【学点数据结构和算法】04-散列表
写在前面: 博主是一名软件工程系大数据应用开发专业大二的学生,昵称来源于《爱丽丝梦游仙境》中的Alice和自己的昵称。作为一名互联网小白,
写博客一方面是为了记录自己的学习历程,一方面是希望能够帮助到很多和自己一样处于起步阶段的萌新。由于水平有限,博客中难免会有一些错误,有纰漏之处恳请各位大佬不吝赐教!个人小站:http://alices.ibilibili.xyz/ , 博客主页:https://alice.blog.csdn.net/
尽管当前水平可能不及各位大佬,但我还是希望自己能够做得更好,因为一天的生活就是一生的缩影。我希望在最美的年华,做最好的自己!
前面已经陆陆续续写了几篇介绍数据结构的博客,包含数组,链表,栈和队列…本篇博客,我们再来学习一种有趣的数据结构——散列表。

概念
首先我们需要明白什么是哈希表?
哈希表(Hash table,也叫散列表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
只要给出一个Key,就可以高效查找到它所匹配的Value,时间复杂度接近 于O(1)。

从散列表通过Key来查找Value的方式,我们不难得出,散列表在本质上也是一个数组
但是看到这里,就有朋友想问了,数组不是只能通过下标(数字索引)来进行访问元素吗?散列表的key值是以字符串类型为主的,那是怎么将它们关联在一起的呢???

哈希函数
其实有这样的疑惑是很正常的。
我们在上面概念介绍时,谈到过一个概念,叫做"散列函数",其实它就是我们所熟知的哈希(Hash)函数。
我们正是通过哈希函数,把Key和数组下标进行转换。

在不同的语言中,哈希函数的实现方式是不一样的。这里以Java的常用集合HashMap 为例,来看一看哈希函数在Java中的实现。
在Java及大多数面向对象的语言中,每一个对象都有属于自己的hashcode,这个hashcode是区分不同对象的重要标识。无论对象自身的类型是什么,它们的hashcode都是一个整型变量。
既然hashcode和数组都是整型变量,那么它们之间转换就很容易实现。事实上,它们之间的转换遵循下面的公式,也就是所谓的哈希函数。

通过哈希函数,我们可以把字符串或其他类型的Key,转化成数组的下标index。
如给出一个长度为8的数组,则当


看到这里,大家是否有一种恍然大悟的感觉呢!我们如果想要往散列表中写入元素,实际上就是先对key值求hash,然后与数组长度求余得到一个数值,然后把元素放入到对应数值下标的数组中即可。

哈希冲突
但是,是否有考虑过有这么一种情况?
由于数组的长度是有限的,当插入的元素越来越多时,不同的Key通过哈希函数获得的下标有可能是相同的。例如002936这个Key对应的数组下标是2;002947这个Key 对应的数组下标也是2。
这个时候,显然key为002947的value无法插入到下标为2的数组中。

这种情况,就叫作哈希冲突。
解决哈希冲突的方法,主要有链表法和开放寻址法
开放寻址
开放寻址法的原理很简单,当一个Key通过哈希函数获得对应的数组下标已被占用 时,我们可以“另谋高就”,寻找下一个空档位置。
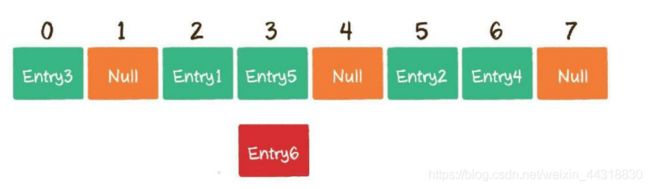


这就是开放寻址法的基本思路。当然,在遇到哈希冲突时,寻址方式有很多种,并不一定只是简单地寻找当前元素的后一个元素,这里只是举一个简单的示例而已。
在Java中,ThreadLocal所使用的就是开放寻址法。
链表法
接下来,重点讲一下解决哈希冲突的另一种方法——链表法。这种方法被应用在了Java的集合类HashMap当中。
HashMap数组的每一个元素不仅是一个Entry对象,还是一个链表的头节点。每一个 Entry对象通过next指针指向它的下一个Entry节点。当新来的Entry映射到与之冲突的数组位置时,只需要插入到对应的链表中即可。

扩容
在讲解数组时,曾经介绍过数组的扩容。既然散列表是基于数组实现的,那么散列表 也要涉及扩容的问题。
首先,什么时候需要进行扩容呢?
当经过多次元素插入,散列表达到一定饱和度时,Key映射位置发生冲突的概率会逐 渐提高。这样一来,大量元素拥挤在相同的数组下标位置,形成很长的链表,对后续插入操作和查询操作的性能都有很大影响。

这时,散列表就需要扩展它的长度,也就是进行扩容。
对于JDK中的散列表实现类HashMap来说,影响其扩容的因素有两个。
- Capacity,即HashMap的当前长度
- LoadFactor,即HashMap的负载因子,默认值为0.75f
衡量HashMap需要进行扩容的条件如下:

事实上,扩容不是简单地把散列表的长度扩大,而是经历了下面两个步骤:
1、扩容,创建一个新的Entry空数组,长度是原数组的2倍。
2.重新Hash,遍历原Entry数组,把所有的Entry重新Hash到新数组中。为什么要重 新Hash呢?因为长度扩大以后,Hash的规则也随之改变。
经过扩容,原本拥挤的散列表重新变得稀疏,原有的Entry也重新得到了尽可能均匀的分配。
扩容前的HashMap
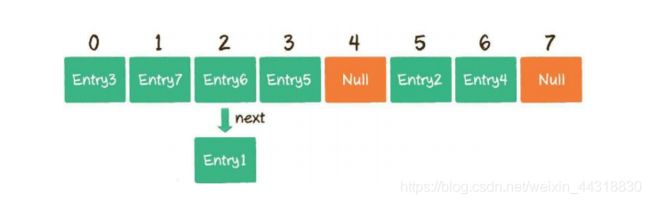
扩容后的HashMap

以上就是散列表各种基本操作的原理。由于HashMap的实现代码相对比较复杂,有兴趣的读者可以在JDK中直接阅读HashMap类的源码。
需要注意的是,关于HashMap的实现,JDK 8和以前的版本有着很大的不同。当多个 Entry被Hash到同一个数组下标位置时,为了提升插入和查找的效率,HashMap会把Entry 的链表转化为红黑树这种数据结构。建议读者把两个版本的实现都认真地看一看,这会让你受益匪浅。
本篇博客中说明和彩图大部分来源于《漫画算法》,应本书作者要求,加上本书公众号《程序员小灰》二维码。

感兴趣的朋友可以去购买正版实体书,确实不错,非常适合小白入门。

总结
散列表也叫哈希表,是存储Key-Value映射的集合。对于某一个Key,散列表可以在接近O(1)的时间内进行读写操作。散列表通过哈希函数实现Key和数组下标的转换,通过开放寻址法和链表法来解决哈希冲突。
如果本文对您有所帮助,不妨点个赞支持一下博主
希望我们都能在学习的道路上越走越远
