(原创)反爬虫策略对抗实战(一)——绕过网页请求认证
前日同组的同事联系我帮他查看一个网站,该网站的数据保护相对严格,难以直接使用scrapy或者requests等爬虫工具直接进行爬取。
待爬取的网站和内容
待爬取的网站:https://software.cisco.com/download/home?from=singlemessage&isappinstalled=0

该网站是Cisco的路由器和其他网络设备固件下载的官方网站,待爬取的内容则是该网站上包含的固件的品牌,类别等信息。
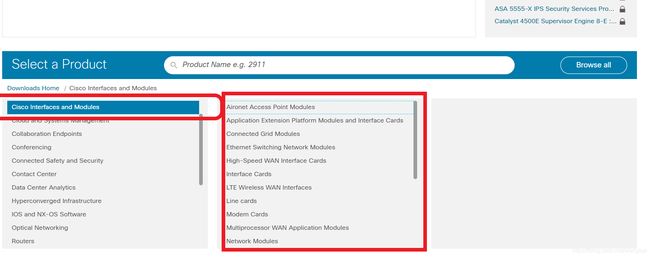
点击红色框中的browse all按钮,可以加载待爬取的数据。这一部分是使用JS脚本来在前端进行实现。
通过浏览器F12工具,可以找到这部分数据加载的API:

然而,该API有两个请求参数,如果直接访问该API,则会返回403错误。
网站的数据保护措施
1)要求用户点击之后才会展示被保护数据
2)采用js生成页面而不是直接使用html对页面进行构建
3)通过对后台restful接口的认证控制来进行访问控制
PhantomJS的缺点
大多数爬虫开发工程师会选择使用PhantomJS作为浏览器JS执行引擎,通过浏览器JS执行来进行页面的构建。并使用selenium来进行用户操作的模拟。
但是这种方法存在两个明显的不足之处
1)JS执行引擎需要将页面上的JS脚本执行完毕并构建出完整页面之后才可以使用selenium进行元素选取,执行效率较低。
2)部分网站(例如境外网站)或者部分资源存在响应时间过长而导致网页加载速度很低,甚至出现网页加载卡死的状况。
通过模拟浏览器请求绕过身份认证
requests是一个轻量级的HTTP访问库。可以用十分方便的方法构造HTTP请求。
通过该请求的分析,发现该请求包括两个参数,ts和mdfid
https://api.cisco.com/software/services/catalog/v1/products?
mdfid=268437593 &
ts=CV0KQXGNL3HHXKKUQTT1555403016378
与此同时,发现其请求头中包含了一个认证相关的字段Authorization。
Accept: application/json, text/plain, */*
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9
#Authorization这个字段是和访问认证相关的字段
Authorization: Bearer 9FVz6wKBXM0lr1CHYCvyUm2NjW98
Connection: keep-alive
Host: api.cisco.com
Origin: https://software.cisco.com
Referer: https://software.cisco.com/download/home?from=singlemessage&isappinstalled=0
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.75 Safari/537.36
可以猜想该认证是否和这些内容有关。
对页面的HTML源代码进行分析,可以看到其第38行到第45行的JavaScript脚本中包含如下内容:
<script>
var env = "prod";
var dc = "alln";
var ts = "L26T680DL0XIHNKQHKT1555404396261";
var locale = "zh_CN";
var authuser = "";
var tkn = "LayATQ0pWwvmRv2OY84jDRjPB3a9";
</script>
其中直接包含了ts字段和tkn字段,ts字段就是url请求中的ts参数。而tkn字段中的字符串恰好就是请求头Authorization字段中所需要的内容。
接下来就可以通过requests库来伪造浏览器请求了
# -*- coding=utf-8 -*-
import requests
from lxml import etree
import re
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.75 Safari/537.36'
}
res=requests.get("https://software.cisco.com/download/home?from=singlemessage&isappinstalled=0",headers=headers)
res_xml = etree.HTML(res.content)
JS_content = res_xml.xpath("//script/text()")[2]
#通过lxml获取包含ts和tkn字段的JS脚本内容
ts = re.findall('"[a-z|A-Z|0-9]{32}"',JS_content)
tkn = re.findall('"[a-z|A-Z|0-9]{28}"',JS_content)
#通过正则表达式获取ts和tkn的内容
print ts
print tkn
#更新headers,针对待爬取的内容重新发送请求
headers['Authorization'] = 'Bearer '+tkn[0][1:-1]
res=requests.get("https://api.cisco.com/software/services/catalog/v1/products?mdfid=268437593& \
ts=" + ts[0][1:-1],headers=headers)
print res.content
运行该脚本,可以顺利输出待爬取的restfulAPI返回的json文件。
总结
爬虫技术的本质,就是让网站无法分辨一个请求是人为的还是爬虫伪造的。因此面对反爬虫策略,我们要做的就是通过经验或者手动实验,确认该网站是如何做到判断请求来源,并通过技术手段让其“失灵”,从而实现对我们想要的数据的爬取。