not exists db4 character set gbk;
2.R(Retrieve):查询
查询所有数据库的名称:
show database;
查询某个数据库的字符集,查询某个数据库的创建语句
show create database 数据库名称;
3.U(update):修改
修改数据库的字符集
alter database 数据库名称 character set 字符集名称;
4.D(Delete):删除
删除数据库
drop database 数据库名称;
判断数据库存在,存在在删除
drop database if exists 数据库名称;
5.使用数据库
查询当前正在使用的数据库名称
select database();
使用数据库
use 数据库名称;
2 操作表
1.C(create ):创建
语法:
create table 表名(
列名1 数据类型1,
列名2 数据类型2,
…
列名n 数据类型n
);
数据类型:
1.
int :整数类型
age int,
2.double :小数类型
score double(5,2)
3.date 日期,只包含年月日,yyyy-MM-dd
4.datetime:日期,包含年月日时分秒 yyyy-MM-dd HH:mm:ss
5.timestamp:时间错类型, 包含年月日时分秒, yyyy-MM-dd HH:mm:ss
注意:如果将来不给这个字段赋值,或赋值为null 则默认使用当前系统时间,来自动赋值
6.varchar:字符串
name varchar(20):姓名最大10个字符
zhangsan 8个字符 张三 2个字符
创建表:
create tables(
id int,
name varchar(32),
age int,
socre double(4,1),
birthday date,
insert_time timestamp
);
注意:最后一列,不需要逗号。
复制表
create table 表名 like 被复制的表名;
create table stu like student;
2.R(Retrieve):查询
查询某个数据库中所有的表名称
show tables;
查询表结构
desc 表名;
查询表结构;
desc 表名;
3.U(update):修改
修改表名:
alter table 表名 rename to 新的表名;
alter table student rename to stu;
修改表的字符集
alter table 表名character set 字符集
添加一列
alter table 表名 add 列名 数据类型;
alter table student add nihao varchar(21);
修改列名称 类型
alter table 表名 change 列名 新列名 新数据类型;
alter table 表名 modify 列 数据类型;
删除列
alter table 表名 dorp 列名;
4.D(Delete):删除
drop table 表名;
drop table if exists 表名;
DML:增删改表中的数据
1.添加数据:
inset into 表名 (列名1,列名2,)values(值1,值2);
注意:
1.列名和值要一一对应
2.如果表名后,不定义列名 则默认给所有列添加值
inset into 表名 values(值1.。。。值n);
3.除了数字类型,其他类型需要使用引号(单双都可以)引起来
2.删除数据:
语法:
delete from 表名 【where 条件】
delete from student where id=1;
注意:
1.如果不加条件,则删除表中所有的记录
2.如果删除所有记录
1.delete from 表名:-- 不推荐使用,有多少条记录就会执行多少次操作,效率低
2.truncate table 表名:-- 先删除表,然后在创建一张一样的表 ,效率高。
3.修改数据
语法:
update 表名 set 列名1=值1,列名2=值2,… [where 条件]
UPDATE student SET age=111,score=100 WHERE id=1;
注意:
1.如果不加任何条件,则会将表中所有的记录全部修改
DQL:查询表中的记录
select * from 表名;
1.语法:
select
字段列表
from
表名列表
where
条件列表
group by
分组字段
order by
分组之后的条件
limit
分页限定
2.基础查询
1.多个字段的查询
select 字段名1,字段名2…from 表名;
注意:如果查询所有的字段,则可以使用*来替代字段列表
2.去除重复:
- distinct
3.计算列
*一般可以使用四则运算计算一些列的值(一般只会进行数值型的计算)
*ifnull(表达式1,表达式2):null 参与的运算,计算的结果都为null
表达1:那个字段需要判断是否为null
如果该字段为null后面的替换值
4.起别名:
as :as也可以省略
练习:
CREATE TABLE student3 (
id INT, – 编号
NAME VARCHAR(20), – 姓名
age INT, – 年龄
sex VARCHAR(5), – 性别
address VARCHAR(100), – 地址
math INT, – 数学
english INT – 英语
);
INSERT INTO student3(id,NAME,age,sex,address,math,english) VALUES (1,‘马云’,55,‘男’,’
杭州’,66,78),(2,‘马化腾’,45,‘女’,‘深圳’,98,87),(3,‘马景涛’,55,‘男’,‘香港’,56,77),(4,'柳岩
',20,‘女’,‘湖南’,76,65),(5,‘柳青’,20,‘男’,‘湖南’,86,NULL),(6,‘刘德华’,57,‘男’,'香港
',99,99),(7,‘马德’,22,‘女’,‘香港’,99,99),(8,‘德玛西亚’,18,‘男’,‘南京’,56,65);
SHOW TABLES;
SELECT *FROM student3;
– 去除重复的结果集
SELECT DISTINCT address FROM student;
SELECT DISTINCT NAME,address FROM student;
计算math 和English 分数之和(如果有null,参与的运算 计算结果都为null)
SELECT NAME ,math,english ,math+IFNULL(english,0) FROM student;
–起别名
SELECT NAME ,math,english ,math+IFNULL(english,0) AS 总分 FROM student;
as 可以省略!
3.条件查询
1.where 子句后跟条件
2.运算符
*> < >= <= = <>
*BETWEEN…AND
*IN(集合)
*LIKE
- IS NULL
-
- AND 或&&
- or 或 ||
- not 或 !
–年龄在 20至30之间
–年龄是 10 20 23
SELECT *FROM student WHERE age BETWEEN 20 AND 30;
SELECT *FROM student WHERE age IN (10,20,23);
–查询英语成绩为null
SELECT *FROM student WHERE english IS NULL;
–查询英语成绩不为null
SELECT *FROM student WHERE english IS NOT NULL;
- LIKE:模糊查询
- *占位符:
-
*_:单个任意字符 -
*%:多个任意字符
– 查询姓马的
SELECT *FROM student WHERE NAME LIKE “马%”;
– 查询姓名第二字是化的 人
SELECT *FROM student WHERE NAME LIKE “化%";
– 查询三个字的姓名的人
SELECT * FROM student WHERE NAME LIKE "__”;
– 查询所有包含有德的人
SELECT *FROM student WHERE NAME LIKE “%德%”;
day2
DQL:查询语句
1.排序查询
*语法:order by 子句
order by 排序字段1 排序方式1 ,排序字段2 排序方式…
*排序方式:
ASC:升序 (默认的)
* DESC: 降序
* SELECT FROM student ORDER BY math ASC;
SELECT *FROM student ORDER BY math DESC;
SELECT FROM student ORDER BY math ASC ,english DESC;
* 注意:
* 如果有多个排序条件,则当前的条件值一样时,才会判断第二条件
2.聚合函数: 将一列数据作为一个整体,经i选哪个纵向的计算
count:计算格数
max: 计算最大值
min:计算最小值
sun:计算和
avg:计算平均值
SELECT COUNT(id)FROM student;
SELECT COUNT()FROM student;
SELECT COUNT(IFNULL(english,0))FROM student;
SELECT MAX(math)FROM student;
SELECT MIN(math)FROM student;
SELECT SUM(math)FROM student;
SELECT AVG(math)FROM student;
*注意:聚合函数的计算,派出null值
解决方案:
1.选择不包含非空的列进行计算
2.IFNULL函数
3.分组查询
*语法:group by 分组字段;
– 按照性别,分别查询 男 女同学的平均分
SELECT sex,AVG(math)FROM student GROUP BY sex;
– 按照性别,分别查询 男 女同学的平均分 人数
SELECT sex,AVG(math), COUNT(id)FROM student GROUP BY sex;
– 按照性别,分别查询 男 女同学的平均分 人数 分数低于70不参与分组
SELECT sex,AVG(math), COUNT(id)FROM student WHERE math>70 GROUP BY sex;
– 按照性别,分别查询 男 女同学的平均分 人数 分数低于70不参与分组 分组之后人数大于2个
SELECT sex,AVG(math), COUNT(id)FROM student WHERE math>70 GROUP BY sex HAVING COUNT(id)>2;
注意:
1.分组之后查询的字段:分组字段,聚合函数
2.where 和having 的区别?
1.where在分组之前进行限定,如果不满足条件,则不参与分组,having在分组之后进行 限定,如果不满足结果,则不会被查询出来。
2.where后不可以跟聚合函数,having可以进行聚合函数的判断
在聚合函数后面起别名 having 后面就可以根据起的别名进行判断。
4.分页查询
*语法:limit 开始索引,每页查询的条数;
公式:开始的索引=(当前的页码-1)*每页显示的条数
例如第二页:(2-1)*3=6
– 每页显示3条记录
SELECT *FROM student LIMIT 0,3;-- 第一页
SELECT *FROM student LIMIT 3,3;-- 第二页
SELECT *FROM student LIMIT 6,3;-- 第三页
注意:limit是一个mysql的 方言
前面四个模块的都是单表查询
约束
概念:对表中的数据进行限定,保证数据的正确性,有效性和完整性
四种约束的分类
按住shift+tab 缩进回来
1.主键约束:primary key
注意:
1. 含义:并且且唯一
2.一张表只能有一个字段为主键
3.主键就是表中记录的唯一标识
– 删除主键
ALTER TABLE stu DROP PRIMARY KEY;
– 创建完表后,添加主键
ALTER TABLE stu MODIFY id INT PRIMARY KEY;
自动增长: 只跟上一条记录有关
- 概念:如果某一列的数值类型的,使用auto_increment 可以来完成值的自动增长
CREATE TABLE stu(
id INT PRIMARY KEY AUTO_INCREMENT,
NAME VARCHAR(32)
);
– 删除自动增长
ALTER TABLE stu MODIFY id INT;
– 添加自动增长
ALTER TABLE stu MODIFY id INT AUTO_INCREMENT;
2.非空约束:not null 某一列的值不能为null
– 创建表添加非空约束
CREATE TABLE stu(
id INT,
NAME VARCHAR(32) NOT NULL
);
– 删除name的非空约束
ALTER TABLE stu MODIFY NAME VARCHAR(20);
– 创建表完后,添加非空约束
ALTER TABLE stu MODIFY NAME VARCHAR(30) NOT NULL;
3.唯一约束:unique 某一列的值不能重复
1.注意:
*唯一约束可以有null值,但是只能有一条记录为null
2. – 在创建表时,添加是唯一约束
CREATE TABLE stu(
id INT,
phone_name VARCHAR(32) UNIQUE
);
3 – 删除唯一约束
ALTER TABLE stu DROP INDEX phone_name ;
4 – 在创建表完成后,添加唯一约束
ALTER TABLE stu MODIFY phone_name VARCHAR(32) UNIQUE;
4.外键约束:foreign key 让表产生关系,从而保证数据的正确性
1.在创建表时,可以添加外键
*语法:
create table 表名(
语法:
。。。。
外键列
constranint 外键名称 foregin key 外键列名称 references 主表名称(主表列名称)
);
2,删除外键
alter table 表名 drop foreign key 外键名称;
3.创建表之后,添加外键
alter table 表名 add constraint 外键名称 forgeign key(外键字段名称) references 主表名称(主表列名称);

多表之间的关系

实现方式
一对多

在多的一方建立外键,指向一的一方的主键
实现方式
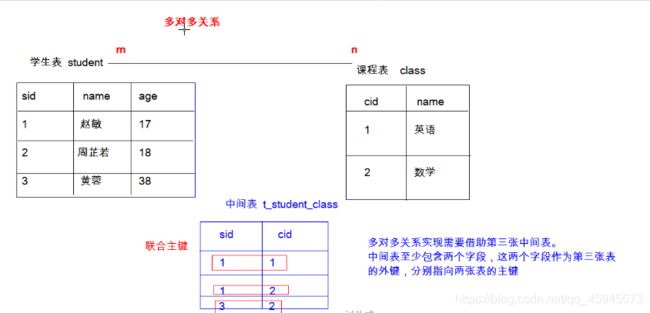
多对多
必须有两个字段
实现方式
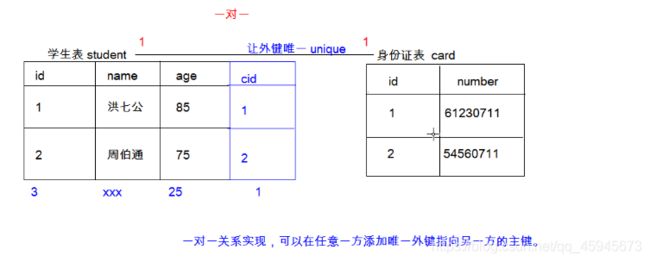
一对一
案例
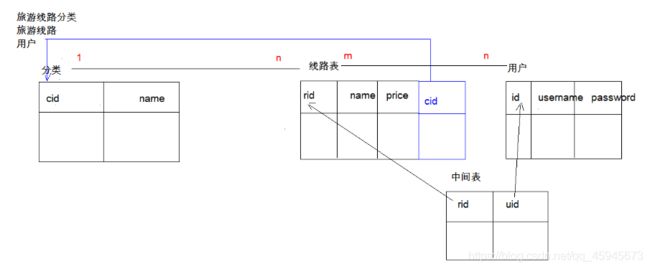
– 创建旅游线路分类表 tab_category
– cid 旅游线路分类主键,自动增长
– cname 旅游线路分类名称非空,唯一,字符串 100
create table tab_category (
cid int primary key auto_increment,
cname varchar(100) not null unique
)
– 添加旅游线路分类数据:
insert into tab_category (cname) values (‘周边游’), (‘出境游’), (‘国内游’), (‘港澳游’);
select * from tab_category;
– 创建旅游线路表 tab_route
/
rid 旅游线路主键,自动增长
rname 旅游线路名称非空,唯一,字符串 100
price 价格
rdate 上架时间,日期类型
cid 外键,所属分类
/
create table tab_route(
rid int primary key auto_increment,
rname varchar(100) not null unique,
price double,
rdate date,
cid int,
foreign key (cid) references tab_category(cid)
)
– 添加旅游线路数据
INSERT INTO tab_route VALUES
(NULL, ‘【厦门+鼓浪屿+南普陀寺+曾厝垵 高铁 3 天 惠贵团】尝味友鸭面线 住 1 晚鼓浪屿’, 1499,
‘2018-01-27’, 1),
(NULL, ‘【浪漫桂林 阳朔西街高铁 3 天纯玩 高级团】城徽象鼻山 兴坪漓江 西山公园’, 699, ‘2018-02-
22’, 3),
(NULL, ‘【爆款¥1699 秒杀】泰国 曼谷 芭堤雅 金沙岛 杜拉拉水上市场 双飞六天【含送签费 泰风情 广州
往返 特价团】’, 1699, ‘2018-01-27’, 2),
(NULL, ‘【经典•狮航 ¥2399 秒杀】巴厘岛双飞五天 抵玩【广州往返 特价团】’, 2399, ‘2017-12-23’,
2),
(NULL, ‘香港迪士尼乐园自由行 2 天【永东跨境巴士广东至迪士尼去程交通+迪士尼一日门票+香港如心海景酒店
暨会议中心标准房 1 晚住宿】’, 799, ‘2018-04-10’, 4);
select * from tab_route;
/
创建用户表 tab_user
uid 用户主键,自增长
username 用户名长度 100,唯一,非空
password 密码长度 30,非空
name 真实姓名长度 100
birthday 生日
sex 性别,定长字符串 1
telephone 手机号,字符串 11
email 邮箱,字符串长度 100
/
create table tab_user (
uid int primary key auto_increment,
username varchar(100) unique not null,
password varchar(30) not null,
name varchar(100),
birthday date,
sex char(1) default ‘男’,
telephone varchar(11),
email varchar(100)
)
– 添加用户数据
INSERT INTO tab_user VALUES
(NULL, ‘cz110’, 123456, ‘老王’, ‘1977-07-07’, ‘男’, ‘13888888888’, ‘[email protected]’),
(NULL, ‘cz119’, 654321, ‘小王’, ‘1999-09-09’, ‘男’, ‘13999999999’, ‘[email protected]’);
select * from tab_user;
/
创建收藏表 tab_favorite
rid 旅游线路 id,外键
date 收藏时间
uid 用户 id,外键
rid 和 uid 不能重复,设置复合主键,同一个用户不能收藏同一个线路两次
*/
create table tab_favorite (
rid int,
date datetime,
uid int,
– 创建复合主键
primary key(rid,uid),
foreign key (rid) references tab_route(rid),
foreign key(uid) references tab_user(uid)
)
范式

数据库的备份和还原
1.命令行:
语法:
备份:mysqldump -u账户 -p密码 数据库名称>保存的路径
还原:
1.登录数据库
2.创建数据库
3.使用数据库
4.执行文件 。source 文件路径
2.图形化工具
day3
例子:
#创建部门表
CREATE TABLE dept(
id INT PRIMARY KEY AUTO_INCREMENT,
NAME VARCHAR(20)
)
INSERT INTO dept (NAME) VALUES (‘开发部’),(‘市场部’),(‘财务部’);
#创建员工表
CREATE TABLE emp (
id INT PRIMARY KEY AUTO_INCREMENT,
NAME VARCHAR(10),
gender CHAR(1), – 性别
salary DOUBLE, – 工资
join_date DATE, – 入职日期
dept_id INT,
FOREIGN KEY (dept_id) REFERENCES dept(id)
)
– 外键,关联部门表(部门表的主键) )
INSERT INTO emp(NAME,gender,salary,join_date,dept_id) VALUES(‘孙悟空’,‘男’,7200,‘2013-02-24’,1);
INSERT INTO emp(NAME,gender,salary,join_date,dept_id) VALUES(‘猪八戒’,‘男’,3600,‘2010-12-02’,2);
INSERT INTO emp(NAME,gender,salary,join_date,dept_id) VALUES(‘唐僧’,‘男’,9000,‘2008-08-08’,2);
INSERT INTO emp(NAME,gender,salary,join_date,dept_id) VALUES(‘白骨精’,‘女’,5000,‘2015-10-07’,3);
INSERT INTO emp(NAME,gender,salary,join_date,dept_id) VALUES(‘蜘蛛精’,‘女’,4500,‘2011-03-14’,1);
笛卡尔积:
有两个集合 A,B取这两个集合的所有组成情况
要完成多表查询,需要消除无用的数据
多表的查询
多表查询的分类:
1.内连接查询
隐式的内连接:
– 查询所有员工信息和对应的部门信息
SELECT * FROM emp,dept WHERE emp.dept_id=dept.id;
– 查询员工表的名称,性别,部门表的名称
SELECT emp.name, emp.gender, dept.name FROM emp,dept WHERE emp.dept_id=dept.id;
– 简化
SELECT
t1.name,
t1.gender,
t2.name
FROM
emp t1,
dept t2
WHERE
t1.id=t2.id;
显示内连接
语法:select 字段列表 from 表名1(inner)join 表名2 on 条件
例如:
SELECT *FROM emp INNER JOIN dept ON emp.dept_id=dept.id;
SELECT *FROM emp JOIN dept ON emp.dept_id=dept.id;
使用内连接查询的条件:
1.从哪些表中查询数据
2.条件是什么
3.查询哪些字段
2.外连接查询
1.左外连接
*语法:select 字段列表 from 表1 left(outer) join 表2 on 条件
- 查询的是左表所有数据以及其交集部分 交集部分就是条件( t1.
dept_id=t2.`id) - 其实内连接就是查询交集的部分
– 查询所有的员工信息,如果员工有部门,则查询部门名称,没有部门,则不显示部门名称
SELECT t1.,t2.nameFROM emp t1 LEFT JOIN dept t2 ON t1.dept_id=t2.id;
2.右外连接 *
*语法:select 字段列表 from 表1 right(outer) join 表2 on 条件
查询的是右表所有数据以及其交集部分
怎么区分左右表呢?
emp t1 LEFT JOIN dept t2
emp就称为左表
dept就称为右表
3.子查询
概念:查询中嵌套查询,称嵌套查询为子查询
– 查询工资最高的员工信息
– 查询最高的工资是多少
SELECT MAX(salary) FROM emp;
– 查询员工信心, 并且工资等于9000的
SELECT *FROM emp WHERE emp.salary=9000;
– 一条sql就完成这个操作 子查询
SELECT *FROM emp WHERE emp.salary=(SELECT MAX(salary) FROM emp);
子查询不同情况
1.子查询的结果是单行单列的:
*子查询可以作为条件,使用运算符去判断 运算符:> < >= <= =
– 查询员工工资小于平均工资的人
SELECT * FROM emp WHERE emp.salary<(SELECT AVG(salary)FROM emp);
2.子查询的结果是多行单列的:
*子查询可以作为条件,使用运算符in来判断
– 查询 财务部和市场部所有的员工信息
SELECT id FROM dept WHERE NAME='财务部’OR NAME=‘市场部’;
SELECT *FROM emp WHERE dept_id=3 OR dept_id=2;
SELECT *FROM emp WHERE dept_id IN(SELECT id FROM dept WHERE NAME='财务部’OR NAME=‘市场部’);
3.子查询的结果是多行多列的:
*子查询可以作为一张虚拟表参与查询
– 查询员工入职日期2011-11-11日之后的员工信息和部门信息
SELECT * FROM emp WHERE emp.join_date>‘2011-11-11’;
SELECT *FROM dept t1,(SELECT * FROM emp WHERE emp.join_date>‘2011-11-11’) t2
WHERE t1.id=t2.dept_id;
– 普通内连接
SELECT *FROM emp t1,dept t2 WHERE t1.dept_id=t2.idAND t1.join_date>‘2011-11-11’;
多表查询的练习
– 部门表
CREATE TABLE dept (
id INT PRIMARY KEY PRIMARY KEY, – 部门id
dname VARCHAR(50), – 部门名称
loc VARCHAR(50) – 部门所在地
);
– 添加4个部门
INSERT INTO dept(id,dname,loc) VALUES
(10,‘教研部’,‘北京’),
(20,‘学工部’,‘上海’),
(30,‘销售部’,‘广州’),
(40,‘财务部’,‘深圳’);
– 职务表,职务名称,职务描述
CREATE TABLE job (
id INT PRIMARY KEY,
jname VARCHAR(20),
description VARCHAR(50)
);
– 添加4个职务
INSERT INTO job (id, jname, description) VALUES
(1, ‘董事长’, ‘管理整个公司,接单’),
(2, ‘经理’, ‘管理部门员工’),
(3, ‘销售员’, ‘向客人推销产品’),
(4, ‘文员’, ‘使用办公软件’);
– 员工表
CREATE TABLE emp (
id INT PRIMARY KEY, – 员工id
ename VARCHAR(50), – 员工姓名
job_id INT, – 职务id
mgr INT , – 上级领导
joindate DATE, – 入职日期
salary DECIMAL(7,2), – 工资
bonus DECIMAL(7,2), – 奖金
dept_id INT, – 所在部门编号
CONSTRAINT emp_jobid_ref_job_id_fk FOREIGN KEY (job_id) REFERENCES job (id),
CONSTRAINT emp_deptid_ref_dept_id_fk FOREIGN KEY (dept_id) REFERENCES dept (id)
);
– 添加员工
INSERT INTO emp(id,ename,job_id,mgr,joindate,salary,bonus,dept_id) VALUES
(1001,‘孙悟空’,4,1004,‘2000-12-17’,‘8000.00’,NULL,20),
(1002,‘卢俊义’,3,1006,‘2001-02-20’,‘16000.00’,‘3000.00’,30),
(1003,‘林冲’,3,1006,‘2001-02-22’,‘12500.00’,‘5000.00’,30),
(1004,‘唐僧’,2,1009,‘2001-04-02’,‘29750.00’,NULL,20),
(1005,‘李逵’,4,1006,‘2001-09-28’,‘12500.00’,‘14000.00’,30),
(1006,‘宋江’,2,1009,‘2001-05-01’,‘28500.00’,NULL,30),
(1007,‘刘备’,2,1009,‘2001-09-01’,‘24500.00’,NULL,10),
(1008,‘猪八戒’,4,1004,‘2007-04-19’,‘30000.00’,NULL,20),
(1009,‘罗贯中’,1,NULL,‘2001-11-17’,‘50000.00’,NULL,10),
(1010,‘吴用’,3,1006,‘2001-09-08’,‘15000.00’,‘0.00’,30),
(1011,‘沙僧’,4,1004,‘2007-05-23’,‘11000.00’,NULL,20),
(1012,‘李逵’,4,1006,‘2001-12-03’,‘9500.00’,NULL,30),
(1013,‘小白龙’,4,1004,‘2001-12-03’,‘30000.00’,NULL,20),
(1014,‘关羽’,4,1007,‘2002-01-23’,‘13000.00’,NULL,10);
– 工资等级表
CREATE TABLE salarygrade (
grade INT PRIMARY KEY, – 级别
losalary INT, – 最低工资
hisalary INT – 最高工资
);
– 添加5个工资等级
INSERT INTO salarygrade(grade,losalary,hisalary) VALUES
(1,7000,12000),
(2,12010,14000),
(3,14010,20000),
(4,20010,30000),
(5,30010,99990);
– 需求:
– 1.查询所有员工信息。查询员工编号,员工姓名,工资,职务名称,职务描述
/*
分析 需要查询两个表 一个是emp job
查询条件 emp.job_id=job.id
*/
SELECT
t1.id,
t1.ename,
t1.salary,
t2.jname,
t2.description
FROM
emp t1 ,job t2
WHERE
t1.job_id=t2.id
– 2.查询员工编号,员工姓名,工资,职务名称,职务描述,部门名称,部门位置
/*
三张表
查询条件:t1.job_id=t2.id AND t1.dept_id=t3.id;
emp.
*/
SELECT
t1.id,
t1.ename,
t1.salary,
t2.jname,
t2.description,
t3.dname,
t3.loc
FROM
emp t1 ,job t2,dept t3
WHERE
t1.job_id=t2.id AND t1.dept_id=t3.id;
– 3.查询员工姓名,工资,工资等级
/*
这两张表没有关连
查询条件:
emp.salary>=salarygrade.losalary and emp.salary<=slarygrade.hisalary
emp.salary between salarygrade.losalary and slarygrade.hisalary
工资 必须在对大值和最小值之间
*/
SELECT
t1.ename,
t1.salary,
t2.grade
FROM
emp t1, salarygrade t2
WHERE
t1.salary BETWEEN t2.losalaryAND t2.hisalary;
– 4.查询员工姓名,工资,职务名称,职务描述,部门名称,部门位置,工资等级
/*
四张表
查询条件:t1.job_id=t2.id AND t1.dept_id=t3.id; emp.salary between salarygrade.losalary and slarygrade.hisalary
/
SELECT
t1.ename,
t1.salary,
t2.jname,
t2.description,
t3.dname,
t3.loc,
t4.grade
FROM
emp t1, job t2, dept t3 ,salarygrade t4
WHERE
t1.job_id=t2.idAND t1.dept_id=t3.idAND t1.salary BETWEEN t4.losalaryAND t4.hisalary;
– 5.查询出部门编号、部门名称、部门位置、部门人数
/
1.部门编号 部门名称 部门位置 dept表 部门人数 emp表
2.使用分组查询 按照emp,dept_id 完成分组 查询count(id)
3.使用子查询将第2步的查询结果和dept表进行关联查询
*/
SELECT
t1.id,t1.dname,t1.loc,t2.total
FROM
dept t1 ,
(SELECT
dept_id, COUNT(id) total
FROM
emp
GROUP BY dept_id ) t2
WHERE t1.id=t2.dept_id;
– 6.查询所有员工的姓名及其直接上级的姓名,没有领导的员工也需要查询
/*
分析: 1.姓名 emp 直接上级的姓名 emp
emp表中的id和mgr 是自关联
2条件emp.id=emp.mgr
3.查询左表的所有数据和交集数据
使用左外连接查询
*/
SELECT
t1.ename,
t1.mgr,
t2.id,
t2.ename
FROM
emp t1 LEFT JOIN emp t2 ON t1.mgr=t2.id;
事务
1.事务的基本介绍
概念:如果一个包含多个步骤的业务操作,被事务管理,那么这些操作要么同时成功,要么同时失败。

操作步骤:
1.开启事务:start transaction;
2.回滚:rollback;
3.提交:commit;

控制台gbk 数据库是uf-8

2.事务的四大特征
1.原子性:事务是原子性的 原子是不可在分割的最小操作单位 要么同时成功 要么同时失败
2.持久性:一旦事务 提交或者回滚 数据库会持久化的保存数据
3.隔离性:多个事务相互独立
4.一致性:事务操作前后,数据总量不变
3.事务隔离级别


DCL
管理用户 授权
DBA 数据库管理员
DCL:管理用户,授权
1. 管理用户
1. 添加用户:
* 语法:CREATE USER ‘用户名’@‘主机名’ IDENTIFIED BY ‘密码’;
2. 删除用户:
* 语法:DROP USER ‘用户名’@‘主机名’;
3. 修改用户密码:
UPDATE USER SET PASSWORD = PASSWORD(‘新密码’) WHERE USER = ‘用户名’;
UPDATE USER SET PASSWORD = PASSWORD(‘abc’) WHERE USER = ‘lisi’;
SET PASSWORD FOR ‘用户名’@‘主机名’ = PASSWORD(‘新密码’);
SET PASSWORD FOR ‘root’@‘localhost’ = PASSWORD(‘123’);
* mysql中忘记了root用户的密码?
1. cmd – > net stop mysql 停止mysql服务
* 需要管理员运行该cmd
2. 使用无验证方式启动mysql服务: mysqld --skip-grant-tables
3. 打开新的cmd窗口,直接输入mysql命令,敲回车。就可以登录成功
4. use mysql;
5. update user set password = password(‘你的新密码’) where user = ‘root’;
6. 关闭两个窗口
7. 打开任务管理器,手动结束mysqld.exe 的进程
8. 启动mysql服务
9. 使用新密码登录。
4. 查询用户:
– 1. 切换到mysql数据库
USE myql;
– 2. 查询user表
SELECT * FROM USER;
* 通配符: % 表示可以在任意主机使用用户登录数据库
2. 权限管理:
1. 查询权限:
– 查询权限
SHOW GRANTS FOR ‘用户名’@‘主机名’;
SHOW GRANTS FOR ‘lisi’@’%’;
2. 授予权限:
– 授予权限
grant 权限列表 on 数据库名.表名 to ‘用户名’@‘主机名’;
– 给张三用户授予所有权限,在任意数据库任意表上
GRANT ALL ON . TO ‘zhangsan’@‘localhost’;
3. 撤销权限:
– 撤销权限:
revoke 权限列表 on 数据库名.表名 from ‘用户名’@‘主机名’;
REVOKE UPDATE ON db3.account FROM ‘lisi’@’%’;



JDBC day1
JDBC就是用Java语言操作数据库
1.JDBC基本概念
概念:Java DateBase Connectivity Java 数据库连接,Java语言操作数据
JDBC本质:只是一个接口 每个数据库的规范 就是实现类的接口
其实是官方 定义的一套操作所有关系型数据库的规则,就是接口,各个数据库厂商去实现这套接口,提供数据库驱动jar包,我们可以使用这套接口(JDBC)编程,真正执行的代码是驱动jar包中的实现类
把这个上面的取消掉可以使包分层
2.快速入门
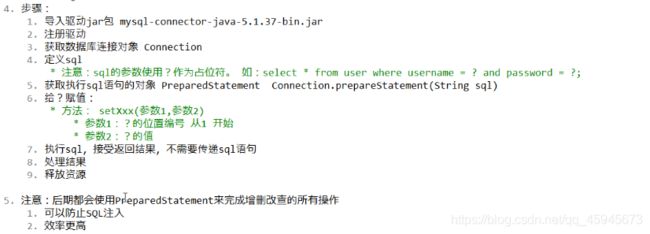
步骤:
1.导入驱动jar包
2.注册驱动
3.获取数据库连接对象 Connection
4.定义sql
5.获取执行sql语句的对象 statement
6.执行sql ,接受返回结果
7.处理结果
8.释放资源
public class jdbcDemo1 {
public static void main(String[] args) throws Exception {
Class.forName(“com.mysql.jdbc.Driver”);
Connection conn = DriverManager.getConnection(“jdbc:mysql://localhost:3306/loner”, “root”, “root”);
String sql=“UPDATE student SET age=13 WHERE id=1”;
Statement stmt = conn.createStatement();
int count = stmt.executeUpdate(sql);
System.out.println(count);
stmt.close();
conn.close();
3.对JDBC中各个接口和类详解
1.DriverManager:驱动管理对象


2.Connection:数库库连接对象
1.功能:
1.获取执行sql的对象
* statement createStatement()
* *Preparedstatement prepareStatement(String sql)
2.管理事务:
*开启事务:setAutoCommit(boolean autoCommit):调用该方法设置参数为false 即开启事务
*提交事务:commit()
*回滚事务:rollback()
3.Statement:执行sql的对象
1.执行sql
1.boolean execute(string sql):可以执行任意的sql 了解
2.int executeUpdate(string sql):执行DML(执行增删改)(inset update delete)语句 DDL(create alter drop)语句。
*返回值:影响的行数,可以通过这个影响的行数判断DML语句是否执行成功,返回值>0的则执行成功 反之 则失败
3.ResultSet executeQuery(string sql):执行DQL(select)语句
什么是内存泄漏?
内存用着用着就小了,为什么会小 因为程序一直有垃圾注入的内存里面没有被释放,内存积压的就会越来越多。
提升作用域 判断释放资源的是否为null 防止空指针异常
public class jdbcDemo2 {
public static void main(String[] args) {
Connection conn=null;
Statement sta=null;
try {
Class.forName(“com.mysql.jdbc.Driver”);
String sql=“INSERT INTO student VALUES(10,‘莅临为’,12,‘男’,‘杭州’,23,24 )”;
conn = DriverManager.getConnection(“jdbc:mysql:///loner”, “root”, “root”);
sta = conn.createStatement();
int count = sta.executeUpdate(sql);
System.out.println(count);
if (count>0){
System.out.println(“添加成功”);
}else {
System.out.println(“添加失败”);
}
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (SQLException e) {
e.printStackTrace();
}finally {
if (sta!=null){
try {
sta.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if (conn!=null){
try {
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
}
}
5.ResultSet:结果集对象,封装查询结果
列表就是一个结果对象
结果集对象也是一种资源 也要关闭他。
*boolean next():游标向下移动一行,判断当前行是否是最后一行末尾(是否有数据),如果是,则返回false 如果不是则返回true
*getXxx(参数):获取数据
*Xxx:代表数据类型 如: int getInt(), String getString()
参数:
1.int :代表列的编号 从1开始 如: getstring(1)
2.string :代表列名称 如: getDouble(“balance”)
注意:
使用步骤:
1.游标向下移动一行
2.判断是否有数据
3.获取数据
public static void main(String[] args) {
Connection conn = null;
Statement stmt = null;
ResultSet rs = null;
try {
//1. 注册驱动
Class.forName(“com.mysql.jdbc.Driver”);
//2.获取连接对象
conn = DriverManager.getConnection(“jdbc:mysql:///db3”, “root”, “root”);
//3.定义sql
String sql = “select * from account”;
//4.获取执行sql对象
stmt = conn.createStatement();
//5.执行sql
rs = stmt.executeQuery(sql);
//6.处理结果
//循环判断游标是否是最后一行末尾。
while(rs.next()){
//获取数据
//6.2 获取数据
int id = rs.getInt(1);
String name = rs.getString(“name”);
double balance = rs.getDouble(3);
System.out.println(id + “—” + name + “—” + balance);
}
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (SQLException e) {
e.printStackTrace();
} finally {
//7.释放资源
if(rs != null){
try {
rs.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if(stmt != null){
try {
stmt.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if(conn != null){
try {
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
}
练习:
定义一个方法,查询emp表的数据将其封装为对象,然后装载集合,返回。
1.定义Emp类
/
-
封装Emp表数据的JavaBean
/
public class Emp {
private int id;
private String ename;
private int job_id;
private int mgr;
private Date joindate;
private double salary;
private double bonus;
private int dept_id;
get和set tostring 方法省略
2.定义方法 public Llist findAll(){}
/* -
- 定义一个方法,查询emp表的数据将其封装为对象,然后装载集合,返回。
*/
public class JDBCDemo8 {
public static void main(String[] args) {
List list = new JDBCDemo8().findAll2();
System.out.println(list);
System.out.println(list.size());
}
/**-
查询所有emp对象
-
@return
*/
public List findAll(){
Connection conn = null;
Statement stmt = null;
ResultSet rs = null;
List list = null;
try {
//1.注册驱动
Class.forName(“com.mysql.jdbc.Driver”);
//2.获取连接
conn = DriverManager.getConnection(“jdbc:mysql:///db3”, “root”, “root”);
//3.定义sql
String sql = “select * from emp”;
//4.获取执行sql的对象
stmt = conn.createStatement();
//5.执行sql
rs = stmt.executeQuery(sql);
//6.遍历结果集,封装对象,装载集合
Emp emp = null;
list = new ArrayList();
while(rs.next()){
//获取数据
int id = rs.getInt(“id”);
String ename = rs.getString(“ename”);
int job_id = rs.getInt(“job_id”);
int mgr = rs.getInt(“mgr”);
Date joindate = rs.getDate(“joindate”);
double salary = rs.getDouble(“salary”);
double bonus = rs.getDouble(“bonus”);
int dept_id = rs.getInt(“dept_id”);
// 创建emp对象,并赋值
emp = new Emp();
emp.setId(id);
emp.setEname(ename);
emp.setJob_id(job_id);
emp.setMgr(mgr);
emp.setJoindate(joindate);
emp.setSalary(salary);
emp.setBonus(bonus);
emp.setDept_id(dept_id);
//装载集合
list.add(emp);
}} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (SQLException e) {
e.printStackTrace();
}finally {
if(rs != null){
try {
rs.close();
} catch (SQLException e) {
e.printStackTrace();
}
}if(stmt != null){ try { stmt.close(); } catch (SQLException e) { e.printStackTrace(); } } if(conn != null){ try { conn.close(); } catch (SQLException e) { e.printStackTrace(); } }}
return list;
}
3.实现方法 select * from emp;
获取完数据封装对象(会引用很多emp 占内存 创建emp应用 然后复用就可以了)
装载集合肯定要在遍历之前
6.Preparedstatement:执行sql的对象
1.Sql注入问题:在拼接sql时,有一些sql的特殊关键字与字符串的拼接,会造成安全性问题
1.输入用户随便,输入密码:a’ or ‘a’ = ‘a
2.sql:select * from user where username =‘sdfsdfas’ and password=a’ or ‘a’ = 'a
2.解决sql注入问题:使用preparedstatement对象来解决
3.预编译的SQL:参数使用?作为占位符
练习 在案例里面login2
- 定义一个方法,查询emp表的数据将其封装为对象,然后装载集合,返回。
抽取JDBC工具类:JDBCUtuils
目的:简化书写
分析:
1.注册驱动也抽取
2.抽取一个方法获取连接对象
3.抽取一个方法释放资源
静态代码块给成员变量一赋值就可以用了
/**
*** JDBC工具类**
/
public class JDBCUtils {
private static String url;
private static String user;
private static String password;
private static String driver;
/*
* 文件的读取,只需要读取一次即可拿到这些值。使用静态代码块
/
static{
//读取资源文件,获取值。
try {
//1. 创建Properties集合类。
Properties pro = new Properties();
//获取src路径下的文件的方式—>ClassLoader 类加载器
ClassLoader classLoader = JDBCUtils.class.getClassLoader();
URL res = classLoader.getResource(“jdbc.properties”);
String path = res.getPath();
// System.out.println(path);///D:/IdeaProjects/itcast/out/production/day04_jdbc/jdbc.properties
//2. 加载文件
// pro.load(new FileReader(“D:\IdeaProjects\itcast\day04_jdbc\src\jdbc.properties”));
pro.load(new FileReader(path));
//3. 获取数据,赋值
url = pro.getProperty(“url”);
user = pro.getProperty(“user”);
password = pro.getProperty(“password”);
driver = pro.getProperty(“driver”);
//4. 注册驱动
Class.forName(driver);
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
/*
* 获取连接
* @return 连接对象
/
public static Connection getConnection() throws SQLException {
return DriverManager.getConnection(url, user, password);
}
/*
* 释放资源
* @param stmt
* @param conn
/
public static void close(Statement stmt,Connection conn){
if( stmt != null){
try {
stmt.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if( conn != null){
try {
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
/*
* 释放资源
* @param stmt
* @param conn
/
public static void close(ResultSet rs,Statement stmt, Connection conn){
if( rs != null){
try {
rs.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if( stmt != null){
try {
stmt.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if( conn != null){
try {
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
}
练习:
需求:
1.通过键盘录入用户名和密码
2.判断用户是否登录成功
/*
- 练习:
-
* 需求: -
1. 通过键盘录入用户名和密码 -
2. 判断用户是否登录成功
/
public class JDBCDemo9 {
public static void main(String[] args) {
//1.键盘录入,接受用户名和密码
Scanner sc = new Scanner(System.in);
System.out.println(“请输入用户名:”);
String username = sc.nextLine();
System.out.println(“请输入密码:”);
String password = sc.nextLine();
//2.调用方法
boolean flag = new JDBCDemo9().login2(username, password);
//3.判断结果,输出不同语句
if(flag){
//登录成功
System.out.println(“登录成功!”);
}else{
System.out.println(“用户名或密码错误!”);
}
}
/*
* 登录方法
/
public boolean login(String username ,String password){
if(username == null || password == null){
return false;
}
//连接数据库判断是否登录成功
Connection conn = null;
Statement stmt = null;
ResultSet rs = null;
//1.获取连接
try {
conn = JDBCUtils.getConnection();
//2.定义sql
String sql = “select * from user where username = '”+username+"’ and password = ‘"+password+"’ ";
System.out.println(sql);
//3.获取执行sql的对象
stmt = conn.createStatement();
//4.执行查询
rs = stmt.executeQuery(sql);
//5.判断
/ if(rs.next()){//如果有下一行,则返回true
return true;
}else{
return false;
}/
return rs.next();//如果有下一行,则返回true
} catch (SQLException e) {
e.printStackTrace();
}finally {
JDBCUtils.close(rs,stmt,conn);
}
return false;
}
/**
* 登录方法,使用PreparedStatement实现
/
public boolean login2(String username ,String password){
if(username == null || password == null){
return false;
}
//连接数据库判断是否登录成功
Connection conn = null;
PreparedStatement pstmt = null;
ResultSet rs = null;
//1.获取连接
try {
conn = JDBCUtils.getConnection();
//2.定义sql
String sql = “select * from user where username = ? and password = ?”;
//3.获取执行sql的对象
pstmt = conn.prepareStatement(sql);
//给?赋值
pstmt.setString(1,username);
pstmt.setString(2,password);
//4.执行查询,不需要传递sql
rs = pstmt.executeQuery();
//5.判断
/ if(rs.next()){//如果有下一行,则返回true
return true;
}else{
return false;
}/
return rs.next();//如果有下一行,则返回true
} catch (SQLException e) {
e.printStackTrace();
}finally {
JDBCUtils.close(rs,pstmt,conn);
}
return false;
}
}
JDBC控制事务
1.事务:一个包含多个步骤的业务操作,如果这个业务操作被事务管理,则这个多个步骤要么同时成功呢,要么同时失败
2.操作:
1.开启事务
2.提交事务
3.回滚事务
3.使用connection对象来管理事务
*开启事务:setAutoCommit(boolean autoCommit):调用该方法设置参数为false 即开启事务
在执行sql之前开启事务
提交事务:commit()
当所有sql都执行完提交事务
回滚事务:rollback()
在catch中回滚事务
JDBC控制事务实现
/
- 事务操作
*/
public class JDBCDemo10 {
public static void main(String[] args) {
Connection conn = null;
PreparedStatement pstmt1 = null;
PreparedStatement pstmt2 = null;
try {
//1.获取连接
conn = JDBCUtils.getConnection();
//开启事务
conn.setAutoCommit(false);
//2.定义sql
//2.1 张三 - 500
String sql1 = “update account set balance = balance - ? where id = ?”;
//2.2 李四 + 500
String sql2 = “update account set balance = balance + ? where id = ?”;
//3.获取执行sql对象
pstmt1 = conn.prepareStatement(sql1);
pstmt2 = conn.prepareStatement(sql2);
//4. 设置参数
pstmt1.setDouble(1,500);
pstmt1.setInt(2,1);
pstmt2.setDouble(1,500);
pstmt2.setInt(2,2);
//5.执行sql
pstmt1.executeUpdate();
// 手动制造异常
int i = 3/0;
pstmt2.executeUpdate();
//提交事务
conn.commit();
} catch (Exception e) {
//事务回滚
try {
if(conn != null) {
conn.rollback();
}
} catch (SQLException e1) {
e1.printStackTrace();
}
e.printStackTrace();
}finally {
JDBCUtils.close(pstmt1,conn);
JDBCUtils.close(pstmt2,null);
}
}
}
JDBC连接池 day2
1.数据库连接池
概念:其实就是一个容器(集合),存放数据库连接的容器
当系统初始化好后,容器被创建,容器中会申请一些连接对象,当用户来访问数据库时,从容器中获取连接对象,用户访问完之后,会将连接对象归还给容器
好处:
1.节约资源
2.用户访问高效
3 实现:
1.标准接口:DataSource javax.sql包下的
方法:
*获取连接:getConnection()
*归还连接:Connection.close(),如果连接对象Connection是从连接池中获取的,那么调用Connection.close()方法,则不会再关闭连接了,而是归还连接
2.一般我们不去实现他,有数据库厂商来实现
1.C3P0:数据库连接池技术
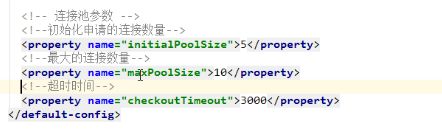
步骤:
1.导入jar包(两个)c3p0-0.9.5.2.jar mchange-commons-java-0.2.12.jar
不要忘记导入数据库驱动jar包
2.定义配置文件;
名称: c3p0.properties 或者c3p0-config.xml
路径直接将文件放在src目录下即可
3.创建核心对象 数据库连接池对象 combopooledDataSource
4.获取连接:getConnection
2.Druid:数据库连接池实现技术,由阿里巴巴提供的
步骤:
1.导入jar包 druid-1.0.9jar
2.定义配置文件
*是properties形式的
*可以叫任意名称 ,可以放在任意的目录下
获取配置文件使用properties集合
3.获取数据库连接池对象:通过工厂类来获取,Druid
4.获取连接:getConnection
public class DruidDemo {
public static void main(String[] args) throws Exception {
//1.导入jar包
//2.定义配置文件
//3.加载配置文件
/*Properties pro = new Properties();
InputStream is = DruidDemo.class.getClassLoader().getResourceAsStream(“druid.properties”);
pro.load(is);
//4.获取连接池对象
DataSource ds = DruidDataSourceFactory.createDataSource(pro);
//5.获取连接
Connection conn = ds.getConnection();
System.out.println(conn);*/
Properties pro = new Properties();
InputStream os = DruidDemo.class.getClassLoader().getResourceAsStream("druid.properties");
pro.load(os);
DataSource ds = new DruidDataSourceFactory().createDataSource(pro);
Connection conn = ds.getConnection();
System.out.println(conn);
2.定义工具类
1.定义一个类 JDBCUtils
2.提供静态代码块加载配置文件,初始化连接对象
3.提供方法
1.获取连接方法:通过数据库连接池获取连接
2.释放资源
3.获取连接池的方法
/**
-
Druid连接池的工具类
*/
public class JDBCUtils {//1.定义成员变量 DataSource
private static DataSource ds ;static{
try {
//1.加载配置文件
Properties pro = new Properties();
pro.load(JDBCUtils.class.getClassLoader().getResourceAsStream(“druid.properties”));
//2.获取DataSource
ds = DruidDataSourceFactory.createDataSource(pro);
} catch (IOException e) {
e.printStackTrace();
} catch (Exception e) {
e.printStackTrace();
}
}/**
- 获取连接
*/
public static Connection getConnection() throws SQLException {
return ds.getConnection();
}
/**
-
释放资源
/
public static void close(Statement stmt,Connection conn){
/ if(stmt != null){
try {
stmt.close();
} catch (SQLException e) {
e.printStackTrace();
}
}if(conn != null){
try {
conn.close();//归还连接
} catch (SQLException e) {
e.printStackTrace();
}
}*/close(null,stmt,conn);
}
public static void close(ResultSet rs , Statement stmt, Connection conn){
if(rs != null){
try {
rs.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if(stmt != null){
try {
stmt.close();
} catch (SQLException e) {
e.printStackTrace();
}
}if(conn != null){ try { conn.close();//归还连接 } catch (SQLException e) { e.printStackTrace(); } }}
/**
- 获取连接池方法
*/
public static DataSource getDataSource(){
return ds;
}
}
工具类测试:
public static void main(String[] args) {
/*
* 完成添加操作:给account表添加一条记录
*/
Connection conn = null;
PreparedStatement pstmt = null;
try {
//1.获取连接
conn = JDBCUtils.getConnection();
//2.定义sql
String sql = “insert into account values(null,?,?)”;
//3.获取pstmt对象
pstmt = conn.prepareStatement(sql);
//4.给?赋值
pstmt.setString(1,“王五”);
pstmt.setDouble(2,3000);
//5.执行sql
int count = pstmt.executeUpdate();
System.out.println(count);
} catch (SQLException e) {
e.printStackTrace();
}finally {
//6. 释放资源
JDBCUtils.close(pstmt,conn);
}
} - 获取连接
2.Spring JDBC :JDBC Template
- spring框架是JavaEE的灵魂框架
Spring JDBC - spring框架对JDBC的简单封装,提供了一个JDBCTemplate对象简化JDBC开发
步骤:
1.导入jar包
2.创建jdbcTemplate 对象 依赖于数据源DataSource
new JDBCTemplate(ds)
3.调用jdbcTemplate的方法来完成CRUD的操作- update():执行DML语句,增删改 语句
- queryForMap():查询结果将结果集封装为map集合,将列作为key,将值作为value,将这条记录 封装 为一个map集合
- 上面的方法:这个方法查询的结果长度只能是1
- queryForlist():查询结果将结果集封装为list集合
- 注意:将每一条记录封装为一个Map集合,再将Map集合装载道List集合中
- query():查询结果,将结果封装威JavaBean对象
- query的参数:RowMapper
-
一般我们使用BeanPropertyRowMapper实现类,可以完成数据道JavaBean的自动封装 -
new BeanPropertyRowMapper<类型>(类型.class) - queryForObject: 查询结果,将结果封装为对象
- 一般用于聚合函数的查询
CTRL +P :看看代码中需要什么
将数据查询出来,封装成JavaBean对象,然后把对象装载到List集合中
基本数据类型不能接受null ,记得使用引用数据类型

public class JdbcTemplateDemo2 {
//Junit单元测试,可以让方法独立执行
//1. 获取JDBCTemplate对象
private JdbcTemplate template = new JdbcTemplate(JDBCUtils.getDataSource());
/**
* 1. 修改1号数据的 salary 为 10000
/
@Test
public void test1(){
//2. 定义sql
String sql = “update emp set salary = 10000 where id = 1001”;
//3. 执行sql
int count = template.update(sql);
System.out.println(count);
}
/*
* 2. 添加一条记录
/
@Test
public void test2(){
String sql = “insert into emp(id,ename,dept_id) values(?,?,?)”;
int count = template.update(sql, 1015, “郭靖”, 10);
System.out.println(count);
}
/*
* 3.删除刚才添加的记录
/
@Test
public void test3(){
String sql = “delete from emp where id = ?”;
int count = template.update(sql, 1015);
System.out.println(count);
}
/*
* 4.查询id为1001的记录,将其封装为Map集合
* 注意:这个方法查询的结果集长度只能是1
/
@Test
public void test4(){
String sql = “select * from emp where id = ? or id = ?”;
Map
System.out.println(map);
//{id=1001, ename=孙悟空, job_id=4, mgr=1004, joindate=2000-12-17, salary=10000.00, bonus=null, dept_id=20}
}
/
* 5. 查询所有记录,将其封装为List
/
@Test
public void test5(){
String sql = “select * from emp”;
List
for (Map
System.out.println(stringObjectMap);
}
}
/
* 6. 查询所有记录,将其封装为Emp对象的List集合
/
@Test
public void test6(){
String sql = “select * from emp”;
List list = template.query(sql, new RowMapper() {
@Override
public Emp mapRow(ResultSet rs, int i) throws SQLException {
Emp emp = new Emp();
int id = rs.getInt(“id”);
String ename = rs.getString(“ename”);
int job_id = rs.getInt(“job_id”);
int mgr = rs.getInt(“mgr”);
Date joindate = rs.getDate(“joindate”);
double salary = rs.getDouble(“salary”);
double bonus = rs.getDouble(“bonus”);
int dept_id = rs.getInt(“dept_id”);
11
emp.setId(id);
emp.setEname(ename);
emp.setJob_id(job_id);
emp.setMgr(mgr);
emp.setJoindate(joindate);
emp.setSalary(salary);
emp.setBonus(bonus);
emp.setDept_id(dept_id);
return emp;
}
});
for (Emp emp : list) {
System.out.println(emp);
}
}
/*
* 6. 查询所有记录,将其封装为Emp对象的List集合
/
@Test
public void test6_2(){
String sql = “select * from emp”;
List list = template.query(sql, new BeanPropertyRowMapper(Emp.class));
for (Emp emp : list) {
System.out.println(emp);
}
}
/*
* 7. 查询总记录数
*/
@Test
public void test7(){
String sql = “select count(id) from emp”;
Long total = template.queryForObject(sql, Long.class);
System.out.println(total);
}
}
BeanUtils位于org.apache.commons.beanutils.BeanUtils下面,其方法populate的作用解释如下:
完整方法:
BeanUtils.populate( Object bean, Map properties ),
这个方法会遍历map
![]()
当用到BeanUtils的populate、copyProperties方法或者getProperty,setProperty方法其实都会调用convert进行转换
但Converter只支持一些基本的类型,甚至连java.util.Date类型也不支持。而且它比较笨的一个地方是当遇到不认识的类型时,居然会抛出异常来。
这个时候就需要给类型注册转换器。比如:意思是所以需要转成Date类型的数据都要通过DateLocaleConverter这个转换器的处理。
ConvertUtils.register(new DateLocaleConverter(), Date.class);
示例:

ConvertUtils除了给指定类型注册转换器外,还可以将数据转换为指定类型:

druid.properties的配置文件的书写方式:
driverClassName=com.mysql.jdbc.Driver
url=jdbc:mysql:///day14
username=root
password=root
initialSize=5
maxActive=10
maxWait=3000