大数据学习笔记(spark的shuffler过程)
在Spark中,task的计算模式是管道计算模式,在以下两种情况会数据落地磁盘
遇到action类算子
stage->stage的 shuffle write 过程
对于一个计算框架来说,要做分组,做聚合,shuffle是一个很重要的环节
在spark中有两种shuffle方式:
- HashShuffle(避免shullfle中的排序)
- SortShuffle
1、HashShuffle
普通运行机制
下面对一段wordCount伪代码进行shuffle分析
val rdd=sc.textFile()
val wordRdd=rdd.flatMap(_.split(" "))
val pairRdd=wordRdd.map(_,1)
val restRdd=pairRdd.reduceByKey(_+_)
restRdd.foreach(println)
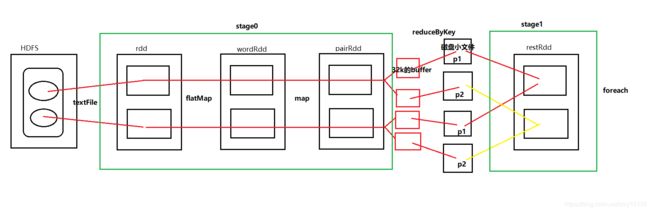
在spark的shuffle过程中不需要排序和分组,而在MapReduce中需要进行排序,排序是为了分组,分组是因为一组数据执行一次reduce,这跟设计思想有关。
整个Application只有1个job,有2个stage。
具体过程如下:
- 从HDFS中拉去文件
- 在stage0中进行一系列计算
- 数据由stage0到stage1要进行shuffle
1). shuffle write过程,数据通过大小为32k的buffer缓冲,再写入磁盘文件。每一个task的计算结果会根据key的HashCode值与ReduceTask的个数取模决定写入哪个分区文件,保证相同的数据一定落入到同一个分区文件中。
2). shuffle read过程,reduce task拉取属于自己的分区文件中的数据,进行pipeline计算,此时不需等待全部数据拉完才开始计算 - 执行foreach
合并运行机制
在shuffle write过程中不可避免的会产生多个磁盘小文件。就如上面的例子中,1个job中有两个map task和两个reduce task,shuffle过程中产生了4个磁盘小文件。由此,我们推导出磁盘小文件数量的公式:
磁盘小文件数量 = map task数量 * reduce task 数量
我们再看一个例子

随着task的增加,磁盘小文件的增速要远远大于task。在实际生产环境中必然会造成磁盘小文件过多,这会导致:
- OOM,读写文件以及缓存过多
- 耗时低效的IO操作
由此,spark提供了一种合并机制,在同一个core中运行的task可以共享buffer,并且写入相同的磁盘小文件
如图,合并优化之后的shuffle过程
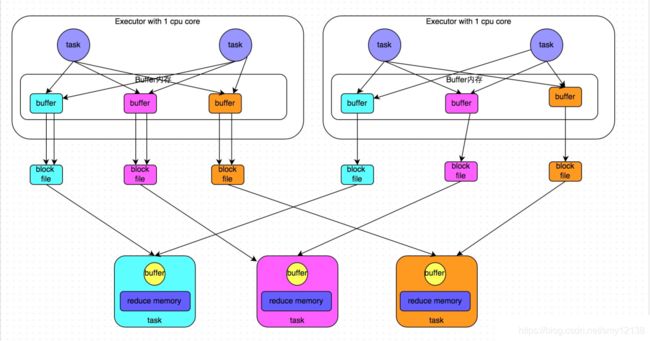
经过合并优化之后的shuffle过程,磁盘小文件数量的公式:
磁盘小文件数量 = core 数量 * reduce task 数量
- 在这里引入一个话题:通常情况下,每一个core都会分配2~3个task,这是因为core与core之间有性能差异。性能较差的core在运行过程中可能会将还未进行的task交给其他已经完成了所有task的core来处理,这样可以更好的利用资源,提高效率。
所以,在实际生产环境中core 数量要远远小于map task数量,采用合并机制产生的小文件相对少得多
2、SortShuffle
普通运行机制
spark中的sortShuffle和MapReduce中shuffle过程差不多。
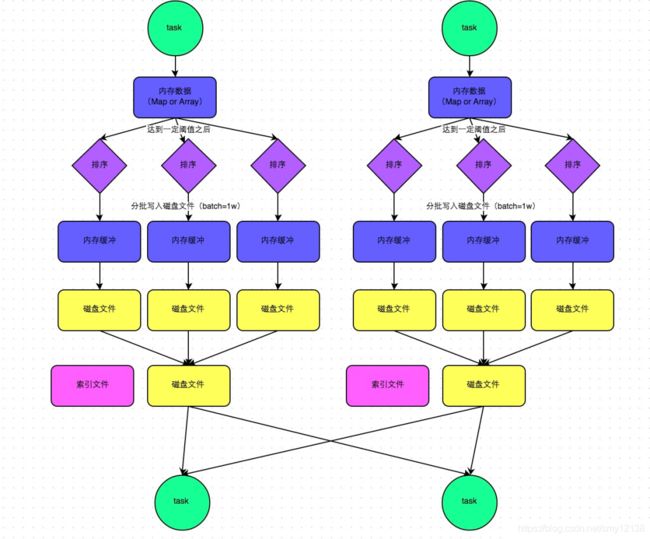
map task处理完数据后,会先写到内存的数据结构中,这数据结构可以是Map或者是Array。聚合类算子像reducebykey等处理完的数据使用map数据结构,非聚合类算子如sortbykey等处理完的数据使用array数据结构,由内部自动切换。
这个数据结构的大小默认为5M,map task往这5M的数据结构中写数据,当这5M的内存被写满时,并不会马上溢写。因为spark是一个软件框架,是运行在JVM中的一个进程,它不能严格控制executor内存使用 ,由一个监控对象监控executor内存使用。当这5M的内存被写满,这个监控对象就会为数据机构再次申请内存,当申请不到内存时,才会开始溢写。溢写过程也跟MapReduce中大体一致,会进行分区、sort和combiner过程,不同点在于spark中的内存缓存区buffer的大小是32K。
当然merge过程不是像上图所画的那些,上图只是为了方便分析和理解,当产生了2个磁盘文件时,就会merge成一个磁盘文件,产生的新的文件又会和这磁盘文件进行merge,以此类推。所以一个map task最终产生的磁盘文件个数是两个,一个是数据文件,一个是索引文件(记录分区的起始位置和终止位置)。即磁盘小文件和map task个数有关
在reduce task拉取数据时,先去解析索引文件,再拉取数据。
bypass运行机制
此外,sortShuffle还提供了一种bypass运行机制,即在溢写的过程中不会去排序
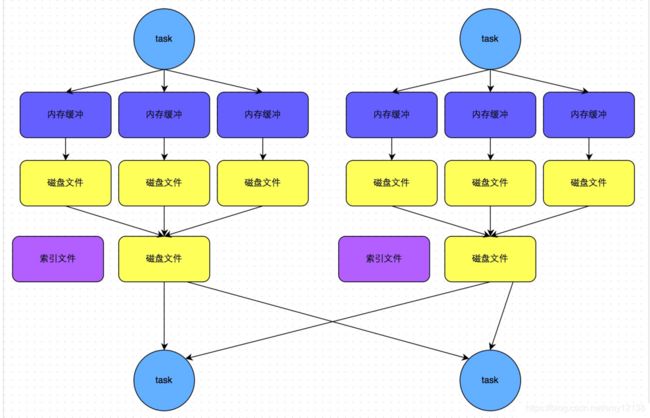
bypass运行机制的触发条件是根据spark.shuffle.sort.bypassMergeThreshold参数的值,这个参数的默认是200。当shuffle reduce task数量小于这个值时,会启动bypass运行机制。
3、磁盘小文件寻址问题
一个spark job会分发很多task任务,map task会依据数据本地化,分发到数据的节点,那么reduce task是如何知道这些map task的位置,去拉取他们产生的磁盘文件呢?
在Executor中有一个MapOutputTrackerWorker对象,map task执行完毕后,将执行结果信息,比如磁盘小文件的位置,最终执行状态等信息封装到mapstatus中,然后调用本进程中的MapOutputTrackerWorker,将mapstatus对象发送到Driver中。在Driver中有一个MapOutputTrackerMaster对象接收mapstatus,它掌握整个计算过程中所有磁盘小文件的位置信息。
当reduce task要拉取数据时,也会调用MapOutputTrackerWorker对象,和Driver中的MapOutputTrackerMaster对象通信,得到磁盘小文件的地址位置,然后根据地址去拉取数据,进行pipeline计算。
拉取数据的工作不是有task去做的,由BlockManagerSlave对象完成,它把数据拉取到内存中,然后task从内存读取数据进行pipeline计算
4、shuffler调优
1)spark.shuffle.sort.bypassMergeThreshold
设置启用bypass机制的阈值(默认为200),若Shuffle Read阶段的task数小于等于该值,则Shuffle Write阶段启用bypass机制。
2)spark.shuffle.file.buffer (默认32M)
设置Shuffle Write阶段写文件时buffer的大小,若内存比较充足的话,可以将其值调大一些(比如64M),这样能减少executor的IO读写次数。
3)spark.shuffle.io.maxRetries (默认3次)
设置Shuffle Read阶段fetches数据时的重试次数,若shuffle阶段的数据量很大,可以适当调大一些。