决策树之ID3
决策树之ID3
本系列分享由三篇博客组成,建议从前往后阅读学习。
决策树之ID3
决策树之C4.5
决策树之CART
0.引言
这几天整理了决策树的发展历程,分享给大家,方便大家进行学习。
决策树的发展历程为见下图:

决策树有几个关键性的阶段,分别是ID3,C4.5,CART。在决策树模型逐渐成熟之后被应用于随机森林、Adaboost等算法中,因此决策树是下边这几种算法的基础。
决策树是一种有监督的机器学习算法。最终生成的树(模型)服从比较简单的规律:如果****并且****那么结果为****。
下图为一个简单的决策树:

这只是一个不恰当的例子而已,仅仅是让我们更好的去理解什么是决策数树。根据这个决策树模型,我们就可以根据一个人头发的长度来初步判断他性别是男是女。
这只是我们对决策树的一个非常浅的一种理解方式,要想深入理解决策树,必须搞清楚决策树的内在机理,也就是决策树它是怎么样生成的。这涉及到:决策树的生成原理、过拟合问题的解决。
1.决策树的生成原理
在决策树比较早的ID3算法中每个特征的特征值均是离散的。
决策树每次分枝时,根据“减少不确定性的多少”来进行分类。假设有两个特征,分别是A和B,如果“用A特征分类减少的不确定性”大于“用B特征分类减少的不确定性”,那么这次分枝选用A特征作为分枝的依据。
说了这么一大堆,怎么就算不确定,怎么算确定呢?假如上面决策树中的子结点都为“男:5,女:5”,那么就没有足够的把握判断这个结点的样本是男还是女,也就是这个结点充满了不确定性。假如决策树的子结点分别为“男:0,女:10”和“男:10,女:0”,那么我们有充分的把握判断第一个结点的样本性别为女,第二个结点的样本性别为男,并没有什么不确定性。
那么怎么定量的描述不确定性和不确定性的减少量呢?这里需要我们补充一下关于熵的一系列概念。
1.1 概念补充
- 信息量
如果一件事发生的概率比较大,则这件事发生之后产生的信息量比较小;如果一件事发生的概率比较小,则这件事发生之后产生的信息量比较大。
举个例子:A事件是中国获得了世界杯冠军。B事件是中国没有获得世界杯冠军。假设A事件发生了,第一反应是特别惊奇,要赶快发一个朋友圈,把这个激动人心的消息告诉大家。假设B事件发生,第一反应....不,没有第一反应,心里会想:你不告诉我我也知道中国不会拿世界杯冠军(这里没有任何黑中国队的意思)。很明显,A事件的信息量大,B事件几乎没有信息量。信息量的表达式为:
![]()
其中 是结果集
是结果集 中第
中第 个离散值,上式
个离散值,上式![]() 表示发生的信息量,下图为
表示发生的信息量,下图为![]() 随
随![]() 变化的曲线:
变化的曲线:

- 熵
熵是信息量的平均值。信息量的均值越大,不确定性越大,即熵越大,不确定性越大,因此熵表示一个集合的结果的不确定程度,也可以理解为还可以从这个集合中获取多少信息。熵的表达式如下:

我们还是看上图男女的例子。我们一起来计算根结点“男:10,女:10”的熵。
 表示数据集。
表示数据集。
![]()
![]()
![]()
-
条件熵
条件熵表示一个集合经过特征 进行分类后,各个类的熵的加权平均,表达式为:
进行分类后,各个类的熵的加权平均,表达式为:

在上个例子中:
![]()
![]()

![]()
![]()
- 信息增益
信息增益是集合从一个状态转换到另一个状态之后(对应例子就是20个人被分类之后),不确定性的减少量,即熵的减少量,也就是状态转化过程中多掌握的信息的量,下面是信息增益的表达式:
![]()
掌握了有关熵和信息增益的概念之后,我们知道了可以用信息增益来衡量不确定性的减少量。分别用多个特征进行分类,计算用各个特征分类后的信息增益,比较信息增益的大小,选出信息增益最大的特征作为当前结点的分类特征。
了解了决策树是分枝原理之后我们再来看看决策树构建的整个过程,我们需要了解决策树ID3算法的步骤。
1.2 ID3算法流程
1)初始化信息增益的阈值 。
。
2)判断样本是否为同一类输出 ,如果是则返回单节点树
,如果是则返回单节点树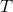 。标记类别为。
。标记类别为。
3) 判断特征是否为空,如果是则返回单节点树,标记类别为样本中输出类别实例数最多的类别。
4)计算 中的各个特征(一共
中的各个特征(一共 个)对输出D的信息增益,选择信息增益最大的特征
个)对输出D的信息增益,选择信息增益最大的特征 。
。
5) 如果的信息增益小于阈值,则返回单节点树,标记类别为样本中输出类别实例数最多的类别。
6)否则,按特征的不同取值![]() 将对应的样本输出分成不同的类别。每个类别产生一个子节点。对应特征值为
将对应的样本输出分成不同的类别。每个类别产生一个子节点。对应特征值为![]() 。返回增加了节点的数。
。返回增加了节点的数。
7)对于所有的子节点,令![]() , 递归调用2-6步,得到子树
, 递归调用2-6步,得到子树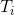 并返回。
并返回。
2.过拟合问题的解决
在ID3中,解决过拟合问题的机制只有一种,那就是通过改变信息增益的阈值。
在后面的C4.5算法中,将会讲到通过剪枝的方法来减少过拟合的情况。
3.ID3的缺陷
1)ID3算法只能解决特征值是离散的问题,当特征值是连续值时将无能为力。
2)同样ID3算法只讨论了输出为离散值的问题,输出值为离散值时则无能为力。(只能做分类,不能做回归)
3)没有考虑存在缺失值的情况。
4)当使用信息增益来进行特征选择时,往往偏向于选择特征取值较多的特征。原因是当特征的取值较多时,根据此特征划分更容易得到纯度更高的子集,划分之后的熵更低。
5)对于过拟合问题无能为力。
以上就是我对ID3算法的理解,若有理解不到位的地方还请大家批评指正。