python3如何随机生成大数据存储到指定excel文档里
本次主要采用的是python3的第三方库xlwt,来创建一个excel文件。具体步骤如下:
1、确认存储位置,文件命名跟随时间格式
2、封装写入格式
3、实现随机数列生成
4、定位行和列把随机数写入
5、统一写入条目数,实现入参确认条目
6、封装对文件夹内多余数据表的删除操作。
说明:最大支持60000条,这个是由于excel格式限制的,如果对大数据有更高要求的如,写入6000000数据的话可以进行循环获取到100个excel来导入。
实际文件生成效果图:
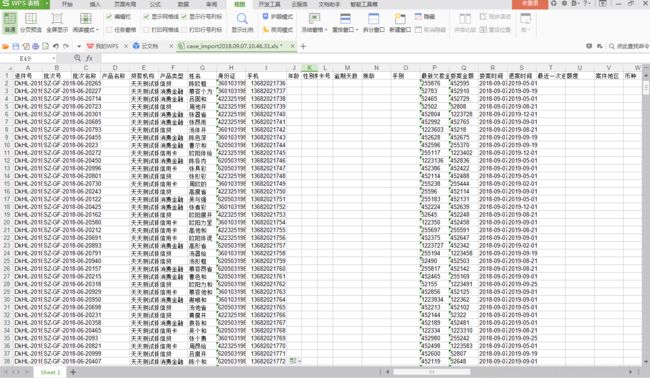
文件内容格式如下图
源码如下:
import xlrd
import xlwt
from my_framework.log import Logger
import time,os
import random
# create a logger instance
logger = Logger(logger="file_process").getlog()
class file_process():
"""封装操作excel的方法"""
# 获取某一页sheet对象
def create_excel_file(self):
da = time.strftime("%Y-%m-%d/%H-%M-%S", time.localtime())
self.da_a = str(da.split('/')[0])
self.da_b = str(da.split('/')[1])
filename = "case_import"+(self.da_a+'-'+self.da_b).replace('-','.')+".xls"
excel_path = os.path.dirname(os.path.abspath('.')) + '\config_file\case_import'
self.ecl =os.path.join(excel_path,filename)
book = xlwt.Workbook(encoding = 'utf-8')
self.sheet1 = book.add_sheet('Sheet 1',cell_overwrite_ok = True)
self.title = [u'进件号',u'批次号',u'批次名称',u'产品名称',u'贷款机构',u'产品类型',u'姓名',u'身份证',u'手机',u'年龄',u'性别'u'帐号',
u'卡号',u'逾期天数',u'账龄',u'手别' ,u'最新欠款金额',u'委案金额',u'委案时间',u'退案时间',u'最近一次进入催收日期',
u'额度',u'案件地区',u'币种',u'开户行',u'账单日',u'开卡日期',u'是否分期',u'分期情况',u'本金',u'利息',u'违约金',
u'最低还款',u'委案最低还款额',u'争议金额',u'争议后金额',u'服务费',u'超限费',u'累计还款',u'委前最后付款额',u'委前最后付款日',
u'案件备注',u'家庭地址',u'家庭电话',u'公司名称',u'公司电话',u'公司地址',u'常用地址',u'账单地址',u'邮政编码',u'其他地址',
u'QQ',u'微信',u'支付宝',u'邮箱',u'联系人1姓名',u'联系人1关系',u'联系人1电话',u'联系人2姓名',u'联系人2关系',u'联系人2电话',
u'联系人3姓名',u'联系人3关系',u'联系人3电话']
batch_code = ['SZ-GF-2018-06-20','SZ-GF-2018-06-20','SZ-GF-2018-06-20','SZ-GF-2018-06-20','SZ-GF-2018-06-20','SZ-GF-2018-06-20',
'SZ-GF-2018-06-20','SZ-GF-2018-06-20']
commit_money = ['255','452','1223','452','52']
self.commit_date = [self.da_a]
latest_debt_money = ['255','452','1223','452','52']
self.limit_date = ['2019-09-01','2019-05-01','2019-08-21','2019-02-01','2019-12-01','2019-09-25','2019-09-19',]
self.product_type = ['信贷','消费金融','信用卡']
self.borrower_idnumber = ['422325198908151539','620503198108111211','360103198904054718']
self.borrower_phone = ['13686821736']
self.loan_institution = ['天天测试银行']
self.write_data(self.title,0,line=1)#标题内容和格式写入
# 数据导入的条数
data_num = 60000
# 进件号写入
bill_code = self.create_data_billcode(data_num)#获取5个随机字符
j = self.title_local(u'进件号')
self.write_data(bill_code, j, line=0)#对第一列进行写入,写入字段存放在lrst中
#批次号写入
batch_codes = self.create_data(batch_code,data_num)
a = self.title_local(u'批次号')
self.write_data(batch_codes, a, line=0)
#委案金额写入
commit_moneys = self.create_data(commit_money, data_num)
a = self.title_local(u'委案金额')
self.write_data(commit_moneys, a, line=0)
#最新欠款金额写入
latest_debt_moneys = self.create_data(latest_debt_money, data_num)
a = self.title_local(u'最新欠款金额')
self.write_data(latest_debt_moneys, a, line=0)
#其它固定写入
commit_dates, limit_dates, product_types, borrower_idnumbers, borrower_phones, loan_institutions = self.only_create_data(data_num)
#委案时间写入
aa = self.title_local(u'委案时间')
self.write_data(commit_dates, aa, line=0)
#退案时间写入
bb = self.title_local(u'退案时间')
self.write_data(limit_dates, bb, line=0)
#产品类型写入
cc = self.title_local(u'产品类型')
self.write_data(product_types, cc, line=0)
#身份证写入
dd = self.title_local(u'身份证')
self.write_data(borrower_idnumbers, dd, line=0)
#手机号写入
ee = self.title_local(u'手机')
self.write_data(borrower_phones, ee, line=0)
#贷款机构写入
ff = self.title_local(u'贷款机构')
self.write_data(loan_institutions, ff, line=0)
#姓名写入
i = self.title_local(u'姓名')
brrower_name = self.create_data_name(data_num) # 获取5个随机字符
self.write_data(brrower_name, i, line=0)
book.save(self.ecl)
return filename
def write_data(self,lst,num,line=0):
"""
:param lst: 写入的字段内容的列表
:param num: num来控制写入的是固定第几行第几列
:param line: 判断写入的是一行还是一列
:return: none
"""
if line == 0:
for i,item in enumerate(lst):
self.sheet1.write(i+1, num, item)
else:
for i,item in enumerate(lst):
self.sheet1.write(num, i, item)
def title_local(self,str):
for i, item in enumerate(self.title):
if item == str:
return i
#进件号生成的随机算法
def create_data_billcode(self,number):
lrst=[]
la = ['SZ','PH','HW','KL','WE','TY','DH','Z','H','W','L','E','Y','Q','SZK',
'PHK','HWK','KLK','WEK','TYK','DHK','SRZ','PRH','HRW','KRL','WRE','TRY',
'DRH','SLZ','PLH','HLW','KLL','WLE','TLY','DLH','SZL','PHL','HWL','KLL','WEL','TYL','DHL'
'DRH', 'SLkZ', 'PkLH',
'HLkW', 'KLkL', 'WLkE', 'TLkY', 'DLkH', 'SkZL', 'PkHL', 'HWkL', 'KLkL', 'WEkL', 'TkYL', 'DkHL']
la1 = ['SZ', 'PH', 'HW', 'KL', 'WE', 'TY', 'DH', 'Z', 'H', 'W', 'L', 'E', 'Y', 'Q', 'SZK',
'PHK', 'HWK', 'KLK', 'WEK', 'TYK', 'DHK', 'SRZ', 'PRH', 'HRW', 'KRL', 'WRE', 'TRY',
'DRH', 'SLZ', 'PLH', 'HLW', 'KLL', 'WLE', 'TLY', 'DLH', 'SZL', 'PHL', 'HWL', 'KLL', 'WEyL', 'TyYL', 'DyHL'
,'DyRH',
'SLkZ', 'PkLH',
'HLkW', 'KLkL', 'WLkE', 'TLkY', 'DLkH', 'SkZL', 'PkHL', 'HWkL', 'KLkL', 'WEkL', 'TkYL', 'DkHL'
'SZ', 'PH', 'HW',
'K2L', 'W2E', 'T2Y', 'D2H', '2Z', '2H', '2W', '2L', '2E', '2Y', '2Q', '2SZK',
'PHK', 'HWK', 'KLK', 'WEK', 'TYK', 'DHK', 'SRZ', 'PRH', 'HRW', 'KRL', 'WRE', 'TRY',
'DRH', 'SLZ', 'PLH', 'HLW', 'KLL', 'WLE', 'TLY', 'DLH', 'SZL', 'PHL', 'HWL', 'KLL', 'WEyL', 'TyYL',
]
for a in range(1,number+1):
i = str(random.randint(0, 1000000000000))
for j in la:
jk=j
j = random.choice(la1)
ha = jk + '-' + self.da_a + '-' + i+j
lrst.append(ha)
return lrst
#姓名生成的随机算法
def create_data_name(self,number):
lrst = []
la = ['张', '周', '吴', '谢', '李', '高', '汤','曹', '陈', '欧阳', '慕容', '黄', '袁', '吕']
lb = ['具', '国', '暮', '各', '色', '形', '者','换', '与', '欧', '各', '力', '固', '体',
'为', '而', '尔', '风', '哦',
'形', '黯', '器', '个', '昂', '瘦', '力', '刻', '他']
lc = ['深', '和', '落', '省', '彩', '呈', '的','谎', '和', '妔', '给', '彩', '呈', '的',
'框', '和', '量', '为', '强',
'而', '的', '及', '和', '联', '给', '肉', '开', '费']
for a in range(1, number+1):
i = random.choice(la)
j = random.choice(lb)
k = random.choice(lc)
ha = i + j + k
lrst.append(ha)
return lrst
#其它数据生成算法
def create_data(self,la,number):
"""
:param la: 随机数列
:param number: 生成几条数据
:return: 数据写集合
"""
lrst = []
for a in range(1, number+1):
i = random.choice(la)
j = str(random.randint(0, 1000))
ha = i+j
lrst.append(ha)
return lrst
def only_create_data(self,data_num):
commit_dates = []
limit_dates = []
product_types = []
borrower_idnumbers = []
borrower_phones = []
loan_institutions = []
latest_debt_moneys = []
for b in range(1,data_num+1):
aa = random.choice(self.commit_date)
bb = random.choice(self.limit_date)
cc = random.choice(self.product_type)
dd = random.choice(self.borrower_idnumber)
ee = random.choice(self.borrower_phone)
ff = random.choice(self.loan_institution)
commit_dates.append(aa)
limit_dates.append(bb)
product_types.append(cc)
borrower_idnumbers.append(dd)
borrower_phones.append(ee)
loan_institutions.append(ff)
return commit_dates,limit_dates,product_types,borrower_idnumbers,borrower_phones,loan_institutions
#将不是今天生成的文件删除
def clear_file(self):
da = time.strftime("%Y.%m.%d/%H-%M-%S", time.localtime())
da_a = str(da.split('/')[0])
path = os.path.dirname(os.path.abspath('.')) + '\config_file\case_import'
lrst = []
for file in os.listdir(path):
if da_a not in file:
lrst.append(file)
if len(lrst) == 0:
logger.info("没有需要删除的历史文件")
else:
for file in lrst:
os.remove(os.path.join(path,file))
#注意返回的了lsrt是包含标题的
def get_data(self,module):
lsrt = []
line = self.title_local(module)
ExcelFile = xlrd.open_workbook(self.ecl)
sheet = ExcelFile.sheet_by_index(0)
lsrt = sheet.col_values(line)#module列内容
return lsrt
if __name__ == '__main__':
a=file_process()
a.create_excel_file()
整段代码的基本框架思路已经给出,需要扩展的可以继续扩展,分享快乐,一起进步。
其它学习内容分享:
接口自动化测试
selenium自动化测试