autoencoder入门
autoencoder
- 应用
- autoencoder
-
- 结构
- 约束
- 数学表达式
- 网络
- 优缺点
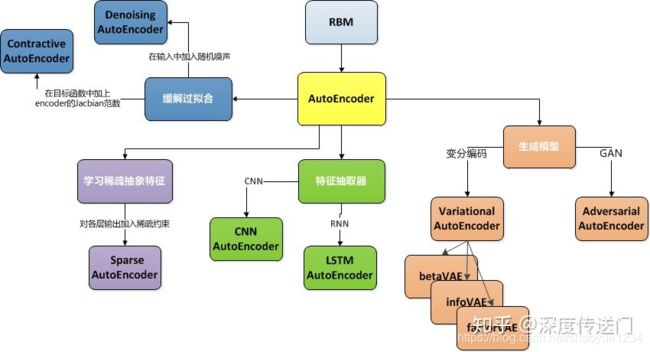
- 主要变体
- sparse autoencoder
-
- 思想
- 约束
- 数学表达式
- 网络
- 优缺点
- Denoising AutoEncoder
-
- 思想
- 网络
- Variational AutoEncoder
-
- 思想
- 约束
- 网络
- 优缺点
- U-net
-
- 网络
- 其他autoencoder
-
- Contrative AutoEncoder(CAE)
- Stacked AutoEncoder(SAE)
- 其他
- CNN/LSTM autoencoder
- 应用于有监督
- 参考资料
应用
- Dimensionality Reduction
- Information Retrieval
- Anomaly Detection
- Image Processing
autoencoder
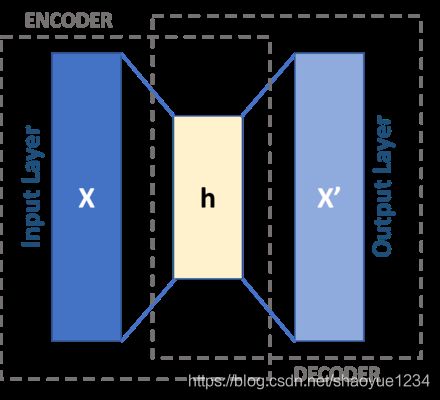
结构
Input Layer、Hidden Layer、Output Layer
中间的Internal Representation又称为bottleneck
约束
Hidden Layer 的维度要远小于 Input Layer
Output 用于重构 Input,也即让误差最小![]()
数学表达式
![]()
网络



优缺点
优点:
- 是增强的 PCA:AutoEncoder 具有非线性变换单元,因此学出来的 Code 可能更精炼,对 Input 的表达能力更强。
缺点:
- 由于 AutoEncoder 是训练出来的,故它的压缩能力仅适用于与训练样本相似的样本
- AutoEncoder 还要求 encoder 和 decoder 的能力不能太强。极端情况下,它们有能力完全记忆住训练样本,那么 Code 是什么也就不重要了,更不用谈压缩能力了
主要变体

sparse autoencoder
思想
增加了稀疏的约束
Sparse autoencoder may include more (rather than fewer) hidden units than inputs, but only a small number of the hidden units are allowed to be active at once.
稀疏的性质:
- 有降维的效果,可以用于提取主要特征
- 由于可以抓住主要特征,故具有一定抗噪能力
- 稀疏的可解释性好,现实场景大多满足这种约束(如“奥卡姆剃刀定律”)
為什麼要盡量稀疏呢?事實上在特徵稀疏的過程裡可以過濾掉無用的訊息,每個神經元都會訓練成辨識某些特定輸入的專家,因此 Sparse AE 可以給出比原始資料更好的特徵描述。
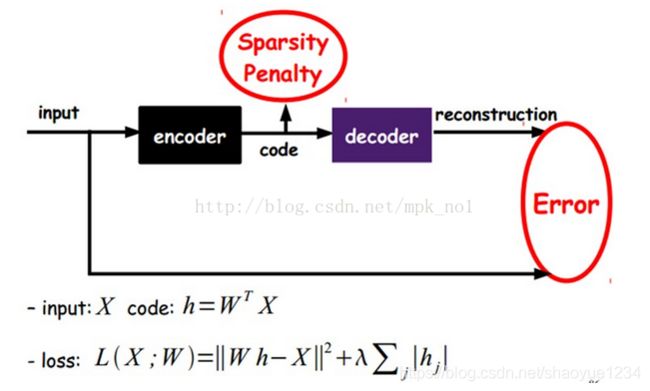
约束
L(x,x’)+spase(H)
Recalling that {h}=f(Wx+b), the penalty encourages the model to activate (i.e. output value close to 1) some specific areas of the network on the basis of the input data, while forcing all other neurons to be inactive (i.e. to have an output value close to 0).
通过在AutoEncoder的基础上加上L1正则化(L1主要用来约束每一层中的结点中大部分都为0,只有少数不为0),就得到了稀疏自动编码器。
数学表达式
![]()
其中,KL表示 KL散度,p表示网络中神经元的期望激活程度(若 Activation 为 Sigmoid 函数,此值可设为 0.05,表示大部分神经元未激活),pj表示第j个神经元的平均激活程度。在此处,KL散度 定义如下

pj定义为训练样本集上的平均激活程度,公式如下。其中xi表示第i个训练样本

另外,还有一种方法就是对神经网络各层的输出加入L1约束。
网络

优缺点
Denoising AutoEncoder
思想
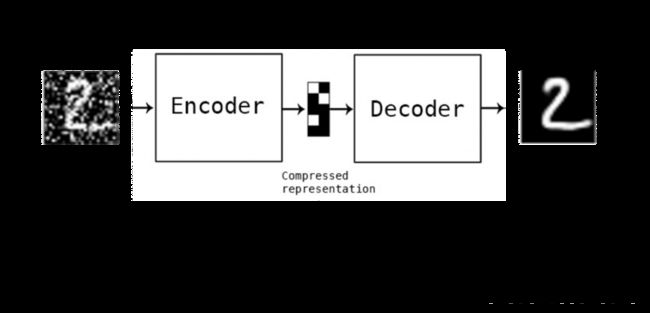
在原样本中增加噪声,并期望利用 DAE 将加噪样本来还原成纯净样本。
Denoising Autoencoder(降噪自动编码器)就是在Autoencoder的基础之上,为了防止过拟合问题而对输入的数据(网络的输入层)加入噪音,使学习得到的编码器W具有较强的鲁棒性,从而增强模型的泛化能力。Denoising Auto-encoder是Bengio在08年提出的,具体内容可参考其论文:Extracting and composing robust features with denoising autoencoders.
来自论文:
Vincent Extracting and composing robust features with denoising autoencoders, 2008
目前添加噪声的方式大多分为两种:添加服从特定分布的随机噪声;随机将输入x中特定比例置为0。
网络
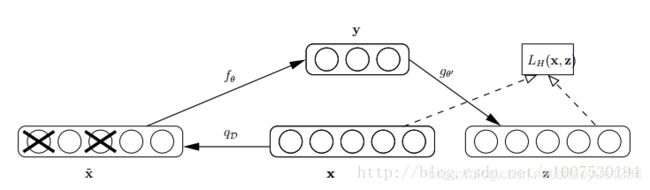 其中x是原始的输入数据,Denoising Auto-encoder以一定概率把输入层节点的值置为0,从而得到含有噪音的模型输入xˆ。这和dropout很类似,不同的是dropout是隐含层中的神经元置为0。
其中x是原始的输入数据,Denoising Auto-encoder以一定概率把输入层节点的值置为0,从而得到含有噪音的模型输入xˆ。这和dropout很类似,不同的是dropout是隐含层中的神经元置为0。
以这丢失的数据x’去计算y,计算z,并将z与原始x做误差迭代,这样,网络就学习了这个破损(原文叫Corruputed)的数据

Variational AutoEncoder
思想
Kingma 和 Welling 在“Auto-Encoding Variational Bayes, 2014”中提出的一种生成模型。VAE 作为目前(2017)最流行的生成模型之一,可用于生成训练样本中没有的样本,让人看到了 Deep Learning 强大的无监督学习能力。
详细内容可参考论文"Tutorial on Variational Autoencoders"和博客“Tutorial - What is a variational autoencoder? ”。
约束
生成的向量服从高斯分布
由于高斯分布可以通过mean和standard deviation进行参数化,因此VAE理论上可以让你控制生成的图片
网络
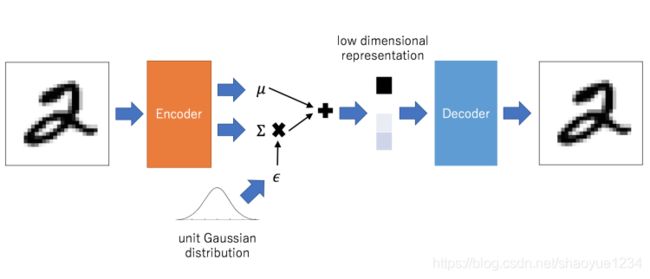
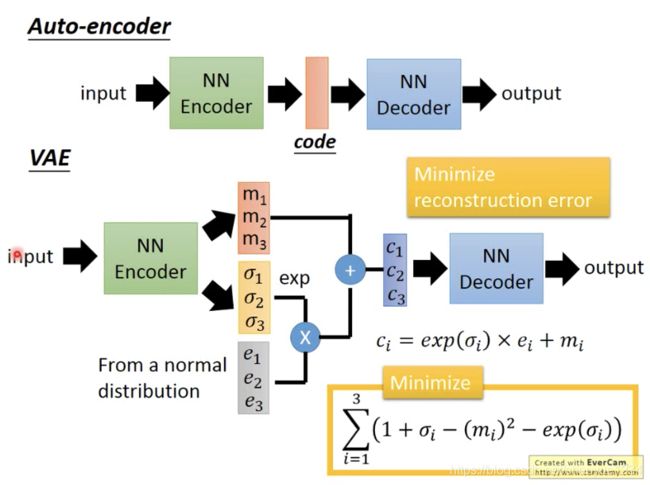
- 先輸出兩個向量:mean 和 standard deviation
- 用normal distribution產生第三個向量
- 把第二個向量做 exponential,之後跟第三個向量做相乘後,把它跟第一個向量相加,即成為中間層的隱含向量
优缺点
VAE 可以解讀隱含向量中的每一個維度(dimension)分別代表什麼意思,也因此理想上可以調整想要生成的圖片
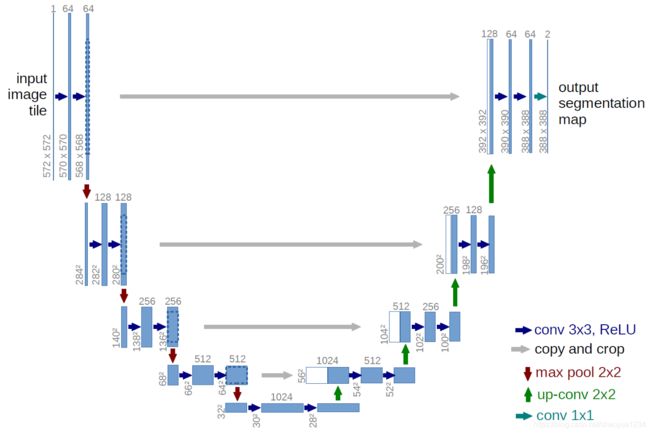
U-net
网络
其他autoencoder
Contrative AutoEncoder(CAE)
在文章"Contractive auto-encoders: Explicit invariance during feature extraction, 2011"中提出。其与 DAE 的区别就在于约束项进行了修改,意在学习出更加紧凑稳健的 Code。
Stacked AutoEncoder(SAE)
在文章“Greedy Layer-Wise Training of Deep Networks, 2007”中提出。作者对单层 AutoEncoder 进行了扩展,提出了多层的 AutoEncoder,意在学习出对输入更抽象、更具扩展性的 Code 的表达。
其他
除此之外,还有将传统 FNN 网络中的结构融入到 AutoEncoder 的,如:Convolutional Autoencoder、 Recursive Autoencoder、 LSTM Autoencoder 等等。
recursive autoencoder
seq2seq
CNN/LSTM autoencoder
以LSTM AutoEncoder为例,目标是针对输入的样本序列学习得到抽象特征z。因此encoder部分是输入一个样本序列输出抽象特征z,采用如下的Many-to-one LSTM;而decoder部分则是根据抽象特征z,重构出序列,采用如下的One-to-many LSTM。

应用于有监督

输入input可以经过多层encoder-decoder得到向量表示,然后可以在最后一层添加一个分类器,例如逻辑回归、SVM、随机森林,或者神经网络中的softmax。通过有标签的样本可以训练调整整个网络中的参数,AutoEncoder过程可以通过有监督的训练过程调整参数,也可以不调整。
参考资料
- 当我们在谈论 Deep Learning:AutoEncoder 及其相关模型
- autoencoder
- AutoEncoder (一)-認識與理解
- 自动编码器AutoEncoder学习总结
- what are autoencoders
- 降噪自动编码机(Denoising Autoencoder)
- 一文看懂AutoEncoder模型演进图谱