Faster R-cnn :训练自己的数据集 caffe/python/windows 过程记录
成功版本在这:https://blog.csdn.net/weixin_38715903/article/details/81077326
一、制作自己的数据集:为了方便直接新建与VOC2007一样名称的文件夹
VOC2007文件夹中包含:

1.Annotations中包含:

.xml文件是由labellmg.exe标定ground truth后生成的文件:

2.ImageSets中包含:--ImageSets--Main--test、train、val、trainval.txt


有一个简单的生成TXT的代码:
import os
import random
trainval_percent = 0.66
train_percent = 0.5
xmlfilepath = 'C:\\Users\\Admin\\Desktop\\VOC2007\\Annotations'
txtsavepath = 'C:\\Users\\Admin\\Desktop\\VOC2007\\ImageSets\\Main'
total_xml = os.listdir(xmlfilepath)
num=len(total_xml)
list=range(num)
tv=int(num*trainval_percent)
tr=int(tv*train_percent)
trainval= random.sample(list,tv)
train=random.sample(trainval,tr)
ftrainval = open('C:\\Users\\Admin\\Desktop\\VOC2007\\ImageSets\\Main\\trainval.txt', 'w')
ftest=open('C:\\Users\\Admin\\Desktop\\VOC2007\\ImageSets\\Main\\test.txt', 'w')
ftrain = open('C:\\Users\\Admin\\Desktop\\VOC2007\\ImageSets\\Main\\train.txt', 'w')
fval = open('C:\\Users\\Admin\\Desktop\\VOC2007\\ImageSets\\Main\\val.txt', 'w')
for i in list:
name=total_xml[i][:-4]+'\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest .close() 3.JPEGImages中的内容:图片名称应该与VOC2007相同,是6位顺序数

至此数据集创建完成,将VOC2007文件夹放到..\py-faster-rcnn-master\data\VOCdevkit2007文件中,VOCdevkit2007没有的话自己新建一个就好。
二、修改prototxt文件
prototxt文件在models文件夹下:..\py-faster-rcnn-master\models\pascal_voc\VGG16,我选择的是faster_rcnn_end2end,为了不影响原有的文件,我新建了一个文件夹faster_rcnn_end2end_boat,然后将faster_rcnn_end2end中的3个prototxt文件复制到新建的文件夹中去,并按如下方式更改。
1.train.prototxt:
input-data:n

roi-data:n

cls_score:n(我这里是因为出现了问题3,所以将层重新命名了)
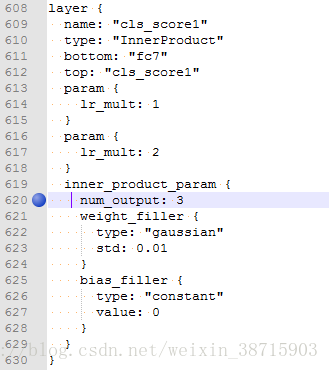
bbox_pred:n*4(我这里是因为出现了问题3,所以将层重新命名了)

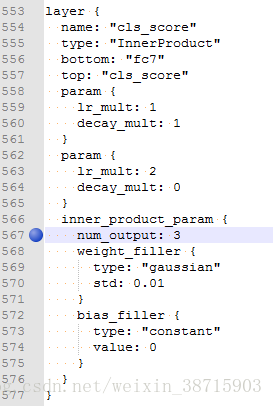
2.test.propotxt:
cls_score:n
bbox_pred:n*4
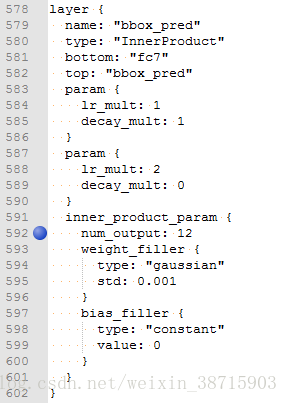
3.solve.propotxt

至此,所有prototxt文件更改完毕。
三、更改代码:..\py-faster-rcnn-master\lib\datasets文件夹下的代码
1.pascal_voc.py:
class pascal_voc(imdb):
def __init__(self, image_set, year, devkit_path=None):
imdb.__init__(self, 'voc_' + year + '_' + image_set)
self._year = year
self._image_set = image_set
self._devkit_path = self._get_default_path() if devkit_path is None \
else devkit_path
self._data_path = os.path.join(self._devkit_path, 'VOC' + self._year)
self._classes = ('__background__', # always index 0
'你的标签1','你的标签2',你的标签3','你的标签4'
) #需要更改的地方改成自己要的类别,小写字母2.imdb.py:
def append_flipped_images(self):
num_images = self.num_images
widths = [PIL.Image.open(self.image_path_at(i)).size[0]
for i in xrange(num_images)] #更改的部分
for i in range(num_images):
boxes = self.roidb[i]['boxes'].copy()
oldx1 = boxes[:, 0].copy()
oldx2 = boxes[:, 2].copy()
print boxes[:, 0]
print boxes[:, 0]
assert (boxes[:, 2] >= boxes[:, 0]).all()
entry = {'boxes' : boxes,
'gt_overlaps' : self.roidb[i]['gt_overlaps'],
'gt_classes' : self.roidb[i]['gt_classes'],
'flipped' : True}
self.roidb.append(entry)
self._image_index = self._image_index * 2 还要把py-faster-rcnn/data/cache中的文件和py-faster-rcnn/data/VOCdevkit2007/annotations_cache中的文件删除(如果有的话)。
四、开始训练
1.训练格式:
./tools/train_net.py --gpu 0 --solver path/to/solver.prototxt --weights path/to/pretrain_model --imdb voc_2007_trainval --iters 100000 --cfgs experiments/cfgs/faster_rcnn_end2end.yml我自己:train.bat
.\tools\train_net.py --gpu 0 --solver .\models\pascal_voc\VGG16\faster_rcnn_end2end_boat\solver.prototxt --weights .\data\faster_rcnn_models\VGG16_faster_rcnn_final.caffemodel --imdb voc_2007_trainval --iters 100000 --cfg .\experiments\cfgs\faster_rcnn_end2end.yml2.测试格式:
./tools/test_net.py --gpu 0 --def path/to/test.prototxt --net path/to/your/final.model --imdb voc_2007_test --cfgs experiments/cfgs/faster_rcnn_end2end.yml
五、遇到的问题:
1、AttributeError: 'module' object has no attribute 'text_format'
解决方案:在 ../lib/fast_rcnn/train.py增加一行import google.protobuf.text_format
2.F0615 14:53:28.416858 4384 smooth_L1_loss_layer.cpp:24] Check failed: bottom[0] ->channels() == bottom[1]->channels() (12 vs. 84)
解决方案:一般都是end2end中的train.prototxt的类别没有改好导致的。
检查train.prototx中的input-data层的num_classes:n (自己要训练的类别+1,1代表背景)
roi-data层的num_classes:n
cls_score层的num_output:n
bbox_preda层的num_output:4*n。
3.F0615 14:58:38.421589 7596 net.cpp:757] Cannot copy param 0 weights from layer ‘cls_score’; shape mismatch. Source param shape is 21 4096 (86016); target param shape is 3 4096 (12288). To learn this layer’s parameters from scratch rather than copying from a saved net, rename the layer.
解决方法:我是在训练过程中遇到的问题,所以将train.ptototxt相应的cls_score重新命名了:cls_score1
bbox_pred层也是一样重新命名就好
六、结果
正在跑,跑完贴结果...
参考文献:
https://blog.csdn.net/sinat_30071459/article/details/51332084
https://blog.csdn.net/zhang_shuai12/article/details/52295438