LSTM源码分析
http://blog.csdn.net/u011274209/article/details/53329082
代码来源:LSTM Networks for Sentiment Analysis
folk添加了注释
结合这篇文章阅读:Theano:LSTM源码解析
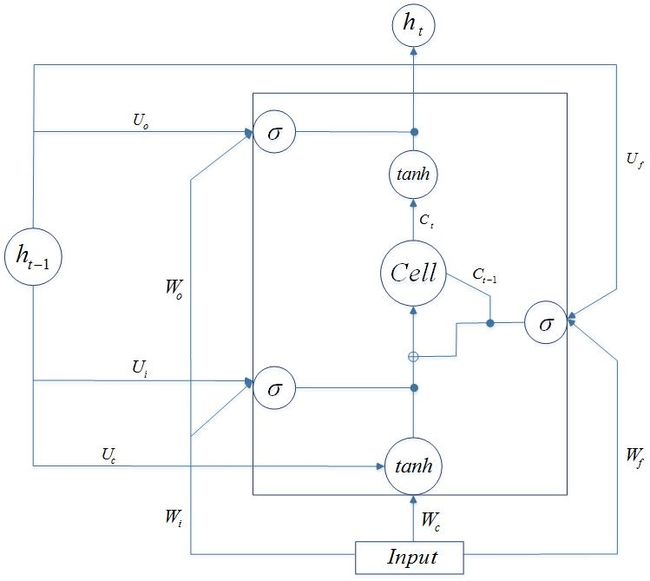
LSTM模型图
数据集:
数据集来自Stanford,数据是源自IMDB,互联网电影资料库(Internet Movie Database,简称IMDB)。IMDB数据集被Bengio组用pickle打包了imdb.pkl。情感分析的X,是数据的评论,而作为情感分析的Y,是评分与否(值只有0和1)。这个情感分析就是一个二元分类。
pickle序列号的格式:
train[0]是一个矩阵,这个矩阵就是压缩的向量空间模型,第一维(行)是所有句子,也就是数据集里的评论。每一行就是一个句子。第二维(列)是句子里的词汇,准确来说,是词汇的索引,索引表在这dict。
train[1]是01的数组,数组的数量就是评论句子数量。
test的格式相同,然后作者把train分离出一个验证集。此外在代码imdb.py里有一些预处理,在这里便不赘述。
模型构建:
代码里使用了SGD进行训练,每一个句子就是一个样本,多个句子组合在一起,形成一个minibatch。
在代码里,batch大小为n_sample,batch里句子的最大长度为n_timesteps,投射维度为dim_proj,总词汇数为n_words,最后输出的分类数为ydim(这里ydim为2,二元情感分析)。
各参数的维度如下:
这里的乘以4,是因为总共有3个gate和1个cell,线性部分都是一致的(其中省去了Peephole),作者把这几个并在一起,利用numpy的矩阵运算(更准确来说,是theano重新写的,只是函数名和用法相同),达到同时计算的目的。
各参数的初始化方法:
lstm_W/lstm_U :
生成一个dim_proj * dim_proj维大小的矩阵,元素都是服从均值为0 方差为1的高斯分布的随机数。然后对该矩阵进行svd分解,取第一个矩阵作为参数初始化。原因见:为什么 LSTM 在参数初始化时要使用 SVD 方法使参数正交?
lstm_b/b :初始化为0。
U :服从均值为0 方差为1的高斯分布的随机数乘上0.01。
Wemb :服从0到1之间的均匀分布。
函数剖析:
def init_params(options):
def param_init_lstm(options, params, prefix='lstm'):
def init_tparams(params): 这三个函数,分别初始化上面的几个参数,包括了Word Embedding,输出层的参数 U 、 b ,lstm层的参数 lstm_W , lstm_U , lstm_b 。后者这几个参数,作者使用了numpy.concatenate([list], axis=1)对第二维(也就是列)拼起来,向量化达到了lstm各个门之间并行运算。原因是:我们可以看到3个gate和1个cell 的计算公式里,都有这样的一个类似的部分 (Wxxt+bx)+Uxht−1 (下标x可以替换成i、f、o、c任意一个),前者是从input输入而来,而后者由上一个t-1时刻循环传递回来(这也是为什么lstm被称为RNN的变种)。
最后init_tparams将上述所有参数转换为theano的shared变量,存到显存里。
def lstm_layer(tparams, state_below, options, prefix='lstm', mask=None): 这是lstm层的构建的代码。state_below就是下面会讲到的emb,3维的张量(n_timesteps * n_samples * dim_proj)
1. state_below = (tensor.dot(state_below, tparams[_p(prefix, 'W')]) + tparams[_p(prefix, 'b')]) 这里是一个3维的张量点乘2维的矩阵,计算 (三个gate和一个cell的x部分)特别的,state_below是n_timesteps * n_samples * dim_proj,W是dim_proj * (dim_proj * 4),最后得到维度为n_timesteps * n_samples * (dim_proj * 4)。b维度(dim_proj*4) ,broadcast广播机制的存在,使得所有的样本都会加上b。这时state_below维数不是n_timesteps * n_samples * dim_proj,而是n_timesteps * n_samples * (dim_proj * 4)。阅读的过程中,我很好奇作者为什么要用同一个名称代表不同两个东西,我自己写TransE的代码时候,其实也干过这种破事。
2. 将_step函数传入theano的scan函数。mask, state_below,tensor.alloc(numpy_floatX(0.), n_samples, dim_proj), tensor.alloc(numpy_floatX(0.), n_samples, dim_proj)四个,分别代表m_, x_, h_, c_。在作者的命名里,X_代表变量X的上一个时序状态。h_是上一个时刻lstm层的输出,c_是上一时刻cell的值。维度均为n_samples * dim_proj,初始化为0。特别的,两个参数都没变成shared变量,估计是作者认为只需要记住一次就可以。
3. scan函数会对sequences、outputs_info的第一维(也就是行)进行循环处理。从上文可以知道,行数就是句子里的单词数,句子里有多少个词(取batch里最长的句子),就scan多少。如图:
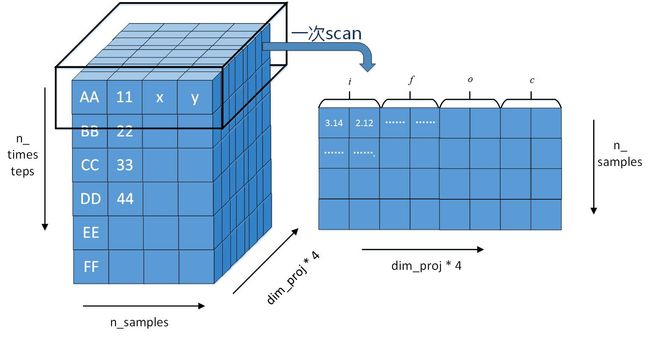
4. Python的嵌套子函数_step。preact计算的结果就是公共部分 (Wxxt+bx)+Uxht−1 。然后分别对三个gate和一个cell(i、f、o、c)分别计算其激活函数。紧接着c = f * c_ + i * c 更新cell的值,这里参照原文,使用了元素相乘,cell的维度不变。
5. 最后返回scan的第一个返回值(没有shared第二个也用不到)的第一个元素(第一个元素是h,第二个元素是c)。scan会把所有迭代叠在一起。也就是h矩阵最后在scan里是h张量。我们上文知道,迭代是对句子长度迭代,也就是每一切片就是一个单词。最后的rval[0]的维度是n_timesteps * n_samples * dim_proj。
def build_model(tparams, options): 这个函数的作用如其名,构建模型,构建最终使用的cost函数。
1. 作者定义了几个Tensor变量,x,mask,y。
2. emb = tparams['Wemb'][x.flatten()].reshape([n_timesteps, n_samples, options['dim_proj']]),x是一个矩阵,行是句子数也就是样本数(batch大小),flatten()之后,变成一个索引的列表,将Wemb里所对应的词向量取出来。得到emb是一个3维张量。
3. 将emb输入到lstm_layer函数里得到rval[0],这时候是一个3维张量。
4. 对这个结果进行Mean Pooling,就是对一句话的所有词汇所生成的各个h,进行加权平均(这种做法只是作者参考word2vec源码如此做的,也可以用别的方法汇集在一起,比如利用attention-based model《Attention-based LSTM for Aspect-level Sentiment Classification》EMNLP2016)。
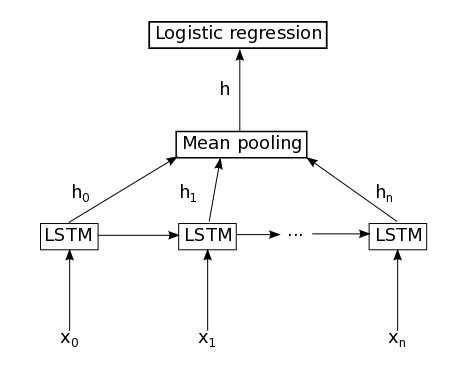

5. Dropout处理和offset(避免出现0)
6. 最后利用上面的参数 U 、 b 做了个softmax输出层,进行了分类(在这里二元其实就是逻辑斯谛)。