map-reduce实现(map端join, reduce端join)
- map-reduce实现hive的join全外连接查询 (大表 +小表 )
假设有订单表orders, 用户表customers, 存在大表+小表的关系, 则可以使用sql的优化: 使用map端join
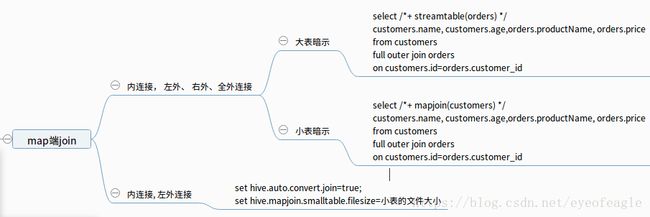
现在的问题是, 如何使用map-reduce 自己实现: map端的 full outer join ? reduce端的full outer join ?
part1: map端全外连接 (map-reduce实现)
思路: 小表在map阶段可以先加载到内存

public class App1 {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//job
Configuration conf = new Configuration();
conf.set("fs.defaultFS","file:///");
Job job = Job.getInstance();
job.setJarByClass(App1.class);
job.setJobName("mapjoin");
//map,red
job.setMapperClass(Map1.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
//存放:customers.txt, orders.txt
FileInputFormat.addInputPath(job,new Path("/home/hadoop/txt/mrjoin"));
FileSystem fs = FileSystem.get(conf);
Path path = new Path("mapjoin");
if (fs.exists(path)) {
fs.delete(path, true);
}
FileOutputFormat.setOutputPath(job, path);
//启动
job.waitForCompletion(true);
}
}
/**orders.txt
* ------------------
* 1,phone,7000,1
* 2,book,34, 2
* 3,shooe,300, 3
* 4,cup,90, 5
*
* customers.txt
* ----------------
* 1,lisi, 23
* 2,zs, 54
* 3,wang, 38
* 4,jiang, 25
*/
public class Map1 extends Mapper {
Map map=new HashMap<>();
static int count=0;
@Override
protected void setup(Context context) throws IOException, InterruptedException {
count++;
if (count >1)return;
//加载 小文件件
BufferedInputStream bfin=new BufferedInputStream(new FileInputStream("/home/hadoop/txt/mrjoin/customers.txt"));
BufferedReader br= new BufferedReader(new InputStreamReader(bfin));
String res=null;
while((res=br.readLine())!=null){
String[] splits = res.split(",");
String id=splits[0];
map.put(Integer.parseInt(id),res );
}
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//排除customers表
InputSplit split = context.getInputSplit();
FileSplit filesplit=(FileSplit)split;
if ( filesplit.getPath().getName().contains("orders")){
//取出: 订单数据
String[] mesg = value.toString().split(",");
int userId=Integer.parseInt(mesg[3]);
String userInfo=map.get(userId);
context.write(new Text(value.toString()+"--->"+ userInfo ), NullWritable.get() );
//删除匹配完的: 用户信息
map.remove(userId);
}
}
@Override
protected void cleanup(Context context) throws IOException, InterruptedException {
if (count >1)return;
//取出脏的 用户数据
Set keys = map.keySet();
for (Integer key : keys) {
String val=map.get(key);
context.write(new Text("null,--->"+val), NullWritable.get());
}
map.clear();
map=null;
}
} part2: reduce端全外连接(map-reduce实现)

第一部分: map-reduce-app
【app类】
public class App2 {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//job
Configuration conf = new Configuration();
conf.set("fs.defaultFS","file:///");
Job job = Job.getInstance();
job.setJarByClass(App2.class);
job.setJobName("mapjoin");
//分区,分组 reducer个数
job.setPartitionerClass(Partioner1.class);
job.setGroupingComparatorClass(GroupingComparator.class);
job.setNumReduceTasks(3);
//map,red
job.setMapperClass(Map2.class);
job.setReducerClass(Red2.class);
job.setOutputKeyClass(CompareKey.class);
job.setOutputValueClass(NullWritable.class);
//输入输出
FileInputFormat.addInputPath(job,new Path("/home/hadoop/txt/mrjoin"));
FileSystem fs = FileSystem.get(conf);
Path path = new Path("mapjoin2");
if (fs.exists(path)) {
fs.delete(path, true);
}
FileOutputFormat.setOutputPath(job, path);
//启动
job.waitForCompletion(true);
}
}
【map类】
public class Map2 extends Mapper {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//排除customers表
InputSplit split = context.getInputSplit();
FileSplit filesplit=(FileSplit)split;
String fileName = filesplit.getPath().getName();
if (fileName .contains("orders")){
//取出: 订单数据
String[] mesg = value.toString().split(",");
int userId=Integer.parseInt(mesg[3]);
int orderId=Integer.parseInt(mesg[0]);
/**
* orders.txt
* * ------------------
* * 1,phone,7000,1
* * 2,book,34, 2
* * 3,shooe,300, 3
* * 4,cup,90, 5
* *
*/
CompareKey compkey = new CompareKey();
compkey.setFlag(2);
compkey.setUserId(userId);
compkey.setOrderId(orderId);
compkey.setInfo(value.toString());
context.write(compkey, NullWritable.get() );
}else {
//取出: 用户数据
String[] mesg = value.toString().split(",");
int userId=Integer.parseInt(mesg[0]);
/**
* customers.txt
* * ----------------
* * 1,lisi, 23
* * 2,zs, 54
* * 3,wang, 38
* * 4,jiang, 25
* *
*/
CompareKey compkey = new CompareKey();
compkey.setFlag(1);
compkey.setUserId(userId);
compkey.setInfo(value.toString());
context.write(compkey, NullWritable.get() );
}
}
}
【reduce类】
public class Red2 extends Reducer {
@Override
protected void reduce(CompareKey key, Iterable values, Context context) throws IOException, InterruptedException {
/**
* 取出: order---customer数据, 拼接字符串
*/
String userInfo=null;
Iterator it = values.iterator();
StringBuilder sb = new StringBuilder();
it.next();
//第一条数据: user数据
if (key.getFlag()==1){
userInfo=key.getInfo();
//剩余数据
if (it.hasNext()){
while (it.hasNext()) {
it.next();
//order数据
sb.append(key.getInfo()).append(", ");
System.out.print(sb.toString());
}
}else {
sb.append("null");
}
}else {//第一条数据: order
sb.append(key.getInfo()).append(", ");
//剩余数据
while (it.hasNext()) {
it.next();
//order数据
sb.append(key.getInfo()).append(", ");
System.out.print(sb.toString());
}
}
context.write(new Text(userInfo+" --->"+ sb.toString()), NullWritable.get());
System.out.println(userInfo+ ", orders-->"+sb.toString()+"===============");
}
}
第二部分: 自定义(组合键-排序,分区函数, 分组比较)
【组合键】
public class CompareKey implements WritableComparable {
//属性
private int userId;
private int orderId;
int flag=0;
private String info;
@Override
public int compareTo(CompareKey o) {
int ouserId = o.getUserId();
int oorderId = o.getOrderId();
int oflag = o.getFlag();
//先用户信息--------->订单信息
/**
* user-->order
* order-->user
*
* order--->order
*/
if (this.flag ==1 | oflag==1){
return orderId-oorderId;
}
if (this.flag==2 && oflag==2){
return userId-ouserId;
}
return 0;
}
@Override
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeInt(userId);
dataOutput.writeInt(orderId);
dataOutput.writeInt(flag);
dataOutput.writeUTF(info);
}
@Override
public void readFields(DataInput dataInput) throws IOException {
this.userId=dataInput.readInt();
this.orderId=dataInput.readInt();
this.flag=dataInput.readInt();
this.info=dataInput.readUTF();
}
//get, set,toString()...
} 【map端: 分区函数】
public class Partioner1 extends Partitioner {
@Override
public int getPartition(CompareKey compareKey, NullWritable nullWritable, int numPartitions) {
return compareKey.getUserId() % numPartitions;
}
}
【reduce端: 分组比较】
public class GroupingComparator extends WritableComparator {
//由父类创建: 组合键对象,防止null空指针
public GroupingComparator() {
super(CompareKey.class, true);
}
@Override
public int compare(WritableComparable a, WritableComparable b) {
CompareKey a1= (CompareKey) a;
CompareKey b1= (CompareKey) b;
return a1.getUserId()-b1.getUserId();
}
}
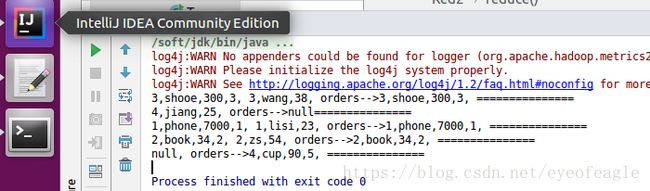
日志打印结果如下