从多张曝光图像中学习一个深度单图像对比度增强器
文章目录
-
- 一、引出问题
- 二、多曝光数据集
- 三、网络结构
-
- 1. 分量增强网络
- 2. 整体增强网络
- 四、实验结果
-
- 1. 实验设置
- 2. 与SICE方法比较
- 3. 与MEF相比
- 4. 失败案例
- 五、总结
一、引出问题
传统的单一图像对比度增强(SICE)方法包括基于直方图和Retinex理论,它的缺点总结如下:
- 复杂的自然场景和有限的图像信息很难恢复
- 重新分配发光强度,容易忽略图像的结构信息,从而产生严重的不切实际的效果,即失真。
- 多数SICE算法是基于图片是高质量图片的假设,而没有充分利用输入图像的信息
- SICE增强能力有限,因为受限于低对比度图像的有限的信息
因此有了基于多曝光图像序列的图像增强,主要有多曝光图像融合(MEF)和高动态范围图像堆叠(stack-based HDR image),再加上色调映射,但这些序列图像中会存在模糊或者物体移动,导致得到的结果产生伪影。
在图一中:
(a)曝光不足/过渡曝光的一个图像序列
(b)最先进的MEF算法:它可以将多张曝光图像合成为高可见性图像,所以可以恢复更多的细节,但对于移动的对象,则会产生重影伪影(比如蓝色刚框里移动的人影)
(c)最先进的SICE方法:只用单一的曝光不足图像作为输入,虽然不会产生重影,但由于单张图像信息有限,很容易丢失一些细节。

因此作者提出疑问,能否提出一种SICE方法既可以近似MEF对比度增强的效果,又可以不产生重影呢?
二、多曝光数据集
重点和主要贡献:
- 提出了一个大规模多曝光度的图像数据集,其中包括曝光度不同的低对比度图片和它们对应的高质量参考图像。
- 分步构建了三个基于CNN的SICE增强器,前两个是照明、细节增强网络分别提升图像对比度和细节恢复,最后一个全图增强器作为调节网络,平衡细节和纹理避免颜色失真
目标及实现:
- 数据集应包含高分辨率的多曝光图像序列,并覆盖不同的场景——
收集室内外场景覆盖了广泛的场景、主题、照明条件 - 对于每个序列,应生成高质量的参考图像,以便能够构建图像对用于端到端学习——
用13种最先进的MEF(8种)和HDR(5种)重构参考图像
① 数据收集
不同相机:七种
不同场景:包括室内(静态环境+三脚架,每个环境7-18幅不同曝光度的图像)和室外(由于人、车、树影位移产生偏移曝光,故采用连续拍摄,每个序列3-5张图像)
② 产生参考图像(这过程可真艰辛,作者是真的好有耐心啊,读这部分的时候就想献上我的膝盖!! )
大概分为三个步骤:
a. 10000张不同曝光水平图像,筛选出其中85%有图像扭曲(包括模糊、离焦、噪声影响)和物体移动的图片;
b. 剩余1200个序列,分别用13种MEF/HDR算法进行融合,产生1200x13=15600个融合结果;
c. 最后再通过主观实验去除仍不令人满意的图像,剩下589个高质量的参考图像和它们的相应序列
如下图所示,在图五中,左边是13种算法每种算法所占的百分比 ;右边即挑选过程示例。

三、网络结构
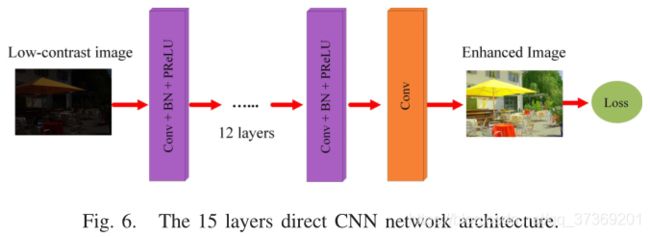
网络的设计作者刚开始直接使用一个15层的网络端到端的学习,如图6,发现效果不是很好。
然后参考了Retinex理论,图像低频信息代表全局自然度,高频信息代表局部细节,先对低对比度和参考图像每分通道采用加权最小二乘法(WLS)分解,把图像分为高频和低频部分,对两部分分别进行增强。训练的时候,先分别训练这两个stage,用第一阶段训练好的参数再来训练第二阶段的网络。两个阶段训练完后,移除第一阶段的两个loss,采用DSSIM作为loss来fine-tune整个网络。
用公式表示:
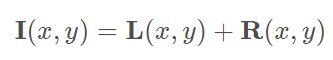
但因为直接合并两部分的结果效果不是很好,所以作者把增强后的两部分进行合并后再通过一个网络进一步增强,最终得到对比度增强的结果。整个网络结构如下所示:
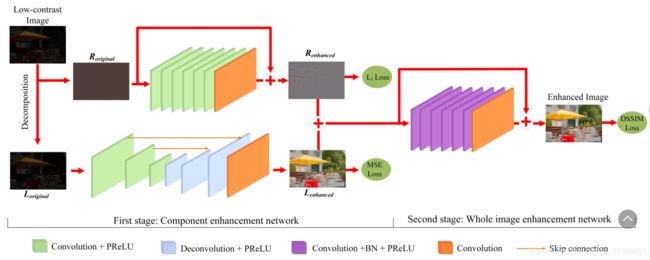
- Conv+PReLU: 64个3×3、5×5和9×9的滤波器,步幅为1和2,用于生成64个特征图,激活函数为PReLU(parametric rectifified linear unit)。
- Deconv+PReLU: 64个9×9、5×5和3×3的滤波器,步幅为2和1,生成64个特征图,激活函数为PReLU。
- Conv+BN+PReLU:64个3×3滤波器,采用批处理化(BN),激活函数是PReLU。
- Conv: 3个1×1大小滤波器,用于重构输出。
- Skip connection:直接连接,连接两个层的特征映射。
文中有说卷积层设置和激活函数选择的标准:
1、网络的卷积和反卷积策略可以保证输入输出大小相同。不仅避免了边界区域的伪影,而且减少了跨步滤波器的计算负担。
2、采用PRelu激活函数是由于训练参数有正有负且都包含输入图像的重要局部结构信息。
1. 分量增强网络
① Luminance Enhancement Network
由于照明分量代表图像全局对比,所以照明网络主要重构图像对比度。文中使用:U-net 结构作为照明网络,为了增大局部感受野同时避免跨步长卷积造成细节信息的损失。采用MSE作为损失函数,训练参数Θ,公式:
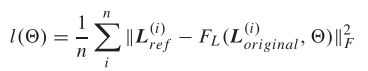
具体网络结构:

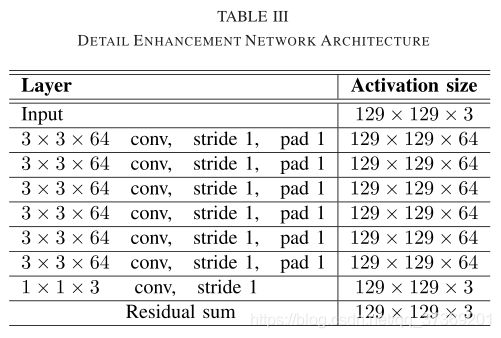
② Detail Enhancement Network
由于细节图表示图像的高频细节和边缘信息,所以细节(反射)图主要重构图像的细节特征。考虑到高频细节分量通常遵循Laplace分布并包含一些噪声和异常值,采用L1范数作为损失函数,公式:
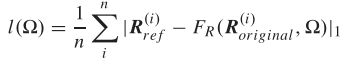
具体网络结构:
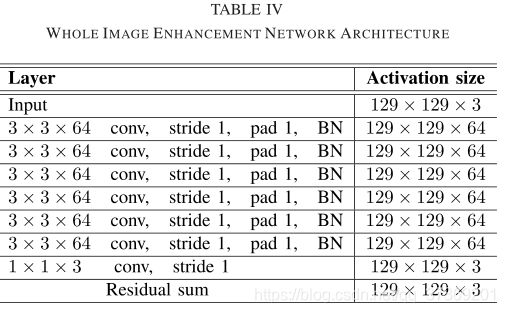
2. 整体增强网络
由于两个CNN网络是分别对对比度和细节进行增强的,所以不能保证合成之后整体图像质量和视觉效果。此外,由于原图的光照不均匀性,会导致合成之后的图像出现颜色失真。为了平衡图像的细节和纹理,文章又使用一个调整CNN网络将前两个网络结果合成后向参考图像学习。采用DSSIM作为损失函数,训练网络参数Ψ,公式:
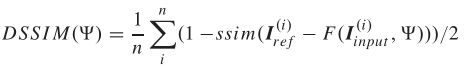
具体网络结构和细节增强网络类似,只是卷积层之后多加了一个批处理化过程:
四、实验结果
1. 实验设置
对于整个数据集按照训练集:验证集:测试集 = 7:1:2的比例来划分,且每个数据集都需要包括室内和室外不同曝光的图像。
2. 与SICE方法比较
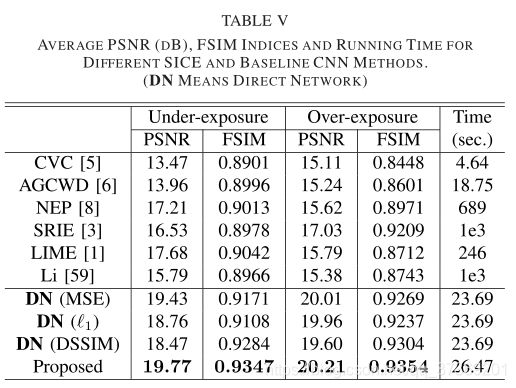
主要拿基于直方图(CVC、AGCMD)和基于Retinex方法(NPE、SRIE、LIME)与基于CNN的SICE以及3个基线直线网络放在一起对比。
首先是曝光不足图像:可以看出基于直方图的方法由于同时包含明暗条件,提取图像细节的能力有限;Retinex提高了整体的可视性那三个基线直线网络出现了不自然的增强、丢失细节和颜色扭曲;而我们的方法就很好的均衡了对比度并揭示了细节。
然后是过渡曝光图像:
然后看上边两个实验的数据,也就是这个表格里边的两个参数:峰值信噪比(PSNR)和特征相似度(FSIM)峰值信噪比(PSNR):数值越大,失真越小;特征相似度(FSIM):数值越大,越接近参考图像,可以看到我们的方法参数都是最大的,且使用时间也是很短的。
为了验证区域是否饱和,将RGB降为灰度,然后进行阈值化,如下边两个图,可以看出CNN可以恢复几乎所有的细节。
欠饱和

过饱和:

3. 与MEF相比
图16是静态场景,本文的方法使用单张图像得到了和MEF使用多个曝光水平图像几乎相同质量的增强效果,但是视觉效果上,我们的方法丢失了一些颜色信息
图17是动态场景,在这里基于CNN的SICE的优点就非常明显了,没有重影伪影。

4. 失败案例
这是一个失败的例子,文中的方法效果明显比不上MEF,分析原因是:曝光太严重这里的严重指的是范围和程度都很严重,所以对图像恢复造成的很大的影响。

五、总结
我们建立了一个多曝光图像数据集,包含589个图像序列和4413个不同曝光的高分辨率图像。
对于每个序列,使用13种MEF和基于堆栈的HDR算法生成相应的高质量参考图像。通过主观测试,筛选出质量最好的一幅作为每个场景的参考图像。
低对比度图像及其高质量参考图像在我们的数据集中的可用性允许高性能SICE方法的端到端学习。
作为一个演示,我们开发了一个简单而强大的基于CNN的SICE增强器,它能够自适应地为单个曝光过度或曝光不足的输入图像生成高质量的增强结果。
实验结果表明,所开发的SICE增强器在动态场景下的性能明显优于现有的SICE方法,甚至优于MEF和基于堆栈的HDR方法。