生成特定分布随机数的方法:Python seed() 函数&numpy &scikit-learn随机数据生成
描述
seed() 方法改变随机数生成器的种子,可以在调用其他随机模块函数之前调用此函数。。
语法
以下是 seed() 方法的语法:
import random
random.seed ( [x] )注意:seed(()是不能直接访问的,需要导入 random 模块,然后通过 random 静态对象调用该方法。
参数
x -- 改变随机数生成器的种子seed。如果你不了解其原理,你不必特别去设定seed,Python会帮你选择seed。
返回值
本函数没有返回值。
实例
#!/usr/bin/env python
import random
random.seed(0)
print "Random number with seed 0 : ", random.random()
# It will generate same random number
random.seed(0)
print "Random number with seed 0 : ", random.random()
# It will generate same random number
random.seed(0)
print "Random number with seed 0 : ", random.random()
import numpy
random.seed( 10 )
numpy.random.seed(10)
print "Random number with seed 10 : ", random.random()
print "Numpy.Random number with seed 10 : ", numpy.random.random()
# 生成同一个随机数
random.seed( 10 )
numpy.random.seed(10)
print "Random number with seed 10 : ", random.random()
print "Numpy.Random number with seed 10 : ", numpy.random.random()
# 生成同一个随机数
random.seed( 10 )
numpy.random.seed(10)
print "Random number with seed 10 : ", random.random()
print "Numpy.Random number with seed 10 : ", numpy.random.random()输出结果
Random number with seed 0 : 0.8444218515250481
Random number with seed 0 : 0.8444218515250481
Random number with seed 0 : 0.8444218515250481
Random number with seed 10 : 0.5714025946899135
Numpy.Random number with seed 10 : 0.771320643266746
Random number with seed 10 : 0.5714025946899135
Numpy.Random number with seed 10 : 0.771320643266746
Random number with seed 10 : 0.5714025946899135
Numpy.Random number with seed 10 : 0.771320643266746seed( ) 用于指定随机数生成时所用算法开始的整数值,如果使用相同的seed( )值,则每次生成的随即数都相同,如果不设置这个值,则系统根据时间来自己选择这个值,此时每次生成的随机数因时间差异而不同。
更多理解见 生成特定分布随机数的方法
Numpy
numpy比较适合用来生产一些简单的抽样数据。API都在random类中,常见的API有:
1) rand(d0, d1, …, dn) 用来生成d0xd1x…dn维的数组。数组的值在[0,1]之间
np.random.rand(3,2,2)
array([[[ 0.75450129, 0.42901482],
[ 0.96443585, 0.32667506]],
[[ 0.14964725, 0.05210716],
[ 0.22233923, 0.03842378]],
[[ 0.25808658, 0.72287114],
[ 0.46925528, 0.40520171]]])
2) randn((d0, d1, …, dn), 也是用来生成d0xd1x…dn维的数组。不过数组的值服从N(0,1)的标准正态分布
np.random.randn(3,2)
array([[ 0.66144212, 0.42805973],
[-1.70413147, 2.06557347],
[ 0.64347303, -0.28598613]])
如果需要服从的正态分布,
For random samples from N(μ,σ2), use:
sigma * np.random.randn(…) + mu
只需要在randn上每个生成的值x上做变换σx+μ即可
2.5 * np.random.randn(2, 4) + 3
array([[ 4.18824037, 3.26512024, 4.78196539, 9.33558273],
[ 1.82579451, 4.24870639, 3.20370651, 5.50917743]])
Two-by-four array of samples from N(3, 6.25)
3)randint(low[, high, size]),生成随机的大小为size的数据,size可以为整数,为矩阵维数,或者张量的维数。值位于半开区间 [low, high)。
np.random.randint(3, size=[2,3,4])
array([[[2, 0, 1, 2],
[0, 1, 0, 0],
[1, 1, 2, 2]],
[[1, 2, 0, 1],
[1, 1, 2, 0],
[0, 1, 1, 1]]])
返回维数维2x3x4的数据。取值范围为最大值为3的整数
np.random.randint(3, 6, size=[2,3]) #返回维数为2x3的数据。取值范围为[3,6)
array([[4, 5, 4],
[4, 5, 3]])
4) random_integers(low[, high, size]),和上面的randint类似,区别在与取值范围是闭区间[low, high]。
5) random_sample([size]), 返回随机的浮点数,在半开区间 [0.0, 1.0)。如果是其他区间[a,b),可以加以转换(b - a) * random_sample([size]) + a
(5-2)*np.random.random_sample(3)+2 #返回[2,5)之间的3个随机数
array([ 2.12014675, 4.97409966, 2.61624815])
scikit-learn随机数据生成API
scikit-learn生成随机数据的API都在datasets类之中,和numpy比起来,可以用来生成适合特定机器学习模型的数据。常用的API有:
1) 用make_regression 生成回归模型的数据
2) 用make_hastie_10_2,make_classification或者make_multilabel_classification生成分类模型数据
3) 用make_blobs生成聚类模型数据
4) 用make_gaussian_quantiles生成分组多维正态分布的数据* scikit-learn随机数据生成实例*
回归模型随机数据
这里我们使用make_regression生成回归模型数据。几个关键参数有n_samples(生成样本数), n_features(样本特征数),noise(样本随机噪音)和coef(是否返回回归系数)。例子代码如下
# -*- coding: UTF-8 -*-
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn.datasets.samples_generator import make_regression
# X为样本特征,y为样本输出, coef为回归系数,共1000个样本,每个样本1个特征
X, y, coef =make_regression(n_samples=1000, n_features=1,noise=10, coef=True)
# 画图
plt.scatter(X, y, color='black')
plt.plot(X, X*coef, color='blue',
linewidth=3)
plt.xticks(())
plt.yticks(())
plt.show()
分类模型随机数据
这里我们用make_classification生成三元分类模型数据。几个关键参数有n_samples(生成样本数), n_features(样本特征数), n_redundant(冗余特征数)和n_classes(输出的类别数),例子代码如下:
# -*- coding: UTF-8 -*-
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn.datasets.samples_generator import make_classification
# X1为样本特征,Y1为样本类别输出, 共400个样本,每个样本2个特征,输出有3个类别,没有冗余特征,每个类别一个簇
X1, Y1 = make_classification(n_samples=400, n_features=2, n_redundant=0,
n_clusters_per_class=1, n_classes=3)
plt.scatter(X1[:, 0], X1[:, 1], marker='o', c=Y1)
plt.show()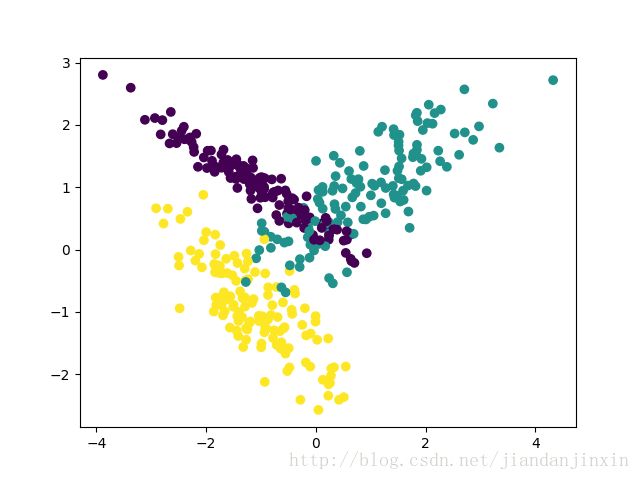
聚类模型随机数据
这里我们用make_blobs生成聚类模型数据。几个关键参数有n_samples(生成样本数), n_features(样本特征数),centers(簇中心的个数或者自定义的簇中心)和cluster_std(簇数据方差,代表簇的聚合程度)。例子如下:
# -*- coding: UTF-8 -*-
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn.datasets.samples_generator import make_blobs
# X为样本特征,Y为样本簇类别, 共1000个样本,每个样本2个特征,共3个簇,簇中心在[-1,-1], [1,1], [2,2], 簇方差分别为[0.4, 0.5, 0.2]
X, y = make_blobs(n_samples=1000, n_features=2, centers=[[-1,-1], [1,1], [2,2]], cluster_std=[0.4, 0.5, 0.2])
plt.scatter(X[:, 0], X[:, 1], marker='o', c=y)
plt.show()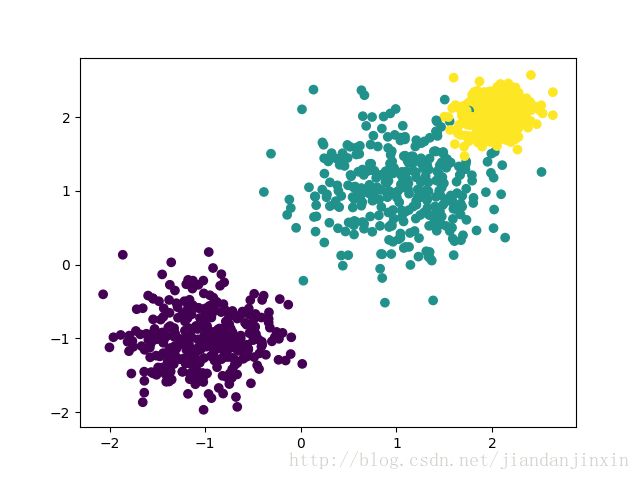
分组正态分布混合数据
我们用make_gaussian_quantiles生成分组多维正态分布的数据。几个关键参数有n_samples(生成样本数), n_features(正态分布的维数),mean(特征均值), cov(样本协方差的系数), n_classes(数据在正态分布中按分位数分配的组数)。 例子如下:
# -*- coding: UTF-8 -*-
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn.datasets import make_gaussian_quantiles
#生成2维正态分布,生成的数据按分位数分成3组,1000个样本,2个样本特征均值为1和2,协方差系数为2
X1, Y1 = make_gaussian_quantiles(n_samples=1000, n_features=2, n_classes=3, mean=[1,2],cov=2)
plt.scatter(X1[:, 0], X1[:, 1], marker='o', c=Y1)
plt.show()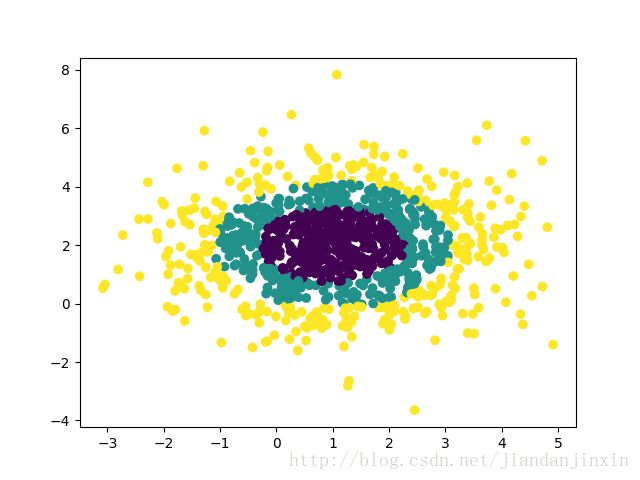
参考文献
Python seed() 函数
python 中 np.random.seed( ) 使用小技
机器学习算法的随机数据生成