python 爬取《青你2》粉丝评论并分析
爬虫与语义分析
- 爬取评论
-
- 评论加载过程
- 请求链接生成规律
- 词云制作
-
- 语句清洗和提取
- 分词和云图
- 语义审核
-
- 安装过程
- 语义检测
看看都有谁出言不逊了
爬取评论
首选看看评论的加载过程。
评论加载过程
用浏览器打开网页,F12快捷键调试模式,选择Network,最后当然要刷新以下F5,鼠标随意。然后就是见证奇迹的时刻,O(∩_∩)O
- 复制一定数量的评论文本搜索以下
- 点击搜索结果在右边框中选择review就会看到满满的json格式信息(当然得去掉多余的信息)。
- 查看网络请求的方式,链接和头信息。
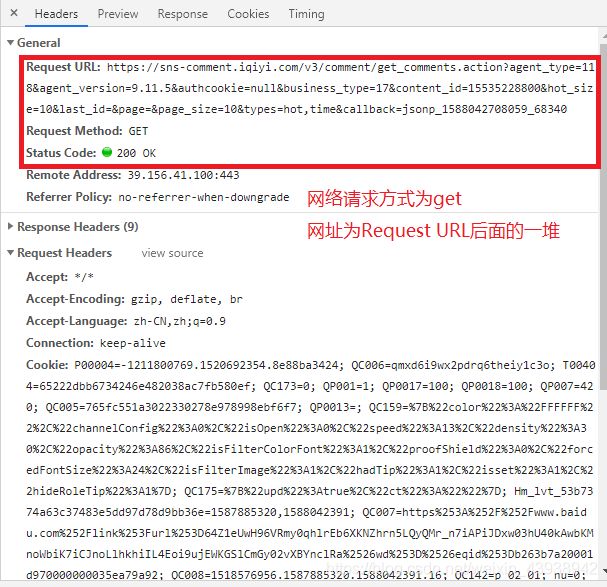
头信息为

以上我们找到了请求方式,请求链接,以及头信息,接下来,我们要分析更多的请求链接,研究以下请求链接的生成规律。
请求链接生成规律

- 图片上方为第二个链接的返回结果,其最后的rootCommentId与第三个链接中的last_id数值一样
- 链接最后jsonp后一堆数字与unit时间戳很像,转换以下,就会发现这就是我们发送请求的时间
- 最后面的几个数字我始终不知道干啥的,我用了最简单粗暴的方法代替——随机数
代码奉上:
# 导入必要的包
import requests
import datetime
import re
def getCritical(last_id = None):
'''
请求爱奇艺评论接口,返回response信息
参数 last_id: 用与生成请求链接
:return: response信息
'''
# 链接的开始,就是前面一大堆不变的字母数字。
urlbegin = 'https://sns-comment.iqiyi.com/v3/comment/get_comments.action?agent_type=118&agent_version=9.11.5&authcookie=null&business_type=17&content_id=15068699100&hot_size=0&last_id='
# 链接的结束,由于last_id还不清楚,先不加上,最后是当前的unit时间戳与随机数
urlend = '&page=&page_size=20&types=time&callback=jsonp_'+str(int(datetime.datetime.now().timestamp()*1000))+str(np.random.randint(1,1000000)) # 时间戳和最后的随机数
# 当last_id 不指定时,为我们第一次请求直接将第一次的内容复制进来就好,当指定了last_id这时候就需要
# 另外设置请求地址值
if last_id == None:
url = 'https://sns-comment.iqiyi.com/v3/comment/get_comments.action?agent_type=118&agent_version=9.11.5&authcookie=null\
&business_type=17&content_id=15068699100&hot_size=10&last_id=&page=&page_size=10&types=hot,time&callback=jsonp_'\
+str(int(datetime.datetime.now().timestamp()*1000))+str(np.random.randint(1,1000000))
else:
url = urlbegin+str(last_id)+urlend
# 这就是我们复制出来的那个头信息
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
# 发送请求得到返回值
response = requests.get(url,headers=headers)
return response
def saveCriticalToFile(response):
'''
获取response,提取评论和rootCommenId
参数 lastId:最后一条评论ID arr:存放文本的list
:return: 新的lastId
'''
# 正则表达式获取所有评论,把所有的字符串一锅烩了
data = re.compile(r'"content":"(.*?)"',).findall(response.content.decode(), re.S)
list = []
for i in data: # 评论去重
if i not in list:
list.append(i)
with open('critical.txt', 'a+') as f: # 写入文件存储
for i in list:
f.write(i+'\n')
rootCommentId = re.compile(r'"rootCommentId":(.*?),',).findall(response.content.decode(), re.S)
# 取出最后一个ID作为last_id返回去
return rootCommentId[-1]
if __name__ == '__main__':
last_id = None
# 爬取个200次
for i in range(200):
res = getCritical(last_id)
if res.status_code == 200:
last_id = saveCriticalToFile(res)
else:
print(res.status_code)
break
# 做个文明人,不要一股脑的请求,给服务器降低点压力
time.sleep(1)
至此,评论爬取完毕,下面就分析分析,大家的讨(si)论(bi)言论吧。
词云制作
先看看大家评(si)论(bi)最喜欢用的词语吧。
语句清洗和提取
这里暴力点,咱只要评论中的数字,字母,汉字,其他都扔掉。代码如下:
import re
def clear_special_char(file = 'critical.txt'):
'''
正则处理特殊字符
参数 file:文本路径
return: 清除后的文本
'''
# 只保留中文、大小写字母和阿拉伯数字
reg = "[^0-9A-Za-z\u4e00-\u9fa5]"
s = ''
with open(file,'r') as f:
for line in f.readlines():
s += re.sub(reg, '', line.replace('\\r',''))
return s
分词和云图
首先分词,jieba(结巴)分词包分分钟搞定
import jieba
def split_words(content, usd_file = 'work/usrdict.txt'):
'''
利用jieba进行分词
参数 content:待分词的文本 usd_file:用户自定义词语,比如名字什么,jieba无法识别的
return:分词结果
'''
# 导入用户词典
jieba.load_userdict(usd_file)
words_list = jieba.cut(content, cut_all = True)
return ' '.join(words_list)
分词完了,就画个词云吧,瞅瞅大家的词汇量。
from wordcloud import WordCloud
from PIL import Image
import numpy as np
def drawcloud(content,stopwords):
'''
根据词频绘制词云图
参数 content:分词好的字符串 stopwords:不想看到的词语
return:none
'''
# 支持中文显示的字体
FONT = 'simhei.ttf'
# 可以用以白底的照片形成轮廓照片
background = np.array(Image.open('123.jpg'))
wc = WordCloud(background_color="white",
mask=background,
stopwords=stopwords,
font_path=FONT)
wc.generate(content)
# 将词云图片保存下来
wc.to_file('younth_is_you.png')
if __name__ == '__main__':
content = clear_special_char()
content = split_words(content)
stopwords = ['的','是','那么'] # 不想出现的词放进去
drawcloud(content,stopwords)
结果:

大家还很激进呀,动不动就 所有人,梭哈了O(∩_∩)O
语义审核
这里使用以下PaddleHub的语义审核与训练数据,直接进行预测
安装过程
可以直接使用
pip install paddlehub
进行安装,另外更加详细的安装步骤
下面再下载以下相关模型,模型说明地址
这里有三个模型可以使用随便下载一个就可以
这里试一试lstm模型
hub install porn_detection_lstm
语义检测
使用方法
from __future__ import print_function
import json
import six
import paddlehub as hub
if __name__ == "__main__":
# Load porn_detection_lstm module
porn_detection_lstm = hub.Module(name="porn_detection_lstm")
test_text = []
with open(file_path,'r') as f:
for line in f.readlines():
test_text.append(line)
input_dict = {
"text": test_text}
results = porn_detection_lstm.detection(data=input_dict,use_gpu=True, batch_size=1)
for index, text in enumerate(test_text):
results[index]["text"] = text
for index, result in enumerate(results):
if six.PY2:
# 只有预测结果超过0.8时打印文本和预测结果
if results[index]['porn_probs'] > 0.8:
print(results[index]['text'],"\n:",results[index]['porn_probs'])
else:
if results[index]['porn_probs'] > 0.8:
print(results[index]['text'],"\n:",results[index]['porn_probs'])
其检测返回结果格式为:
[{
'text': '朴志训第一??你他妈在逗我。。是姜丹尼尔好吧',
'porn_detection_label': 1,
'porn_detection_key': 'porn',
'porn_probs': 0.9748,
'not_porn_probs': 0.0252},
以后可不敢明目张胆的骂人了,电脑随便分析以下就发现,你素质低下了。