R语言自然语言处理1:中文语料库构造
欢迎关注我的新浪微博:Jenny爱学习
微信公众号:R语言数据分析与实践
如论文借鉴, 请标明引用. 作者:李珍妮 邮箱:[email protected]
李珍妮. R语言自然语言处理:中文语料库构造 [EB/OL] 网址. 2018-8-17
本文将介绍徐志摩诗集的文本挖掘方法
NLP(Natural Language Processing)自然语言处理,旨在让计算机理解人类的语言,并实现人机智能交互.商业、政府机构、个人都面对着海量的文本数据,这些数据与我们的生活、工作日常休戚相关,大量的文本中潜在着巨大的信息价值亟待人们发现.
当前, 自然语言处理有三个主要应用方向:
- 语言计算——面向文本大数据的语言处理:词法分析、语法分析、语义分析、文本分类、文档摘要、机器翻译等
- 知识计算——从无结构的大数据中准确高效的获取知识:开放信息抽取、知识获取与融合、知识表示、知识推理、多模态知识工程
- 社会计算——在线媒体积累了海量文本内容:用户画像、个性化推荐、社会网络分析
本篇文章的文本挖掘工作,将通过最新版本的R支持包——tm包进行文本挖掘的内容.tm包目前已支持PDF/DOC等常见文档格式的读取和处理,同时支持在线数据/zip压缩数据的处理. 汉字目前普及度越来越大, tm包已经可以支持汉字的文本挖掘工作.
一.操作环境
- MacOS 10.12.3
- R version 3.44(2018-3-15)
- tm包(0.7-5) 2018-7-29
二.工作原理
tm包通过Corpus(语料)对文本文档进行处理, 语料为文本文档的集合.
函数说明:
- VCorpus(x, readerControl):用于存储临时语义, 即临时变量, 临时变量在R的文本处理中充当中间转换的作用. 当R对象被移除, 临时变量随即丢失.
- PCorpus :用于处理永久语义. 文本内容保存在数据库/word文档等中, 即数据保存在R的外部. R通过指针访问外部文本数据库, 此时R对象相当于全局变量, 所有涉及相应语义的文本挖掘结果将被保存.
VCorpus(x, readerControl)参数说明:
1. x需使用单一数据类型作为tm包的文本处理对象, 可选对象为
- DirSource=目录(用于处理文件系统),
- VectorSource=向量,
- DataframeSource=数据框结构(如csv 文件)
- URISource
- XMLSource=网络文本
- ZipSource=压缩文本
getSource( ) 列出可用的数据形式
 tm包可分析的数据形式
tm包可分析的数据形式
2. readerControl 是一串带有reader和language的列表
reader 通过原始文本在R中构造文档 可选参数:
- readPlain()
- readPDF()
- readDOC()
- readXML()
……
getReaders() 可查看tm包当前支持的最新文档类型
 tm支持的数据种类
tm支持的数据种类
language 采用ISO 639-2进行编码
PCorpus(x, readerControl, dbControl) 参数说明:
dbControl参数通过命名参数dbName将文档输出到外部数据存储对象中.
dbType 通过filehash参数设置有效数据库
三 语言设置
tm包中处理语言使用ISO-639-2,中文对应的编码为“zh”,其他编码可在表中查询
四. 构造语料
1.载入相关packages
 加载packages
加载packages
1. txt格式的文本信息 :
 结果返回txt格式文档有6个
结果返回txt格式文档有6个
2. doc格式:
- 向量是数据处理中最快速、高效的方式.
- 将doc内容, 按照向量的形式构造出语料,即“term-document matrices” (词项-文档矩阵)
 构造2个doc文件作为语料的简单例子
构造2个doc文件作为语料的简单例子
3.构造语料分析文档
 构造二进制文本文档
构造二进制文本文档
5. 数据保存
通过操作外部数据集(doc/txt), 在R中构造了一个语料库, 由于使用的是VCorpus参数, 这些数据/语料仅作为临时变量存储在R中, 并未在硬盘中永久保存.
通常, 一个文本挖掘的工作是长期、连续的. 因此需要将文本挖掘过程中, 产生的临时变量存储.
使用 writeCorpus( )函数:
6.语料检查
通常一个语料库是一个数据集, 包含了上千或上万篇幅的文档, print( )函数提供了一个精简查看文档的方式,
inspect( )函数可查看文档的更多信息
 查看语料库信息
查看语料库信息
tm包对文章的操作均采用向量的方式. tm包中, 对于字符的操作与向量的操作通用.
 获取第6篇文章内容——《再别康桥》
获取第6篇文章内容——《再别康桥》
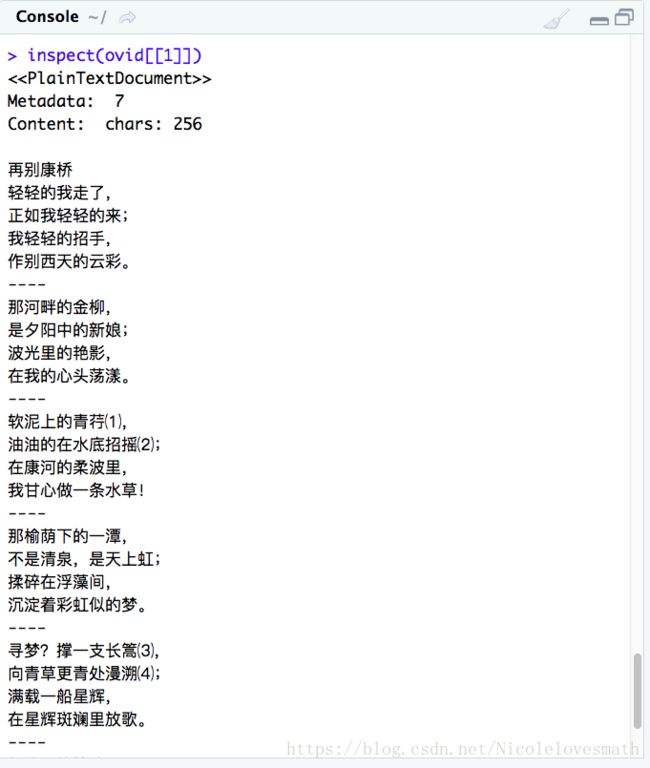 读取中文文档内容
读取中文文档内容
由于tm包将文本中的字符按照向量的形式进行操作, 因此tm包包括了所有对向量的操作方式.(提取、转置、特征值等等)