Neo4j入门级学习笔记
Neo4j是一个java开发的图数据库,它将结构化数据存储在网络(从数学角度叫做图)上而不是表中。相对于关系数据库来说,图数据库善于处理大量复杂、互连接、低结构化的数据,这些数据变化迅速,需要频繁的查询——在关系数据库中,这些查询会导致大量的表连接,因此会产生性能上的问题。Neo4j重点解决了拥有大量连接的传统RDBMS在查询时出现的性能衰退问题。Neo4j还提供了非常快的图算法、推荐系统和OLAP风格的分析,而这一切在目前的RDBMS系统中都是无法实现的。它提供了广泛使用的REST接口,能够方便地集成到基于JAVA、PHP、.NET和JavaScript的环境里。
目录
1. 背景
2. 亮点
3. 专业名词
3.1 节点
3.2 关系
3.3 属性
3.4 路径
3.5 图&节点&关系
3.6 事务
3.7 遍历器:Traversal
3.8 索引器
4. 使用
4.1 创建节点
4.2 创建关系
4.3 Pattern
4.4 Cypher
4.4.1 操作符
4.4.2 Match
4.5 图算法
4.6 批量操作
4.7 存储过程
5. docker支持
6. 工具使用
6.1 Neoclipse
6.2 Neo4j
6.3 Neo4j-shell
6.4 Neo4j-import
6.5 Neo4j-backup
6.6 Neo4j-arbiter
7. Monitoring
8. 集群
8.1 安装neo4集群
8.2 安装haproxy
9. Q&A
9.1 Session.save注意项
9.2 Spring-data-neo4j
9.3 BoltDriver和HttpDriver差异性
1. 背景
现实世界中的一切事物都处在联系之中,如人际关系、电脑网络、地理数据、分子结构模型等,无一不处在纷繁复杂的联系之中。这种联系形成了一种互相关联的数据,联系才是数据的本质所在。传统的关系型数据库并不能很好地表现数据的联系,而一些NoSQL(Not Only SQL,非关系型数据库)数据库又不能表现数据之间的联系。同样是NoSQL的Neo4j图数据库是以图的结构形式来存储数据的,它所存储的就是联系的数据,是关联数据本身。
关联数据中的联系本来就很复杂,若要在关系型数据库中使用结构化形式来表现这种联系,则一般不能直接表示,处理起来既烦琐又费事,并且随着数据的不断增长,其访问性能将日趋下降。无数的开发人员和数据库管理人员都或多或少地使用过关系型数据库,在其应用的规模化进展过程中,对于数据库的性能优化往往捉襟见肘、陷入窘境。Neo4j没有模式结构的定义,也不需要这些定义,它使用非结构化的方式来存储关联数据,所以能够直接表现数据的关联特性。
2. 亮点
- 完整的ACID支持:事务性
- 高可用性:集群HA方案
- 高可用,轻易扩展到上亿级别的节点和关系,Neo4j是一个原生的图数据库引擎,它存储了原生的图数据,因此,可以使用图结构的自然伸展特性来设计免索引邻近节点遍历的查询算法,即图的遍历算法设计。图的遍历是图数据结构所具有的独特算法,即从一个节点开始,根据其连接的关系,可以快速和方便地找出它的邻近节点。这种查找数据的方法并不受数据量的大小所影响,因为邻近查询始终查找的是有限的局部数据,不会对整个数据库进行搜索。所以,Neo4j具有非常高效的查询性能,相比于RDBMS可以提高数倍乃至数十倍的查询速度。而且查询速度不会因数据量的增长而下降,即数据库可以经久耐用,并且始终保持最初的活力。不像RDBMS那样,因为不可避免地使用了一些范式设计,所以在查询时如果需要表示一些复杂的关系,势必会构造很多连接,从而形成很多复杂的运算。并且在查询中更加可怕的是还会涉及大量数据,这些数据大多数与结果毫无关系,有的可能仅仅是通过ID查找它的名称而已,所以随着数据量的增长,即使查询一小部分数据,查询也会变得越来越慢,性能日趋下降,以至于让人无法忍受。
- 通过遍历工具高速检索数据:cypher
3. 专业名词
3.1 节点
节点经常被用于表示一些_实体_
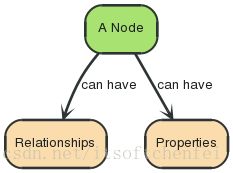
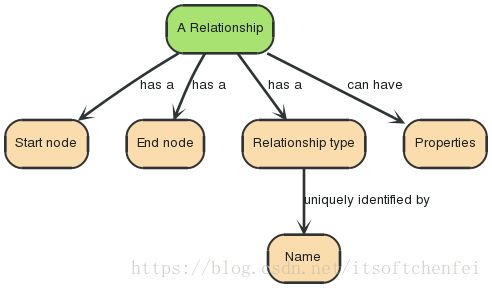
3.2 关系
- 一个关系连接两个节点,必须有一个开始节点和结束节点
- 对于一个节点来说,与他节点的关联关系只有输入/输出两个方向
- 关系在任一方向都会被遍历访问,这意味着我们并不需要在不同方向都新增关系,而关系总是会有一个方向,所以当这个方向对你的应用没有意义时你可以忽略方向
注意:一个节点可以有一个关系是指向自己的,关键字 type 在这可能会被误解(简单的理解为一个标签而已)
例如:
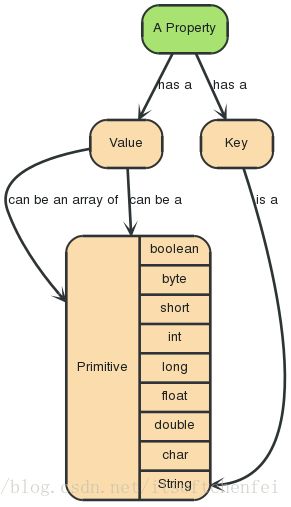
3.3 属性
节点和关系都可以设置自己的属性。
属性是由Key-Value键值对组成,键名是字符串。属性值是要么是原始值,要么是原始值类型的一个数组
3.4 路径
路径由至少一个节点,通过各种关系连接组成,经常是作为一个查询或者遍历的结果
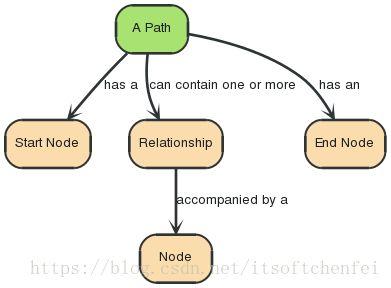
3.5 图&节点&关系
“一张图 – 数据记录在 → 节点 → 包括的 → 属性里面”
“节点 — 被组织 → 关系 — 可以有 → 属性”
3.6 事务
参与neo4j-developer-manual-3.0-java.pdf节点Chapter 5
- All database operations that access the graph, indexes, or the schema must be performed in a transaction
- The default isolation level is READ_COMMITTED
- 数据检索遍历不受其他事务修改
- 不可重复读取可能发生(只有获取并保持了写锁,直到事务结束为止)
- 锁在节点和关系级别上获得
- 死锁检测是内置到核心事务管理
3.7 遍历器:Traversal
一次Traversal, 你可以理解为是你通过一种算法,从一些开始节点开始查询与其关联的节点,
Neo4j提供了遍历的API,可以让你指定遍历规则。最简单的设置就是设置遍历是宽度优先还是深度优先。
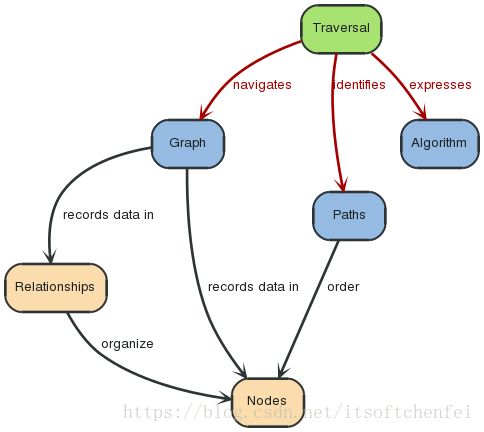
ReturnType:
• node
• relationship
• path: contains full representations of start and end node, the rest are URIs.
• fullpath: contains full representations of all nodes and relationships.
Return_filter:
• all
• all_but_start_node
Order:
•breadth_first
•depth_first
Relationships:
•all
•in
•out
Uniqueness:
• node_global
• none
• relationship_global
• node_path
• relationship_path
Max_depth
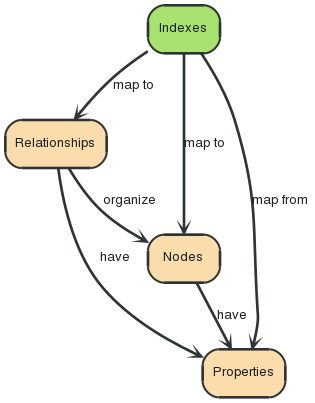
3.8 索引器
“一个索引 — 映射到 → 属性 — 属于 → 节点或者关系”
Legacy indexing:传统索引
在Neo4j 2.0版本之前,Legacy index被称作indexes。这个索引是通过外部图存储在外的Lucene实现,允许“节点”和“联系”以key:value键值对的方法被检索。从Neo4j 提供的REST接口来看,被称作“index”的变量通常是指Legacy indexes。
Legacy index能够提供全文本检索的能力。这个功能并没有在schema index中被提供,这也是Neo4j 2.0* 版本保留legacy indexes的原因之一
注意:使用legacy index查询往往需要一个开始“节点”;并且它并没有能力提高查询的速度。
Schema Indexes
Neo4j 2.0版本在“节点标签”章节介绍schema。shcema indexes以及约束的最基本应用在于带属性的“标签”在路径匹配。与legacy index不同之处在于,schema index能够提高查询速度。
注意:仅仅schema index有“标签”这个概念;legacy index完全没有“标签”的概念。
schema index仅仅对节点是有效而legacy index允许“节点”和“关系”都被索引。“关系”索引的使用场景是很少的,并且通常都可以通过引入额外的节点解决问题。
选择哪一个?
如果你正在使用Neo4j 2.0或者更高版本并且不需要支持2.0版本之前legacy index的代码,那么请只使用schema index同时避免legacy index。
相反,如果你被卡住的Neo4j的早期版本,并且无法升级,无论如何你都只有一种索引可以选择(legacy index)
如果你需要全文检索的索引,不管是什么版本,有都将使用legacy index。
更复杂的场景在于从一中索引调用到另外一中索引。这种情况下,请确保你已经对两个索引的不同有足够的认识并且尝试过,在可能的情况下,只使用schema index或者legacy index而不是两者都使用。混合使用两者经常导致更多的困惑。
唯一索引
Neo4j2.0新增的特性,配合唯一约束使用
4. 使用
4.1 创建节点
语法:
• 通过CREATE创建一个节点
• () 代表一个节点
• ee:员工 标示符'ee',标签label是 '员工'
• {} 包含了属性
CREATE (ee:员工 { 姓名: "张勇", 来自: "中国" , 年龄 : 99 })
如果想返回创建的数据,需要指定标示符
CREATE (ee:员工 { 姓名: "张勇", 来自: "中国" , 年龄 : 99 })return ee;
创建多个节点数据,多个元素间用逗号或者用create分开
//示例演示:
CREATE (p1:Person {name:'胡兴炯', born:1991, interest:'mac,ios,旅游', goodat:'java,swift,objectiveC'})
CREATE (p2:Person {name:'张勇', born:1990, interest:'android', goodat:'java,android'})
CREATE (p3:Person {name:'成文龙', born:1990, interest:'linux,hadoop', goodat:'linux,java,android'})
CREATE (p4:Person {name:'王昕', born:1978, interest:'wpf,noSQL,旅游', goodat:'java,c#'})
CREATE (p5:Person {name:'周开琪', born:1977 , interest:'管理', goodat:'管理,'})
CREATE (p6:Person {name:'徐锦亮', born:1985, interest:'前端', goodat:'前端,html5'})
CREATE (p8:Person {name:'徐辉霞', born:1990, interest:'管理,旅游', goodat:'管理,采购'})
CREATE (p9:Person {name:'黄廷鹏', born:1992, interest:'OA', goodat:'java'})
CREATE (p10:Person {name:'史乐乐', born:1991, interest:'OA,旅游', goodat:'管理'})
CREATE (p1)-[:认识]->(p2)
CREATE (p1)-[:认识]->(p3)
CREATE (p1)-[:认识]->(p4)
CREATE (p1)-[:认识]->(p5)
CREATE (p1)-[:认识]->(p9)
CREATE (p2)-[:认识]->(p1)
CREATE (p2)-[:认识]->(p3)
CREATE (p2)-[:认识]->(p4)
CREATE (p2)-[:认识]->(p5)
CREATE (p2)-[:认识]->(p9)
CREATE (p3)-[:认识]->(p1)
CREATE (p3)-[:认识]->(p2)
CREATE (p3)-[:认识]->(p4)
CREATE (p3)-[:认识]->(p5)
CREATE (p3)-[:认识]->(p9)
CREATE (p4)-[:认识]->(p1)
CREATE (p4)-[:认识]->(p2)
CREATE (p4)-[:认识]->(p3)
CREATE (p4)-[:认识]->(p5)
CREATE (p4)-[:认识]->(p9)
CREATE (p5)-[:认识]->(p1)
CREATE (p5)-[:认识]->(p2)
CREATE (p5)-[:认识]->(p3)
CREATE (p5)-[:认识]->(p4)
CREATE (p5)-[:认识]->(p6)
CREATE (p5)-[:认识]->(p8)
CREATE (p5)-[:管理]->(p1)
CREATE (p5)-[:管理]->(p2)
CREATE (p5)-[:管理]->(p3)
CREATE (p5)-[:管理]->(p4)
CREATE (p5)-[:管理]->(p6)
CREATE (p6)-[:认识]->(p5)
CREATE (p6)-[:认识]->(p4)
CREATE (p6)-[:夫妻]->(p8)
CREATE (p9)-[:认识]->(p1)
CREATE (p9)-[:认识]->(p2)
CREATE (p9)-[:认识]->(p3)
CREATE (p9)-[:认识]->(p10)
CREATE (p9)-[:单相思]->(p10)
CREATE (p10)-[:认识]->(p9)
4.2 创建关系
语法:
-- 表示一个无指向的关系
--> 表示一个有指向的关系
[] 能够添加标示符,属性,类型等信息
-[role]->
-[:ACTED_IN]->
-[role:ACTED_IN]->
-[role:ACTED_IN {roles: ["Neo"]}]->
如:
create (a:Person {name:"jiaj",born:2003})-[r:ACTED_IN {roles:["student"]}]->(m:School {name:"CDLG",address:"chengdu"})
create (d:Person {name:"weiw",born:2001})-[:DIRECTED]->(m)
return a,d,r,m;
4.3 Pattern
节点和关系语法的合并就表示模式
4.4 Cypher
这个查询语言包含以下几个明显的部分:
Ø START:在图中的开始点,通过元素的ID或索引查找获得。
Ø MATCH:图形的匹配模式,束缚于开始点。
Ø WHERE:过滤条件。
Ø RETURN:返回所需要的。
4.4.1 操作符
Cypher 中的操作符有三个不同种类:数学,相等和关系。
数学操作符有+,-,*,/和%。当然只有+对字符有作用。
等于操作符有=,<>,<,>,<=,>=。
因为Neo4j 是一个模式少的图形数据库,Cypher有两个特殊的操作符?和!。
有些是用在属性上,有些事用于处理缺少值。对于一个不存在的属性做比较会导致错误。为
替代与其他什么做比较时总是检查属性是否存在,在缺失属性时问号将使得比较总是返回
true,感叹号使得比较总是返回false。
WHEREn.prop? = "foo"
4.4.2 Match
我们想连接新的数据到已经存在的结构
$ match (m:School) return m;
$ match (p:Person {name:"weiw"}) return p;
$ match (p:Person {name:"jiaj"})-[r:ACTED_IN]->(m:School) return m.name,r.roles;
4.5 图算法
Algorithm:
• shortestPath(最短路径)
• allSimplePaths
• allPaths
• dijkstra (optionally with cost_property and default_cost parameters)
max_depth:Default is 1
下面是最短路径算法的简单例子:
import org.neo4j.graphalgo.PathFinder;
import org.neo4j.graphalgo.GraphAlgoFactory;
public Iterable findShortestPath(Node node1, Node node2) {
PathFinder finder = GraphAlgoFactory.shortestPath(
Traversal.expanderForTypes(RelTypes.KNOWS, Direction.OUTGOING), 5);
Iterable paths = finder.findAllPaths(node1, node2);
return paths;
}
public void printShortestPaths() {
Node node1 = nodeIndex.get(PRIMARY_KEY, "Thomas Anderson").getSingle();
Node node2 = nodeIndex.get(PRIMARY_KEY, "Agent Smith").getSingle();
for(Path shortestPath: findShortestPath(node1, node2)) {
System.out.println(shortestPath.toString());
}
}
4.6 批量操作
参考neo4j-rest-documentation-3.0.pdf节点Batch operations
4.7 存储过程
参与neo4j-developer-manual-3.0-java.pdf节点Chapter 24. Built-in procedures
| Procedure name |
Command to invoke procedure |
What it does |
| ListLabels |
CALL db.labels() |
List all labels in the database. |
| ListRelationshipTypes |
CALL db.relationshipTypes() |
List all relationship types in the database. |
| ListPropertyKeys |
CALL db.propertyKeys() |
List all property keys in the database. |
| ListIndexes |
CALL db.indexes() |
List all indexes in the database. |
| ListConstraints |
CALL db.constraints() |
List all constraints in the database. |
| ListProcedures |
CALL dbms.procedures() |
List all procedures in the DBMS. |
| ListComponents |
CALL dbms.components() |
List DBMS components and their versions. |
| QueryJmx |
CALL dbms.queryJmx(query) |
Query JMX management data by domain and name. For instance, "org.neo4j:*". |
| AlterUserPassword |
CALL dbms.changePassword(query) |
Change the user password. |
5. docker支持
https://hub.docker.com/r/library/neo4j/
$docker run --publish=7474:7474 --volume=$HOME/neo4j/data:/data neo4j:3.0.4-enterprise
$docker ps –a
$docker start e26bb
$ docker exec -it e26bb /bin/bash 找到conf文件
$ sudo docker cp e26bb:/var/lib/neo4j/conf/neo4j.conf /root/xfboy 拷贝到本地
docker run -v /home/xfboy/neo4j1.conf:/var/lib/neo4j/conf/neo4j.conf --volume=$HOME/neo4j/data1:/data neo4j:3.0.4-enterprise
6. 工具使用
6.1 Neoclipse
Neoclipse是一个具有将neo4j图形数据库可视化和修改neo4j图形数据库(包括节点,关系和属性)等功能的工具。
下载地址:https://github.com/neo4j-contrib/neoclipse
http://blog.csdn.net/cfeibiao/article/details/6842941
6.2 Neo4j
Neo4j服务器控制和管理
语法:neo4j
console:将服务器作为一个前台进程启动运行,停止服务器请使用 `CTRL-C`。
start:以后台服务形式启动服务器。
stop:停止一个后台运行的服务器。
restart:重启服务器
status:返回当前运行的服务器状态。
install:安装服务器作为一个平台相关的系统服务。
remove:卸载系统服务。
info:显示配置信息,比如当前的NEO4J_HOME和CLASSPATH
6.3 Neo4j-shell
浏览和维护一个图数据库的命令行工具
语法:neo4j-shell [远程选项/本地选项]
>schema:列出所有标签索引与约束
>index –indexes:列出索引传统索引
远程选项
-port PORT:连接到主机的端口(默认:1337)。
-host HOST:连接到的主机的域名或者IP地址( 默认:localhost)。
-name NAME:RMI名称, 比如:rmi://
-readonly:以只读模式访问数据库
本地选项
-path PATH:数据库的目录。 如果在这个目录没有数据库存在,则会自动创建一个新的数据库。
-pid PID:连接到的进程编号。
-readonly:以只读模式访问数据库。
-c COMMAND:在命令行执行命令,执行完成后命令行会退出。
-config CONFIG:Neo4j配置文件路径。
示例:
neo4j-shell -host 192.168.1.234 -port 1337 -name shell
neo4j-shell -path /path/to/db -config /path/to/neo4j.config
6.4 Neo4j-import
数据导入工具
参考:neo4j-operations-manual-3.0.pdf的节点B.3. Use the Import tool
6.5 Neo4j-backup
Neo4j备份工具
neo4j-backup {-full|-incremental} -from 来源数据库地址 -to 目标目录名称 [-cluster 集群名称]
-full
拷贝完整的数据库到一个目录。
-incremental
差量备份,只拷贝自动上次完整备份以后的变化部分到一个存在的备份存储
如:
neo4j-backup -full -from single://192.168.1.34 -to /mnt/backup/neo4j-backup
neo4j-backup -incremental -from single://freja -to /mnt/backup/neo4j-backup
6.6 Neo4j-arbiter
一个簇集想要拥有容错性,通常需要三个节点。当主节点出现故障时,通过电子投票的方式可能无法选出新的主节点,因为可选的实例数量是偶数。这正是仲裁器起作用的地方。仲裁器的作用像是用于选举功能的正常实例,但它并不拥有数据库引擎。
7. Monitoring
- Export metrics to csv files
- Send metrics to Graphite or any monitoring tool based on the Graphite protocol(企业版默认已集成到可视化界面)
8. 集群
下载Neo4J 企业版(社区版不支持集群)
Neo4j HA主要提供以下两个功能:
- 容错数据库架构 保存多个数据副本,即使硬件故障,也能保证可读写。
- 水平方向扩展以读为主架构 读操作负载均衡。
- 内置状态机,自动选主
Neo4j HA模式总有单个master,零个或多个slave。与其他ms复制架构,Neo4j HA的slave可以处理写操作,而无需重定向写入到master。
注:Neo4j企业版现在拥有自己的基于Paxos协议的簇集解决方案,那替换了之前基于Zookeeper的方案。这样就不再需要单独的Zookeeper簇集
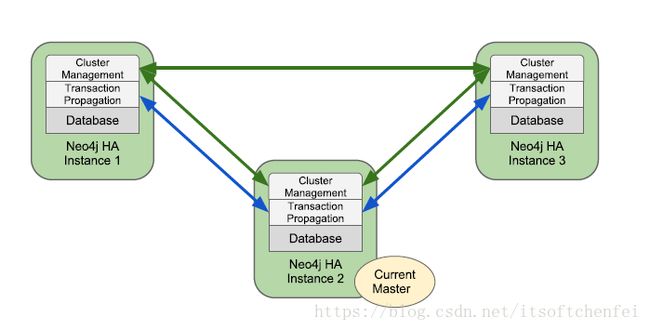
8.1 安装neo4集群
$cp -R neo4j-enterprise-3.0.5 neo4j-01
$cp -R neo4j-enterprise-3.0.5 neo4j-02
$cp -R neo4j-enterprise-3.0.5 neo4j-03
修改neo4j.conf
dbms.backup.address=0.0.0.0:6362
dbms.connector.bolt.address=0.0.0.0:7687
dbms.connector.http.address=0.0.0.0:7474
dbms.connector.https.address=localhost:7473
dbms.mode=HA
ha.server_id=1
ha.initial_hosts=127.0.0.1:5001,127.0.0.1:5002,127.0.0.1:5003
ha.host.coordination=127.0.0.1:5001
ha.host.data=127.0.0.1:6001
$neo4j-01/bin/neo4j start console
$neo4j-02/bin/neo4j start console
$neo4j-03/bin/neo4j start console
HA HTTP endpoint responses:
| Endpoint |
InstanceState |
ReturnedCode |
Bodytext |
| /db/manage/server/ha/master |
Master |
200 |
true |
| Slave |
404 |
false |
|
| Unknown |
404 |
UNKNOWN |
|
| /db/manage/server/ha/slave |
Master |
404 |
false |
| Slave |
200 |
true |
|
| Unknown |
404 |
UNKNOWN |
|
| /db/manage/server/ha/available |
Master |
200 |
master |
| Slave |
200 |
slave |
|
| Unknown |
404 |
UNKNOWN |
8.2 安装haproxy
1.在线安装:
$sudo yum -y install haproxy
$sudo yum -y remove haproxy
启动:/etc/init.d/haproxy start
停止:/etc/init.d/haproxy stop
重启:/etc/init.d/haproxy restart
状态:/etc/init.d/haproxy status
配置文件路径:/etc/haproxy/haproxy.cfg
2.源码安装:
$ sudo yum install -y gcc 如果gcc未安装的话
$tar zxf haproxy-1.6.3.tar.gz
$cd haproxy-1.6.3
$sudo make install
$vi haproxy.cfg #新增配置文件
global
maxconn 5120
uid 99
gid 99
daemon
pidfile /home/xfboy/haproxy.pid
log 127.0.0.1 local0 err
listen admin
bind *:1080
mode http
stats refresh 30s
stats uri /stats
stats realm Haproxy Manager
stats auth admin:admin
stats hide-version
stats enable
frontend http-in
bind *:88
mode http
default_backend neo4j-slaves
backend neo4j-slaves
server db01 192.168.3.106:7474 maxconn 32 check
server db02 192.168.3.106:7475 maxconn 32 check
server db03 192.168.3.106:7476 maxconn 32 check
$sudo haproxy -f haproxy.cfg 启动
访问: http://192.168.3.106:1080/stats
9. Q&A
9.1 Session.save注意项
调用api的save方法会执行更新或插入操作,需设置深度,参考ogm文档Default depth for persisting 部分。
9.2 Spring-data-neo4j
集成spring环境,更多参考官方
9.3 BoltDriver和HttpDriver差异性?
官网资料未介绍两者区别,经过查看源码得知 ,BoltDriver是tcp socket通讯当然性能更佳。