【并发编程】深入理解——阻塞/非阻塞、同步/异步、并发/并行的概念
文章目录
- 1. 并发与并行
- 2. 阻塞与非阻塞
- 3. 同步与异步
- 4. 并发编程的实现方式
- Java NIO
- Python 协程(coroutine)
- Python async/await
- 5. 总结
1. 并发与并行
并发:concurrency 并行:parallelism
开发过程中,常常会接触并发有关的概念,比如并发计算(concurrent computing),并发系统( concurrent system),并发控制(concurrent control),并发编程(concurrent programming),那么并发到底是什么呢?
可以简单的理解为:同时做多件事情的能力!

一个人边走、边唱、边想,这就是并发;反之,要是先走、再唱、再想,就是顺序(sequentially )执行,不是并发。再比如 Web 服务器,如 Apache,nginx,能够同时处理多个客户端连接,就是并发处理。
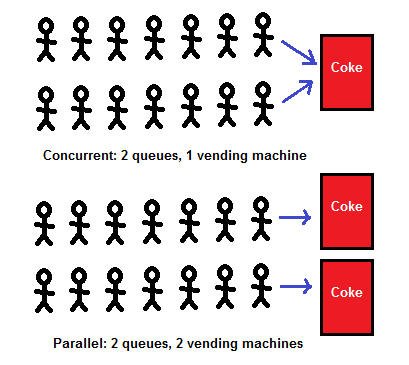
并发与并行是两个相关(related)但不同(distinct)的概念,都是“同时做多件事”,但并发关注的点是多件事被同时(一段时期)做,但只有一件事情正在执行(单核)!而并行关注的点是多个“人”在同时做事情。比如单核系统(time-sharing)能实现并发处理,但只有多核系统才能实现并行处理。
2. 阻塞与非阻塞
阻塞就是等待任务结束,在此期间,什么也不干!非阻塞就是不等待任务结束,继续做后面的事!
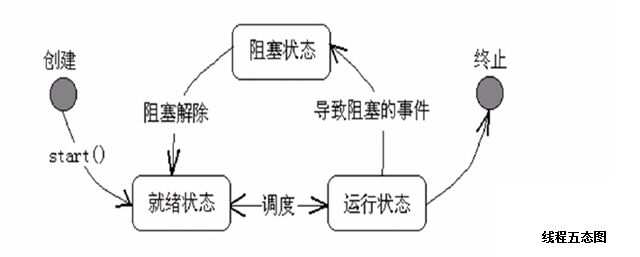
比如,快递员把快递送到小区门口,打电话给客户,等他到小区门口把快递拿走,再送下一件快递,这就是阻塞模式;快递员把快递放在小区的快递箱中,给客户发了短信,就送其它快递了,这就是非阻塞模式。
常见的阻塞形式有,网络阻塞,磁盘读写阻塞等。
Unix环境下有5中IO模型:
- 阻塞IO模型:阻塞等待
- 非阻塞IO模型:轮询,EWOULDBLOCK
- IO复用模型: select/epoll,Java NIO
- 信号驱动IO模型:回调函数,ajax
- 异步IO模型:异步函数,node.js,tornado(python)

3. 同步与异步
同步:synchronous 异步:asynchronous
同步是什么?为什么要同步?
同步就是让多个任务在某一阶段顺序执行,是并发控制的一种方式,目的是保证数据的正确性,完整性,一致性!比如数据库中的事务机制,并发编程中的锁,信号量,条件变量等,都是实现同步的工具。
只有在并发系统中,涉及到共享数据的访问时,才需要考虑同步问题!但是实际开发中,常常会遇到一些非必要的同步,比如 write 100M 的数据,或者建立数据连接,都是“去同步化”的目标,就需要考虑使用异步编程了。
异步就是让顺序执行的任务并发执行,那些根本不涉及共享数据访问、逻辑独立的任务,异步执行更高效!
4. 并发编程的实现方式
并发,就是同时做多件事情,所以多线程可以实现并发,单线程同样可以实现并发。
同理,异步编程可以基于多线程,也可以基于单线程。
1 系统层面: 进程(Process),线程(Thread)
现代操作系统 Unix/Linux/Windows 都是支持“多任务”的操作系统,为并发编程提供了不同的任务模型——进程,线程,程序员可以借助多线程+多进程来实现并发编程。
线程是最小的执行单元,而进程由至少一个线程组成,线程/进程调度,如何时执行,执行多久,由操作系统来决定。数据共享和并发控制是多线程/多进程编程时面临的重要挑战,增加了编程的复杂度;另外,频繁的上下文切换,也会影响 CPU 的使用效率。
为了减少线程切换,会使用线程池来管理线程。
2 语言层面: Channel,Coroutine,Futures and Promises
并发编程的灵活度会极大的影响一门编程语言的表现力,比如 Python 中的协程、async/wait,C# 中的 Task,async/wait,Go 中的 Channel。
另外 future, promise, delay, deferred 也是编程语言中并发编程模型相关的术语。
Java NIO
Future
AsynchronousFileChannel channel = AsynchronousFileChannel.open("bigdata.csv");
ByteBuffer buffer = ByteBuffer.allocate(1024);
Future<Integer> future = channel.read(buffer,0);
// do something else
Integer readNumber = future.get();
Callback
AsynchronousFileChannel channel = AsynchronousFileChannel.open("bigdata.csv");
ByteBuffer buffer = ByteBuffer.allocate(1024);
channel.read(buffer, 0, buffer, new CompletionHandler<Integer, ByteBuffer>() {
@Override
public void completed(Integer result, ByteBuffer attachment) {
// data process
}
@Override
public void failed(Throwable exc, ByteBuffer attachment) {
System.out.println("read error");
}
});
// do something else
Python 协程(coroutine)
函数调用是通过调用栈来实现的,有一个入口,有一个返回值,调用顺序是明确的。但是协程不同,协程允许先中断、并跳转到其它地方执行,并在适当的时候返回来继续执行。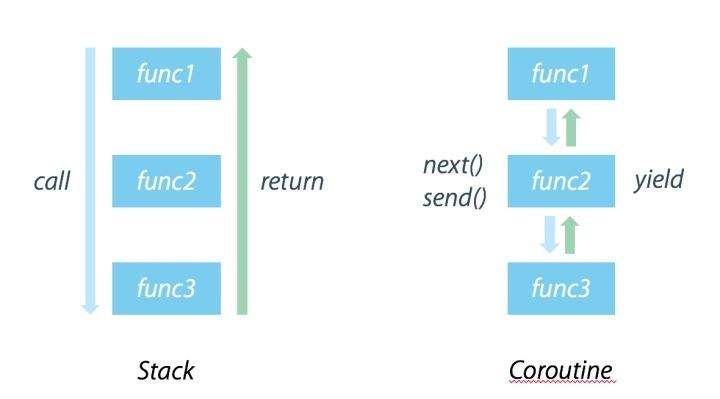
协程能向多线程一样并发执行,但是避免了线程切换,所以执行效率很高。另外,因为协程之间是同步执行了,不需要像多线程编程那样进行并发控制,不需要加锁,所以比多线程编程简单。
def consumer():
r = ''
while True:
n = yield r
if not n:
return
print("[CONSUMER] Consuming %s " % n)
r = '200 OK'
def produce(c):
c.send(None)
n = 0
while n < 5:
n = n + 1
print("[PRODUCER] Producing %s " % n)
r = c.send(n) # call generator
print("[PRODUCER] Consumer return: %s" % r)
c.close()
c = consumer()
produce(c)
python 通过 generator 实现协程:
input = yield output
在 generator 中,通过 yield 返回 output,然后程序跳转到 generator 的调用点执行,当再次调用 generator 的 send 方法时,程序跳转到 generator 中,接收 input 并继续执行。
Python async/await
从 Python 3.5 开始引入了新的语法 async 和 await,可以让 coroutine 的代码更简洁易读。
import asyncio as aio
async def hello():
print("Hello World")
r = await asyncio.sleep(100) # 耗时 io
print("Hello again!")
loop = aio.get_event_loop()
tasks = [hello(), hello()] # 初始化任务(其实就是创建 coroutine 对应的 generator)
loop.run_until_complete(aio.wait(tasks))
loop.close()
5. 总结
首先,好的程序应该能充分利用有限的 CPU 资源,努力提高资源利用率,该需求可以通过多线程/多进程来实现。
可是,线程/进程是稀缺资源,数量有限,且线程/进程上下文切换成本高。程序中的线程越多,上下文切换的成本越高,CPU 有效利用率越低!另外,在多线程/多进程模型中,需要考虑并发控制的问题,增加了编程的复杂度。
那么如何实现不依赖多线程/多进程的并发编程呢?此时,异步编程就应运而生了!
一方面,异步/非租塞通过减少对线程/进程的依赖,提高了 CPU 资源的有效利用率,同时避免了多线程/多进程中并发控制的问题;另一方面,异步编程可以降低编程的复杂度。