Graph Convolutional Neural Network - Spectral Convolution 图卷积神经网络 — 频域卷积详解
文章目录
-
- 往期文章链接目录
- Fourier Transform
- Convolution Theorem
- Graph Fourier Transform
-
- A few definitions
- Graph Fourier transform
- Spectral-based ConvGNNs
-
- Naive Design of g θ ( Λ ) \mathbf{g}_{\theta}(\mathbf{\Lambda}) gθ(Λ)
- Chebyshev Spectral CNN (Recursive formulation for fast filtering)
-
- Polynomial parametrization for localized filters
- Chebyshev Spectral CNN (ChebNet)
- Comparison between spectral and spatial models
- 往期文章链接目录
往期文章链接目录
Fourier Transform
Virtually everything in the world can be described via a waveform - a function of time, space or some other variable. For instance, sound waves, the price of a stock, etc. The Fourier Transform gives us a unique and powerful way of viewing these waveforms: All waveforms, no matter what you scribble or observe in the universe, are actually just the sum of simple sinusoids of different frequencies.
Here is the mathematical definition of Fourier Transform F \mathcal{F} F:
F [ f ( t ) ] = ∫ f ( t ) e − i ω t d t (1) \mathcal{F}[f(t)]=\int f(t) e^{-i \omega t} d t \tag 1 F[f(t)]=∫f(t)e−iωtdt(1)
Fourier Transform decomposes a function defined in the space/time domain into several components in the frequency domain. In other words, the Fourier transform can change a function from the spatial domain to the frequency domain. Check the Graph Fourier Transform section for more details.
Convolution Theorem
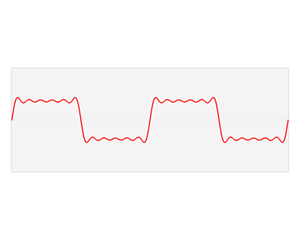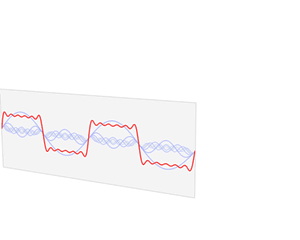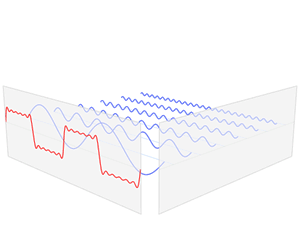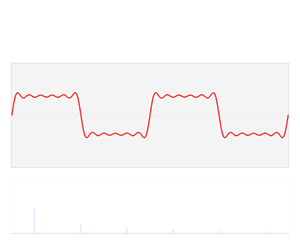
Convolution Theorem: The convolution of two functions in real space is the same as the product of their respective Fourier transforms in Fourier space.
Equivalent statement:
-
Convolution in time domain equals multiplication in frequency domain.
-
Multiplication in time equals convolution in the frequency domain.
F [ ( f ∗ g ) ( t ) ] = F ( f ( t ) ) ⊙ F ( g ( t ) ) (2) \mathscr{F}[(f * g)(t)] = \mathscr{F}(f(t)) \odot \mathscr{F}(g(t)) \tag 2 F[(f∗g)(t)]=F(f(t))⊙F(g(t))(2)
In other words, one can calculate the convolution of two functions f f f and g g g by first transforming them into the frequency domain through Fourier transform, multiplying the two functions in the frequency domain, and then transforming them back through inverse Fourier transform. The mathematical expression of this idea is
( f ∗ g ) ( t ) = F − 1 [ F ( f ( t ) ) ⊙ F ( g ( t ) ) ] (3) (f * g)(t) = \mathscr{F}^{-1}[\mathscr{F}(f(t)) \odot \mathscr{F}(g(t))] \tag 3 (f∗g)(t)=F−1[F(f(t))⊙F(g(t))](3)
where ⊙ \odot ⊙ is the element-wise product. we denote the Fourier transform of a function f f f as f ^ \hat{f} f^.
Graph Fourier Transform
A few definitions
Spectral-based methods have a solid mathematical foundation in graph signal processing. They assume graphs to be undirected.
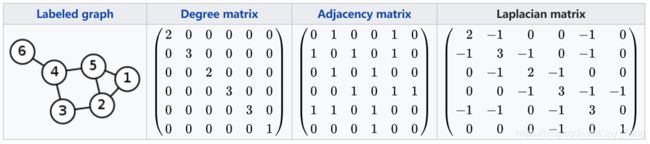
-
Adjacency matrix A \operatorname{matrix} \mathbf{A} matrixA: The adjacency matrix A \operatorname{matrix} \mathbf{A} matrixA is a n × n n \times n n×n matrix with A i j = 1 A_{i j}=1 Aij=1 if e i j ∈ E e_{i j} \in E eij∈E and A i j = 0 A_{i j}=0 Aij=0 if e i j ∉ E e_{i j} \notin E eij∈/E.
-
Degree matrix D \operatorname{matrix} \mathbf{D} matrixD: The degree matrix is a diagonal matrix which contains information about the degree of each vertex (the number of edges attached to each vertex). It is used together with the adjacency matrix to construct the Laplacian matrix of a graph.
-
Laplacian matrix L \operatorname{matrix} \mathbf{L} matrixL: The Laplacian matrix is a matrix representation of a graph, which is defined by
L = D − A (4) \mathbf{L} = \mathbf{D} - \mathbf{A} \tag 4 L=D−A(4) -
Symmetric normalized Laplacian matrix L s y s \operatorname{matrix} \mathbf{L}^{sys} matrixLsys: The normalized graph Laplacian matrix is a mathematical representation of an undirected graph
L s y s = D − 1 2 L D − 1 2 (5) \mathbf{L}^{sys} = \mathbf{D}^{-\frac{1}{2}} \mathbf{L} \mathbf{D}^{-\frac{1}{2}} \tag 5 Lsys=D−21LD−21(5)
The symmetric normalized graph Laplacian matrix possesses the property of being real symmetric positive semidefinite. With this property, the normalized Laplacian matrix can be factored as
L s y s = U Λ U T (6) \mathbf{L}^{sys}=\mathbf{U} \mathbf{\Lambda} \mathbf{U}^{T} \tag 6 Lsys=UΛUT(6)
where
U = [ u 0 , u 1 , ⋯ , u n − 1 ] ∈ R n × n (7) \mathbf{U}=\left[\mathbf{u}_{\mathbf{0}}, \mathbf{u}_{\mathbf{1}}, \cdots, \mathbf{u}_{\mathbf{n}-1}\right] \in \mathbf{R}^{n \times n} \tag 7 U=[u0,u1,⋯,un−1]∈Rn×n(7)
is the matrix of eigenvectors ordered by eigenvalues and Λ \mathbf{\Lambda} Λ is the diagonal matrix of eigenvalues (spectrum), Λ i i = λ i \Lambda_{i i}=\lambda_{i} Λii=λi. The eigenvectors of the normalized Laplacian matrix form an orthonormal space, in mathematical words U T U = I \mathbf{U}^{T} \mathbf{U}=\mathbf{I} UTU=I.
Graph Fourier transform
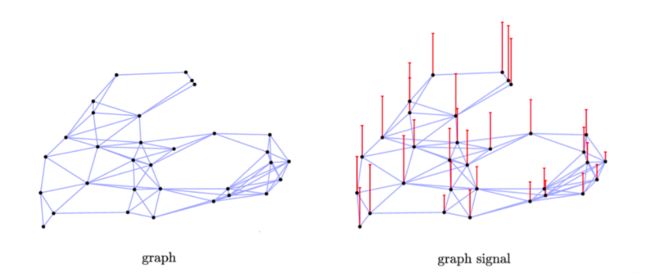
In graph signal processing, a graph signal x ∈ R n \mathbf{x} \in \mathbf{R}^{n} x∈Rn is a feature vector of all nodes of a graph where x i x_{i} xi is the value of the i t h i^{t h} ith node.
The graph Fourier transform to a signal f ^ \mathbf{\hat{f}} f^ is defined as
F ( f ) = U T f (8) \mathscr{F}(\mathbf{f})=\mathbf{U}^{T} \mathbf{f} \tag 8 F(f)=UTf(8)
and the inverse graph Fourier transform is defined as
F − 1 ( f ^ ) = U f ^ (9) \mathscr{F}^{-1}(\mathbf{\hat{f}})=\mathbf{U} \mathbf{\hat{f}} \tag 9 F−1(f^)=Uf^(9)
where f ^ \mathbf{\hat{f}} f^ represents the resulted signal from the graph Fourier transform.
Note:
-
f ^ = ( f ^ ( λ 1 ) f ^ ( λ 2 ) ⋮ f ^ ( λ n ) ) = U T f = ( u 1 ( 1 ) u 1 ( 2 ) … u 1 ( n ) u 2 ( 1 ) u 2 ( 2 ) … u 2 ( n ) ⋮ ⋮ ⋱ ⋮ u n ( 1 ) u n ( 2 ) … u n ( n ) ) ( f ( 1 ) f ( 2 ) ⋮ f ( n ) ) (10) \mathbf{\hat{f}} = \left(\begin{array}{c} \hat{f}\left(\lambda_{1}\right) \\ \hat{f}\left(\lambda_{2}\right) \\ \vdots \\ \hat{f}\left(\lambda_{n}\right) \end{array}\right)= \mathbf{U}^{T} \mathbf{f} = \left(\begin{array}{cccc} u_{1}(1) & u_{1}(2) & \ldots & u_{1}(n) \\ u_{2}(1) & u_{2}(2) & \ldots & u_{2}(n) \\ \vdots & \vdots & \ddots & \vdots \\ u_{n}(1) & u_{n}(2) & \ldots & u_{n}(n) \end{array}\right)\left(\begin{array}{c} f(1) \\ f(2) \\ \vdots \\ f(n) \end{array}\right) \tag {10} f^=⎝⎜⎜⎜⎛f^(λ1)f^(λ2)⋮f^(λn)⎠⎟⎟⎟⎞=UTf=⎝⎜⎜⎜⎛u1(1)u2(1)⋮un(1)u1(2)u2(2)⋮un(2)……⋱…u1(n)u2(n)⋮un(n)⎠⎟⎟⎟⎞⎝⎜⎜⎜⎛f(1)f(2)⋮f(n)⎠⎟⎟⎟⎞(10)
where λ i \lambda_i λi are ordered eigenvalues (biggest to smallest), N N N is the number of nodes. -
f ^ ( λ l ) = ∑ i = 1 n f ( i ) u l ( i ) (11) \mathbf{\hat{f}}(\lambda_{l})=\sum_{i=1}^{n} \mathbf{f}(i) u_{l}(i) \tag {11} f^(λl)=i=1∑nf(i)ul(i)(11)
-
f = ( f ( 1 ) f ( 2 ) ⋮ f ( n ) ) = U f ^ = ( u 1 ( 1 ) u 2 ( 1 ) … u n ( 1 ) u 1 ( 2 ) u 2 ( 2 ) … u n ( 2 ) ⋮ ⋮ ⋱ ⋮ u 1 ( n ) u 2 ( n ) … u n ( n ) ) ( f ^ ( λ 1 ) f ^ ( λ 2 ) ⋮ f ^ ( λ n ) ) (12) \mathbf{f} = \left(\begin{array}{c} f(1) \\ f(2) \\ \vdots \\ f(n) \end{array}\right)= \mathbf{U} \mathbf{\hat{f}} = \left(\begin{array}{cccc} u_{1}(1) & u_{2}(1) & \ldots & u_{n}(1) \\ u_{1}(2) & u_{2}(2) & \ldots & u_{n}(2) \\ \vdots & \vdots & \ddots & \vdots \\ u_{1}(n) & u_{2}(n) & \ldots & u_{n}(n) \end{array}\right)\left(\begin{array}{c} \hat{f}\left(\lambda_{1}\right) \\ \hat{f}\left(\lambda_{2}\right) \\ \vdots \\ \hat{f}\left(\lambda_{n}\right) \end{array}\right) \tag {12} f=⎝⎜⎜⎜⎛f(1)f(2)⋮f(n)⎠⎟⎟⎟⎞=Uf^=⎝⎜⎜⎜⎛u1(1)u1(2)⋮u1(n)u2(1)u2(2)⋮u2(n)……⋱…un(1)un(2)⋮un(n)⎠⎟⎟⎟⎞⎝⎜⎜⎜⎛f^(λ1)f^(λ2)⋮f^(λn)⎠⎟⎟⎟⎞(12)
The graph Fourier transform projects the input graph signal to the orthonormal space where the basis is formed by independent eigenvectors ( u 0 , u 1 , ⋯ , u n − 1 \mathbf{u}_{\mathbf{0}}, \mathbf{u}_{\mathbf{1}}, \cdots, \mathbf{u}_{\mathbf{n}-1} u0,u1,⋯,un−1) of the normalized graph Laplacian. Elements of the transformed signal f ^ \mathbf{\hat{f}} f^ are the coordinates of the graph signal in the new space so that the input signal can be represented as f = ∑ i f ^ ( λ i ) u i \mathbf{f}=\sum_{i} \mathbf{\hat{f}}(\lambda_{i}) \mathbf{u}_{i} f=∑if^(λi)ui (linear combination of independent eigenvectors, coefficients are entries in vactor f ^ \mathbf{\hat{f}} f^), which is exactly the inverse graph Fourier transform.
Now the graph convolution of the input signal f \mathbf{f} f with a filter g ∈ R n \mathbf{g} \in R^{n} g∈Rn is defined as
f ∗ G g = F − 1 ( F ( f ) ⊙ F ( g ) ) = U ( U T f ⊙ U T g ) = U ( f ^ ⊙ g ^ ) (13) \begin{aligned} \mathbf{f} *_G \mathbf{g} &=\mathscr{F}^{-1}(\mathscr{F}(\mathbf{f}) \odot \mathscr{F}(\mathbf{g})) \\ &=\mathbf{U}\left(\mathbf{U}^{T} \mathbf{f} \odot \mathbf{U}^{T} \mathbf{g}\right) \\ &=\mathbf{U}\left(\mathbf{\hat f} \odot \mathbf{\hat g}\right) \end{aligned} \tag {13} f∗Gg=F−1(F(f)⊙F(g))=U(UTf⊙UTg)=U(f^⊙g^)(13)
Note that (13) uses formula from (3)(8)(9).
We know from (10) and (11) that
f ^ = ( f ^ ( λ 1 ) f ^ ( λ 2 ) ⋮ f ^ ( λ n ) ) = ( f ^ ( λ 1 ) = ∑ i = 1 n f ( i ) u 1 ( i ) f ^ ( λ 2 ) = ∑ i = 1 n f ( i ) u 2 ( i ) ⋮ f ^ ( λ n ) = ∑ i = 1 n f ( i ) u n ( i ) ) (14) \mathbf{\hat{f}} = \left(\begin{array}{c} \hat{f}\left(\lambda_{1}\right) \\ \hat{f}\left(\lambda_{2}\right) \\ \vdots \\ \hat{f}\left(\lambda_{n}\right) \end{array}\right) = \left(\begin{array}{c} \mathbf{\hat{f}}(\lambda_{1})=\sum_{i=1}^{n} \mathbf{f}(i) u_{1}(i) \\ \mathbf{\hat{f}}(\lambda_{2})=\sum_{i=1}^{n} \mathbf{f}(i) u_{2}(i) \\ \vdots \\ \mathbf{\hat{f}}(\lambda_{n})=\sum_{i=1}^{n} \mathbf{f}(i) u_{n}(i) \end{array}\right) \tag {14} f^=⎝⎜⎜⎜⎛f^(λ1)f^(λ2)⋮f^(λn)⎠⎟⎟⎟⎞=⎝⎜⎜⎜⎛f^(λ1)=∑i=1nf(i)u1(i)f^(λ2)=∑i=1nf(i)u2(i)⋮f^(λn)=∑i=1nf(i)un(i)⎠⎟⎟⎟⎞(14)
Therefore, we could write the element-wise product f ^ ⊙ g ^ \mathbf{\hat f} \odot \mathbf{\hat g} f^⊙g^ as
f ^ ⊙ g ^ = g ^ ⊙ f ^ = g ^ ⊙ U T f = ( g ^ ( λ 1 ) ⋱ g ^ ( λ n ) ) U T f (15) \mathbf{\hat f} \odot \mathbf{\hat g}= \mathbf{\hat g} \odot \mathbf{\hat f}= \mathbf{\hat g} \odot \mathbf{U}^{T} \mathbf{f}= \left(\begin{array}{ccc} \mathbf{\hat g}\left(\lambda_{1}\right) & & \\ & \ddots & \\ & & \mathbf{\hat g} \left(\lambda_{n}\right) \end{array}\right) \mathbf{U}^{T} \mathbf{f} \tag {15} f^⊙g^=g^⊙f^=g^⊙UTf=⎝⎛g^(λ1)⋱g^(λn)⎠⎞UTf(15)
If we denote a filter as g θ ( Λ ) = diag ( U T g ) , \mathbf{g}_{\theta}(\mathbf{\Lambda})=\operatorname{diag}\left(\mathbf{U}^{T} \mathbf{g}\right), gθ(Λ)=diag(UTg), then the spectral graph convolution is simplified as
f ∗ G g = U g θ ( Λ ) U T f (16) \mathbf{f} *_G \mathbf{g} = \mathbf{U g}_{\theta}(\mathbf{\Lambda}) \mathbf{U}^{T} \mathbf{f} \tag {16} f∗Gg=Ugθ(Λ)UTf(16)
Spectral-based ConvGNNs all follow this definition. The key difference lies in the choice of the filter g θ \mathrm{g}_{\theta} gθ. In the rest of the post, I list two designs of filter for making a sense of what Spectral Convolutional Neural Network is.
Spectral-based ConvGNNs
Definition:
- (the number of) Input/output channels: dimensionality of node feature vectors.
Spectral Convolutional Neural Network assumes the filter g θ = Θ i , j ( k ) \mathbf{g}_{\theta}=\Theta_{i, j}^{(k)} gθ=Θi,j(k) is a set of learnable parameters and considers graph signals with multiple channels. The graph convolutional layer of Spectral CNN is defined as
H : , j ( k ) = σ ( ∑ i = 1 f k − 1 U Θ i , j ( k ) U T H : , i ( k − 1 ) ) ( j = 1 , 2 , ⋯ , f k ) (17) \mathbf{H}_{:, j}^{(k)}=\sigma\left(\sum_{i=1}^{f_{k-1}} \mathbf{U} \Theta_{i, j}^{(k)} \mathbf{U}^{T} \mathbf{H}_{:, i}^{(k-1)}\right) \quad\left(j=1,2, \cdots, f_{k}\right) \tag {17} H:,j(k)=σ(i=1∑fk−1UΘi,j(k)UTH:,i(k−1))(j=1,2,⋯,fk)(17)
where k k k is the layer index, H ( k − 1 ) ∈ R n × f k − 1 \mathbf{H}^{(k-1)} \in \mathbf{R}^{n \times f_{k-1}} H(k−1)∈Rn×fk−1 is the input graph signal, H ( 0 ) = X \mathbf{H}^{(0)}=\mathbf{X} H(0)=X (node feature matrix of a graph), f k − 1 f_{k-1} fk−1 is the number of input channels and f k f_{k} fk is the number of output channels, Θ i , j ( k ) \Theta_{i, j}^{(k)} Θi,j(k) is a diagonal matrix filled with learnable parameters.
Due to the eigen-decomposition of the Laplacian matrix, Spectral CNN faces three limitations:
-
Any perturbation to a graph results in a change of eigenbasis.
-
The learned filters are domain dependent, meaning they cannot be applied to a graph with a different structure.
-
Eigen-decomposition requires O ( n 3 ) O\left(n^{3}\right) O(n3) computational complexity ( n n n: the number of nodes).
Naive Design of g θ ( Λ ) \mathbf{g}_{\theta}(\mathbf{\Lambda}) gθ(Λ)
The naive way is to set g ^ ( λ l ) = θ l \mathbf{\hat g}(\lambda_l) = \theta_l g^(λl)=θl, that is,
g θ ( Λ ) = ( θ 1 ⋱ θ n ) (18) g_{\theta}(\mathbf{\Lambda})=\left(\begin{array}{ccc} \theta_{1} & & \\ & \ddots & \\ & & \theta_{n} \end{array}\right) \tag {18} gθ(Λ)=⎝⎛θ1⋱θn⎠⎞(18)
Limitations:
-
In each forward-propagation step, we need to calculate the product of the three matrices The amount of calculation is too large especially for relatively large graphs.
-
Convolution kernel does not have Spatial Localization.
-
The number of θ l \theta_l θl depends on the total number of nodes, which is unacceptable for large graph.
In follow-up works, ChebNet, for example, reduces the computational complexity by making several approximations and simplifications.
Chebyshev Spectral CNN (Recursive formulation for fast filtering)
Polynomial parametrization for localized filters
Limitations mentioned in the last section can be overcome with the use of a polynomial filter, where
g ^ ( λ l ) = ∑ i = 0 K θ l λ l (19) \mathbf{\hat g}(\lambda_l) = \sum_{i=0}^{K} \theta_{l} \lambda^{l} \tag{19} g^(λl)=i=0∑Kθlλl(19)
Written in the matrix format, we have
g θ ( Λ ) = ( ∑ i = 0 K θ i λ 1 i ⋱ ∑ i = 0 K θ i λ n i ) = ∑ i = 0 K θ i Λ i (20) g_{\theta}(\mathbf{\Lambda})=\left(\begin{array}{ccc} \sum_{i=0}^{K} \theta_{i} \lambda_{1}^{i} & & \\ & \ddots & \\ & & \sum_{i=0}^{K} \theta_{i} \lambda_{n}^{i} \end{array}\right)=\sum_{i=0}^{K} \theta_{i} \Lambda^{i} \tag{20} gθ(Λ)=⎝⎛∑i=0Kθiλ1i⋱∑i=0Kθiλni⎠⎞=i=0∑KθiΛi(20)
Then, replacing new defined g θ ( Λ ) g_{\theta}(\mathbf{\Lambda}) gθ(Λ) in (16), we have
f ∗ G g = U ( ∑ i = 0 K θ i Λ i ) U T f = ∑ i = 0 K θ i ( U Λ i U T ) f = ∑ i = 0 K θ i L i f (21) \mathbf{f} *_G \mathbf{g} = U (\sum_{i=0}^{K} \theta_{i} \Lambda^{i}) U^{T} \mathbf{f} =\sum_{i=0}^{K} \theta_{i} (U \Lambda^{i} U^{T}) \mathbf{f} =\sum_{i=0}^{K} \theta_{i} L^{i} \mathbf{f} \tag {21} f∗Gg=U(i=0∑KθiΛi)UTf=i=0∑Kθi(UΛiUT)f=i=0∑KθiLif(21)
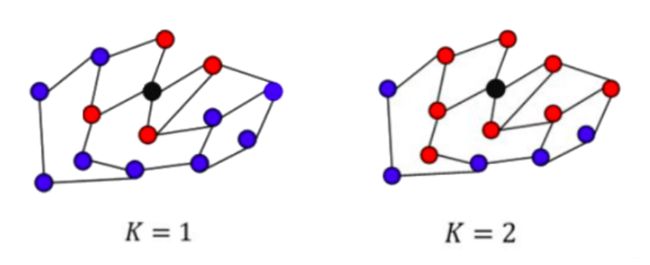
By using polynomial parametrization,
-
Parameters reduce from n n n to K + 1 K+1 K+1.
-
We no longer have to multiply three matrices, but instead we only need to calculate powers of matrix L L L.
-
It can be shown that this filter is localized in space (Spatial Localization). In other words, spectral filters represented by K K Kth-order polynomials of the Laplacian are exactly K-localized (K-localized means the model is aggregating the information from neighbors within K K Kth order, see the figure above).
Chebyshev Spectral CNN (ChebNet)
Chebyshev Spectral CNN (ChebNet) approximates the filter g θ ( Λ ) g_{\theta}(\mathbf{\Lambda}) gθ(Λ) by Chebyshev polynomials of the diagonal matrix of eigenvalues, i.e,
g θ ( Λ ) = ∑ i = 0 K θ i T i ( Λ ~ ) (22) \mathrm{g}_{\theta}(\mathbf{\Lambda})=\sum_{i=0}^{K} \theta_{i} T_{i}(\tilde{\boldsymbol{\Lambda}}) \tag{22} gθ(Λ)=i=0∑KθiTi(Λ~)(22)
where
-
Λ ~ = 2 Λ / λ max − I n \tilde{\boldsymbol{\Lambda}}=2 \mathbf{\Lambda} / \lambda_{\max }- \mathbf{I}_{\mathbf{n}} Λ~=2Λ/λmax−In, a diagonal matrix of scaled eigenvalues that lie in [ − 1 , 1 ] [−1, 1] [−1,1].
-
The Chebyshev polynomials are defined recursively by
T i ( f ) = 2 f T i − 1 ( f ) − T i − 2 ( f ) (23) T_{i}(\mathbf{f})=2 \mathbf{f} T_{i-1}(\mathbf{f})-T_{i-2}(\mathbf{f}) \tag{23} Ti(f)=2fTi−1(f)−Ti−2(f)(23)
with T 0 ( f ) = 1 T_{0}(\mathbf{f})=1 T0(f)=1 and T 1 ( f ) = f T_{1}(\mathbf{f})=\mathbf{f} T1(f)=f.
As a result, the convolution of a graph signal f \mathbf{f} f with the defined filter g θ ( Λ ) \mathrm{g}_{\theta}(\mathbf{\Lambda}) gθ(Λ) is
f ∗ G g θ = U ( ∑ i = 0 K θ i T i ( Λ ~ ) ) U T f (24) \mathbf{f} *_{G} \mathbf{g}_{\theta}=\mathbf{U}\left(\sum_{i=0}^{K} \theta_{i} T_{i}(\tilde{\boldsymbol{\Lambda}})\right) \mathbf{U}^{T} \mathbf{f} \tag{24} f∗Ggθ=U(i=0∑KθiTi(Λ~))UTf(24)
Denote scaled Laplacian L ~ \tilde{\mathbf{L}} L~ as
L ~ = 2 L / λ max − I n (25) \tilde{\mathbf{L}}=2 \mathbf{L} / \lambda_{\max }-\mathbf{I}_{\mathbf{n}} \tag {25} L~=2L/λmax−In(25)
Then by induction on i i i and using (21), the following equation holds:
T i ( L ~ ) = U T i ( Λ ~ ) U T (26) T_{i}(\tilde{\mathbf{L}})=\mathbf{U} T_{i}(\tilde{\boldsymbol{\Lambda}}) \mathbf{U}^{T} \tag {26} Ti(L~)=UTi(Λ~)UT(26)
Then finally ChebNet takes the following form:
f ∗ G g θ = ∑ i = 0 K θ i T i ( L ~ ) f (27) \mathbf{f} *_{G} \mathbf{g}_{\theta}=\sum_{i=0}^{K} \theta_{i} T_{i}(\tilde{\mathbf{L}}) \mathbf{f} \tag {27} f∗Ggθ=i=0∑KθiTi(L~)f(27)
The benefits of ChebNet is similar to those of polynomial parametrization mentioned above.
Comparison between spectral and spatial models
Spectral models have a theoretical foundation in graph signal processing. By designing new graph signal filters, one can build new ConvGNNs. However, spatial models are preferred over spectral models due to efficiency, generality, and flexibility issues.
First, spectral models are less efficient than spatial models. Spectral models either need to perform eigenvector computation or handle the whole graph at the same time. Spatial models are more scalable to large graphs as they directly perform convolutions in the graph domain via information propagation. The computation can be performed in a batch of nodes instead of the whole graph.
Second, spectral models which rely on a graph Fourier basis generalize poorly to new graphs. They assume a fixed graph. Any perturbations to a graph would result in a change of eigenbasis. Spatial-based models, on the other hand, perform graph convolutions locally on each node where weights can be easily shared across different locations and structures.
Third, spectral-based models are limited to operate on undirected graphs. Spatial-based models are more flexible to handle multi-source graph inputs such as edge inputs, directed graphs, signed graphs, and heterogeneous graphs, because these graph inputs can be incorporated into the aggregation function easily.
Reference:
- Introduction to the Fourier Transform: http://www.thefouriertransform.com/#introduction
- Degree Matrix: https://en.wikipedia.org/wiki/Degree_matrix
- Introduction to Graph Signal Processing: https://link.springer.com/chapter/10.1007/978-3-030-03574-7_1
- Convolution Theorem: https://www.sciencedirect.com/topics/engineering/convolution-theorem
- The Convolution Theorem with Application Examples: https://dspillustrations.com/pages/posts/misc/the-convolution-theorem-and-application-examples.html
Paper:
- A Comprehensive Survey on Graph Neural Networks: https://arxiv.org/pdf/1901.00596.pdf
- Spectral Networks and Deep Locally Connected Networks on Graphs https://arxiv.org/pdf/1312.6203.pdf
- Spectral Networks and Deep Locally Connected Networks on Graphs: https://arxiv.org/pdf/1312.6203.pdf
- Convolutional Neural Networks on Graphs with Fast Localized Spectral Filtering: https://arxiv.org/pdf/1606.09375.pdf