【语义分割】语义分割评估指标mIOU
语义分割评估指标计算公式可参考:基于深度学习的图像语义分割技术概述之5.1度量标准
mIOU定义
Mean Intersection over Union(MIoU,均交并比):为语义分割的标准度量。其计算两个集合的交并比,在语义分割的问题中,这两个集合为真实值(ground truth)和预测值(predicted segmentation)。计算公式如下:
i表示真实值,j表示预测值 , p i j p_{ij} pij 表示将i预测为j 。
M I o U = 1 k + 1 ∑ i = 0 k p i i ∑ j = 0 k p i j + ∑ j = 0 k p j i − p i i M I o U=\frac{1}{k+1} \sum_{i=0}^{k} \frac{p_{i i}}{\sum_{j=0}^{k} p_{i j}+\sum_{j=0}^{k} p_{j i}-p_{i i}} MIoU=k+11i=0∑k∑j=0kpij+∑j=0kpji−piipii
等价于:
M I o U = 1 k + 1 ∑ i = 0 k T P F N + F P + T P M I o U=\frac{1}{k+1} \sum_{i=0}^{k} \frac{TP}{ {FN}+{FP}+{TP}} MIoU=k+11i=0∑kFN+FP+TPTP
先求每个类别的交并比,再平均
直观理解
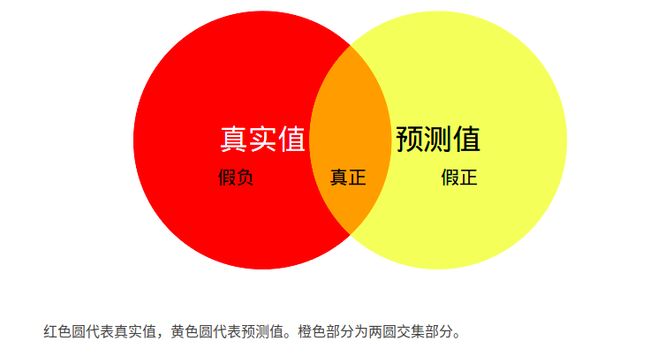
MIoU:计算两圆交集(橙色部分)与两圆并集(红色+橙色+黄色)之间的比例,理想情况下两圆重合,比例为1。
mIOU实现
步骤一:先求混淆矩阵

步骤二:再求mIOU
混淆矩阵的每一行再加上每一列,最后减去对角线上的值
import numpy as np
class IOUMetric:
"""
Class to calculate mean-iou using fast_hist method
"""
def __init__(self, num_classes):
self.num_classes = num_classes
self.hist = np.zeros((num_classes, num_classes))
def _fast_hist(self, label_pred, label_true):
# 找出标签中需要计算的类别,去掉了背景
mask = (label_true >= 0) & (label_true < self.num_classes)
# # np.bincount计算了从0到n**2-1这n**2个数中每个数出现的次数,返回值形状(n, n)
hist = np.bincount(
self.num_classes * label_true[mask].astype(int) +
label_pred[mask], minlength=self.num_classes ** 2).reshape(self.num_classes, self.num_classes)
return hist
# 输入:预测值和真实值
# 语义分割的任务是为每个像素点分配一个label
def ev aluate(self, predictions, gts):
for lp, lt in zip(predictions, gts):
assert len(lp.flatten()) == len(lt.flatten())
self.hist += self._fast_hist(lp.flatten(), lt.flatten())
# miou
iou = np.diag(self.hist) / (self.hist.sum(axis=1) + self.hist.sum(axis=0) - np.diag(self.hist))
miou = np.nanmean(iou)
# -----------------其他指标------------------------------
# mean acc
acc = np.diag(self.hist).sum() / self.hist.sum()
acc_cls = np.nanmean(np.diag(self.hist) / self.hist.sum(axis=1))
freq = self.hist.sum(axis=1) / self.hist.sum()
fwavacc = (freq[freq > 0] * iou[freq > 0]).sum()
return acc, acc_cls, iou, miou, fwavacc
参考:mIoU源码解析