SQL知识点简单回顾(MySQL)
最近收到了入职后的第一个任务,为此我得重新复习一遍数据库,以下是我在最近收到了入职后的第一个任务,为此我得重新复习一遍数据库,以下是我在帆软社区中找到的题目,虽然他们用中文做列名这点让我觉得很蠢,但题目还是很好的,值得一些对数据库掌握尚浅的朋友去试试看,链接在此。
警告:不要用中文做列名,不要用中文做列名,不要用中文做列名。
一、datetime的大小比较
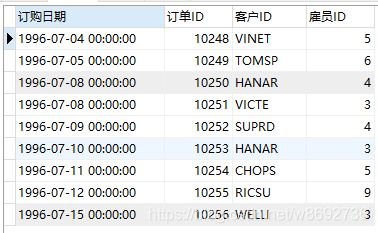
问题:查询订购日期在1996年7月1日至1996年7月15日之间的订单的订购日期、订单ID、客户ID和雇员ID等字段的值。 已知“订单日期”的类型为datetime,接下来要做的就是对时间进行比较,现有两个方法可供使用:
![]()
- 使用between字段
SELECT 订购日期, 订单ID, 客户ID, 雇员ID FROM 订单
WHERE unix_timestamp(订购日期) > unix_timestamp('1996-07-01 00:00:00')
AND unix_timestamp(订购日期) < unix_timestamp('1996-07-15 00:00:00');
unix_timestamp函数可以直接获取格式为“yyyy-MM-dd HH:mm:ss”的字符串所代表的时间,通过该方法能直接稳定的对datetime类型字段进行比较。
- 使用unix_timestamp将日期化为时间戳
SELECT 订购日期, 订单ID, 客户ID, 雇员ID FROM 订单
WHERE `订购日期` BETWEEN '1996-07-01 00:00:00' AND '1996-07-15 00:00:00';
使用between也可以起到相同的效果。上述两个方法的查询结果如下:
二、升降序
SQL语句当中采用 ORDER BY 字段对查询结果进行升序(ASC)或降序(DESC)排序。若有多个字段参与排序,则使用逗号进行分割,一个语句仅能写一个ORDER BY条件。
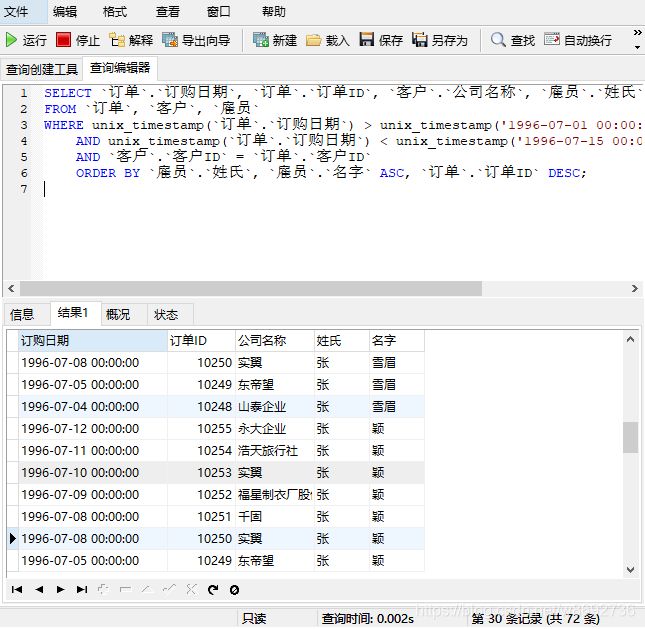
问题:查询订购日期在1996年7月1日至1996年7月15日之间的订单的订购日期、订单ID、相应订单的客户公司名称、负责订单的雇员的姓氏和名字等字段的值,并将查询结果按雇员的“姓氏”和“名字”字段的升序排列,“姓氏”和“名字”值相同的记录按“订单 ID”的降序排列。
SELECT `订单`.`订购日期`, `订单`.`订单ID`, `客户`.`公司名称`, `雇员`.`姓氏`, `雇员`.`名字`
FROM `订单`, `客户`, `雇员`
WHERE unix_timestamp(`订单`.`订购日期`) > unix_timestamp('1996-07-01 00:00:00')
AND unix_timestamp(`订单`.`订购日期`) < unix_timestamp('1996-07-15 00:00:00')
AND `客户`.`客户ID` = `订单`.`客户ID`
ORDER BY `雇员`.`姓氏`, `雇员`.`名字` ASC, `订单`.`订单ID` DESC;
此处‘雇员’表的字段‘姓氏’和‘名字’作为升序排序条件,‘订单ID’作为降序排序条件,故采用ORDER BY字段进行排序。查询结果如下:
三、显示运算结果
有时候,列表中的一些字段需要运算才能得到我们想要的结果,比如计算销售额,就需要‘单价’和‘数量’这两个字段的乘积。
问题:查询“10248”和“10254”号订单的订单ID、订单上所订购的产品的名称及其销售金额。 已知在‘订单明细’表中有单价、销售数量和折扣,故要求出销售额,就必须求这三个字段的计算结果。[ 在此处,销售额 = 单价 x 销售数量 x (1 - 折扣) ]
SELECT `订单`.`订单ID`, `产品`.`产品名称`,
(`订单明细`.`单价` * `订单明细`.`数量` * (1 - `订单明细`.`折扣`) ) AS '销售金额'
FROM `订单`, `产品`, `订单明细`
WHERE `订单`.`订单ID` = `订单明细`.`订单ID` AND `订单明细`.`产品ID` = `产品`.`产品ID`
AND (`订单`.`订单ID` = '10248' OR `订单`.`订单ID` = '10254');
字段的计算结果通过AS归束成一列并命名为‘销售额’,注意括号中公式的写法。同时,在最后判断订单ID的时候,我们必须把OR左右两侧的两个条件放到一个括号表示一个条件,否则会出现大量的重复。
四、简单显示前N条数据
问题:找出订单销售额前五的订单是经由哪家运货商运送的。 已知我们可以通过“订单明细”计算销售额,剩下要做的事情就是对销售额进行排序,使用"LIMIT"字段选取前5条信息进行显示。代码如下:
SELECT (`订单明细`.`单价` * `订单明细`.`数量` * (1 - `订单明细`.`折扣`)) AS '销售额', `运货商`.`公司名称`
FROM `订单明细`, `运货商`, `订单`
WHERE `订单`.`运货商` = `运货商`.`运货商ID`
AND `订单`.`订单ID` = `订单明细`.`订单ID`
ORDER BY (`订单明细`.`单价` * `订单明细`.`数量` * (1 - `订单明细`.`折扣`)) DESC LIMIT 5;
五、简单统计某一列中数值的出现次数
有时候我们需要求某一子列的累加和或统计其出现次数,比如说像“统计各班考试及格人数”、“统计某类商品的总销售量”这类事务,这时候我们就需要使用 “GROUP BY” 和 “ORDER BY” 这两个字段。“GROUP BY”使我们的表格可以某一子列为依据进行分组,“ORDER BY”则可以使我们的结果以某一子列的字典顺序进行升序或降序排序。
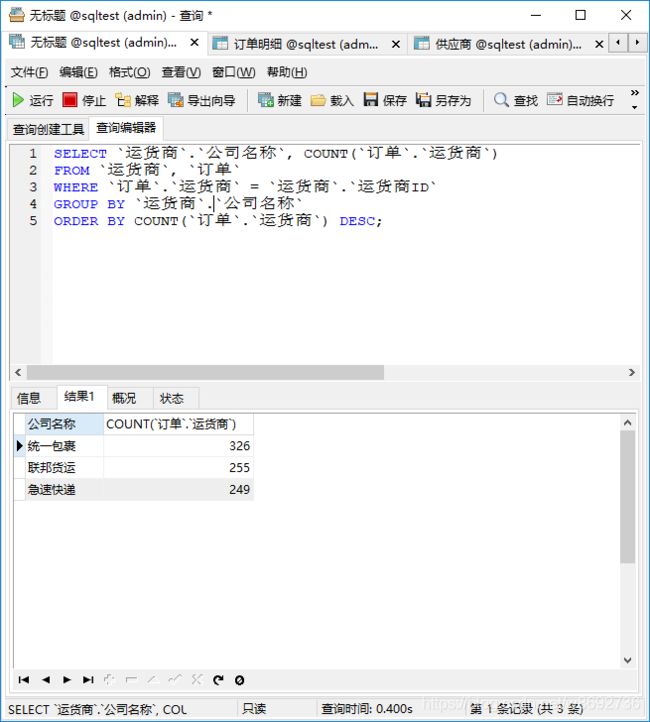
问题:找出所有的订单中运货次数最多的运货商。 已知“订单”表中含有运货商ID这一项,所以我们首先需要求出运货商ID在“订单”表中出现的次数,然后对次数进行降序排序,最后使用 “LIMIT” 字段保留第一条数据,就能找出我们的答案了。
SELECT `运货商`.`公司名称`, COUNT(`订单`.`运货商`)
FROM `运货商`, `订单`
WHERE `订单`.`运货商` = `运货商`.`运货商ID`
GROUP BY `运货商`.`公司名称`
ORDER BY COUNT(`订单`.`运货商`) DESC LIMIT 1;
结果如下(这里还没加上LIMIT,补上就好):
六、多表联立查询
问题:查询哪些产品的年度销售额低于2000。 简单的一句话却暗藏杀机,目前我们已知有“产品”、“订单”、“订单细则”三张表,其中“订单”表中有我们所需要的订购日期,订单细则有我们需要的单价、数量和折扣信息。
所以我的思路是这样的:首先我们先将这三张表连接成一张新表“new_table”,求出每个订单的销售额,随后再在new_table中以年份和产品ID为分组依据求同年度下每个产品的总销售额,最后用HAVING字段对分组后的数据进一步进行过滤,找出销售额低于2000的产品名单。代码如下:
SELECT new_table.`产品ID`, new_table.`产品名称`, new_table.`年份`,
SUM(new_table.`销售额`) AS '年度销售额'
FROM
(
SELECT `产品`.产品ID, `产品`.产品名称, YEAR(`订单`.订购日期) AS '年份',
(`订单明细`.`单价` * `订单明细`.`数量` * (1 - `订单明细`.`折扣`)) AS '销售额'
FROM `产品`, `订单明细`, `订单`
WHERE `订单明细`.订单ID = `订单`.订单ID AND `产品`.产品ID = `订单明细`.产品ID
) AS new_table
GROUP BY new_table.`年份`, new_table.产品ID
HAVING `年度销售额` < 2000
ORDER BY new_table.产品ID ASC;

现在我在想的是我们能不能直接通过一个SELECT语句就求出我们想要的结果,目前我还没想到好的方案,希望各位有识之士能在评论区中指点迷津。
七、求余运算
SQL语句中没有求余运算符“%”,只有一个求余函数MOD(N, M),即求N除以M的余数。
问题:查询所有订单中月份不是单数的订单
SELECT `订单`.`订单ID`, `订单`.`订购日期` FROM `订单`
WHERE (MOD(MONTH(`订单`.`订购日期`), 2) = 1);
八、查询结果合并
在SQL语法中,我们可以通过 “UNION” 字段将两个SELECT语句的结果集合并成一个。当然,这样的操作有着诸多限制:首先,使用UNION联合的两个结果集A和B必须拥有相同数量的列,且这些列的顺序和类型也必须完全一致;其次,由UNION联合起来的新集合C,其列名将会与第一个SELECT语句中的列名一致。
UNION默认是不允许有重复值的,如果想要查看重复值,我们可以使用“UNION ALL”。
问题:分别各写一个查询,得到订单中折扣为15%,20%的所有订单,并将两个查询再组成一个。 订单细则表中就有折扣信息,所以直接写两个SELECT查询,然后用UNION连接起来即可。
SELECT 订单明细.`订单ID`, 订单明细.`折扣` FROM 订单明细
WHERE (ABS(订单明细.`折扣` - 0.2)) < 1e-5
UNION
SELECT 订单明细.`订单ID`, 订单明细.`折扣` FROM 订单明细
WHERE (ABS(订单明细.`折扣` - 0.15)) < 1e-5
ORDER BY 订单ID;
在这里有一个细节,由于折扣信息是float型,在比对的时候,如果直接使用“折扣 < 0.2”之类的语句我们是得不到结果的,因为在系统中这些小数后面往往都有些许误差。日常中因为用不到太高精度的数据,所以我习惯用int型存储数据,然后读取出来的时候除以100求得小数,或者是另起一个新字段用于表示精度。但在这里我们被强制要求使用float型进行比较,所以必须换个其他方法。
经过一番探索后我在网上找到了一个很有意思的小操作:先将原始数据与要比对的数字做减法得到系统误差,然后取误差得绝对值与一个极小的数字进行比对,如果小于这个极小数,我们就认定这两个数相等。这么做有个好处,我们可以通过控制极小数的大小来调整比较精度,很巧妙。原文在此:Mysql float类型where 语句判断相等问题