RDD Join 性能调优
阅读本篇博文时,请先理解RDD的描述及作业调度:[《深入理解Spark 2.1 Core (一):RDD的原理与源码分析 》](http://blog.csdn.net/u011239443/article/details/53894611#t16)
Join数据是我们在Spark操作中的很重要的一部分。Spark Core 和Spark SQL的基本类型都支持join操作。虽然join很常用而且功能很强大,但是我们使用它的时候,我们不得不考虑网络传输和所处理的数据集过大的问题。在Spark Core中,DAG优化器不像SQL优化器,它不能够重命令或者下压过滤。所以,Spark操作顺序对于Spark Core显得尤为重要。
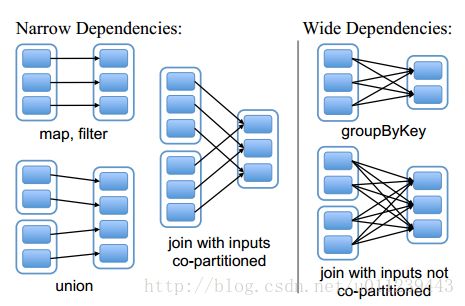
这篇博文,我们将介绍RDD类型的join操作。通常来说,join是一中非常昂贵的操作。对于每个child RDD 的partition,它从各个parent RDD 的 各个 partition中,获取到与该child RDD partition上的key相对应的所有值。
假设有两个parent RDD,它们都没有已知的partitioner(可以理解为该RDD到其child RDD 重分区函数),那么它们就需要shuffle,使得它们共享同一个partitioner,并且有着相同key的数据会在同一个partition里面。如上图“join with inputs not co-partitioned”。
若parent RDD有已知的partitioner(若已知的partitioner相同,两个RDD会协同,那么就能避免网络传输,两个parent RDD 的相同partition会在同一个节点上),那么可能如上图的“join with inputs co-partitioned”,只能产生窄依赖。
和大多数的K/V操作一样,随着key的数量的增加和记录之间的距离的增加(需要寻找其所在的partition),join的花费会越来越高。
选择join的类型
默认情况下,Spark只会对两个RDD的key的值进行join。在有多个相同key值的情况下,会生成所有的K/V对。所以,标准join的最好的情况是,两个RDD有相同的key集合,而且该key集合中的key都是互斥的。若有重复的key,数据量会急剧的扩大以至于导致性能问题。若有个key只在一个RDD中出现了,那么你将失去那行数据。所以,有以下几条建议:
- 若两个RDD都有有重复的key,join操作会使得数据量会急剧的扩大。所有,最好先使用distinct或者combineByKey操作来减少key空间或者用cogroup来处理重复的key,而不是产生所有的交叉结果。在combine时,进行机智的分区,可以避免第二次shuffle。
- 如果只在一个RDD出现,那你将在无意中丢失你的数据。所以使用外连接会更加安全,这样你就能确保左边的RDD或者右边的RDD的数据完整性,在join之后再过滤数据。
- 如果我们容易得到RDD的可以的有用的子集合,那么我们可以先用filter或者reduce,如何在再用join。
总之,join通常是你在使用Spark时最昂贵的操作,需要在join之前应尽可能的先缩小你的数据。
假设,你有一个RDD存着(熊猫id,分数),另外一个RDD存着(熊猫id,邮箱地址)。若你想给每只可爱的熊猫的邮箱发送她所得的最高的分数,你可以将RDD根据id进行join,然后计算最高的分数,如下:
def joinScoresWithAddress1( scoreRDD : RDD[(Long, Double)],
addressRDD : RDD[(Long, String )]) : RDD[(Long, (Double, String))]= {
val joinedRDD = scoreRDD.join(addressRDD)
joinedRDD.reduceByKey( (x, y) => if(x._1 > y._1) x else y )
}然而,这可能不会比先减少分数数据的方案快。先计算最高的分数,那么每个熊猫的分数数据就只有一行,接下来再join地址数据:
def joinScoresWithAddress2( scoreRDD : RDD[(Long, Double)],
addressRDD : RDD[(Long, String )]) : RDD[(Long, (Double, String))]= {
val bestScoreData = scoreRDD.reduceByKey((x, y) => if(x > y) x else y)
bestScoreData.join(addressRDD)
}若每个熊猫有1000个不同的分数,那么这种做法的shuffle量就比上一种的小了1000倍。
如果你想要左外连接,保留分数数据中地址数据所没有的熊猫,那么你可以用leftOuterJoin来替代join。Spark还有fullOuterJoin和rightOuter,可以根据你想保留的记录选择使用。丢失的值会以None的形式存在:
def outerJoinScoresWithAddress( scoreRDD : RDD[(Long, Double)],
addressRDD : RDD[(Long, String )]) : RDD[(Long, (Double, Option[String]))]= {
val joinedRDD = scoreRDD.leftOuterJoin(addressRDD)
joinedRDD.reduceByKey( (x, y) => if(x._1 > y._1) x else y )
}选择执行过程
由于join数据时,Spark需要被join的数据在相同的分区。所有,默认实现是进行shuffled hash join。shuffled hash join会将第二个数据集按照第一个数据分区,这么一来有着相同hash值的key就会在相同的分区中了。虽然这种方法有用,但由于它需要shuffle,所以很昂贵。而以下情况可以避免shuffle:
- 连个RDD都有已知的partitioner
- 其中一个数据足够小到保存到内存这么一来我们就可以使用广播 hash join
注意,若RDD协同了,那么网络传输和shuffle都能避免。
通过分配已知Partitioner来加速Join
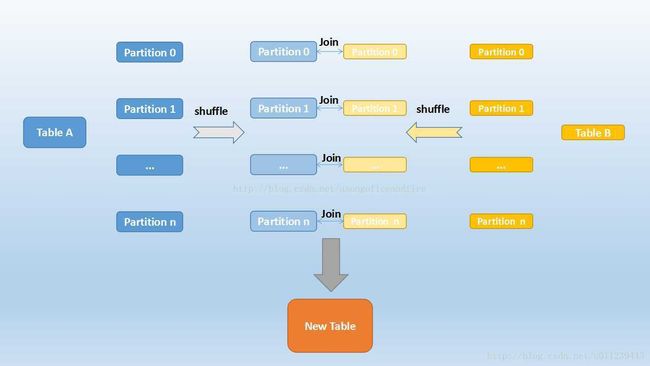
Spark是一个分布式的计算引擎,可以通过分区的形式将大批量的数据划分成n份较小的数据集进行并行计算。这种思想应用到Join上便是Shuffle Hash Join了。利用key相同必然分区相同的这个原理,Spark将较大表的join分而治之,先将表划分成n个分区,再对两个表中相对应分区的数据分别进行Hash Join。其原理如下图:
而这仅仅适用于join with inputs co-partitions的情况。当在join with inputs not co-partitions
首先将两张表按照join keys进行了重新shuffle,保证join keys值相同的记录会被分在相应的分区。分区后对每个分区内的数据进行排序,排序后再对相应的分区内的记录进行连接。
但是shuffle操作十分昂贵,为了避免shuffle,我们可以通过使用下面的方案:
如果你在做join之前,其中一个RDD(RDD_A)不得不先进行一个shuffle操作,比如说aggregateByKey或者reduceByKey。你可以将该shuffle操作所使用的partitioner设置为另外一个RDD(RDD_B)的partitioner(若RDD_B的partitioner为None,则根据RDD_Bd的分区数new一个HashPartitioner),并持久化RDD_A,这样一来就可以避免两个RDD join时的shuffle了:
def joinScoresWithAddress3( scoreRDD : RDD[(Long, Double)],
addressRDD : RDD[(Long, String )]) : RDD[(Long, (Double, String))]= {
val addressDataPartitioner = addressRDD.partitioner match {
case (Some(p)) => p
case (None) => new HashPartitioner(addressRDD.partitions.length)
}
val bestScoreData = scoreRDD.reduceByKey(addressDataPartitioner, (x, y) => if(x > y) x else y)
bestScoreData.cache
bestScoreData.join(addressRDD)
}建议在重分区后总是进行持久化。
广播 Hash Join
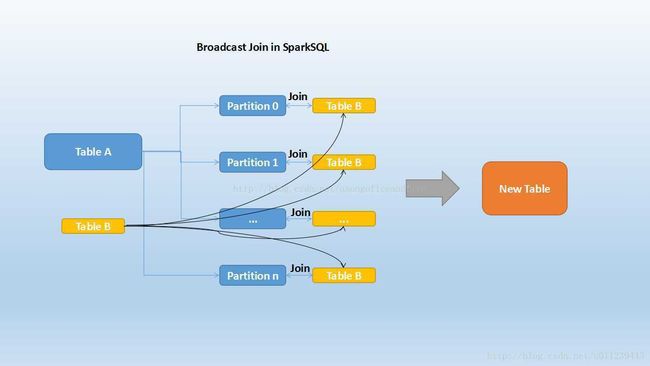
若RDD_B小到足以存到内存,那么我们可以使用广播变量将它push到各个节点。这种方法不需要shuffle,而是RDD_A的各个分区,分别会被RDD_B中相关的值join上,形成Child RDD 对应的分区。有时候Spark会很机智的自动帮你做这件事。
部分手动广播 Hash Join
有时候,我们的RDD_B并不能足够小到都能装进内存,但是有些RDD_A中的key会重复很多次,这时候你就可以想着只广播RDD_B中在RDD_A中出现最频繁的那些值。当一种key值在RDD_A中多到一个partition都装不下时,这种方法会非常有用。在这种情况下,你可以对RDD_A使用countByKeyApprox来近似得到哪些key需要广播。然后,你将从RDD_B中filter出来需要广播的RDD_B_0和不要广播的RDD_B_1,将RDD_B_0 collect成本地的HashMap。使用sc.broadcast广播该HashMap,使得每个节点都有一个备份,与RDD_A手动的执行join,得到结果RDD_C_1。再根据HashMap将RDD_A中多次重复的key值去掉,生成RDD_A_1。对RDD_A_1和RDD_B_1进行标准的join,得到结果RDD_C_0,并unoin上RDD_C_1,得到最终的结果。
这种方法虽然有点复杂,但是在对高度倾斜的数据进行处理时的效果很好。