TensorFlow中RNN网络的实现和关键参数选择
主旨
TensorFlow提供了方便的API用于快速搭建和实现RNN网络。但是在实际工作中,这些API的关键参数选择令人迷惑,在没有时间详细阅读Tensorflow引用论文和源代码的条件下,仅仅靠网络上找到的样例代码决定某些参数的选择是危险且低效的。为了解决这个问题,同时不陷入过于复杂的论文和TensorFlow源代码分析,本文通过受控实验的方式,设计出一个虽然简单但是能反映出RNN基本规律的训练和测试数据,通过代码实验分析不同参数对于RNN分类精度的影响,并得出对工程有实际指导意义的结论。
运行环境和源代码
TensorFlow版本
>>> tf.version
‘1.1.0-rc2’
源代码位置:https://github.com/wangyaobupt/RNN
背景知识
RNN是递归神经网络的简称,区别于此前介绍的全连接神经网络(Full Connected Network)或者卷积神经网络(CNN),RNN的一大特点是在计算中引入了递归,即当前时刻t的输出不止由t时刻输入影响,还由t-1时刻的系统输出和系统状态影响。由于具备这样的性质,RNN在时间序列分析,特别是具备前后关联性的时间序列(例如自然语言等)非常有用。
目前LSTM是一类常用的RNN单元结构,本文不会涉及LSTM网络的原理,感兴趣的读者推荐阅读以下两篇参考资料。
http://colah.github.io/posts/2015-08-Understanding-LSTMs/
https://deeplearning4j.org/lstm.html#recurrent
需要提醒注意的是:虽然LSTM名字中有“记忆”,但这里的记忆主要是为了让神经元记住此前时刻的状态,而不应该与人类的记忆能力混淆,误以为LSTM是用来记忆数据的。如果只是记忆数据,向磁盘写文件就足够好了。LSTM记忆此前时刻的状态,是为了形成一定程度上的“推理”(此处表达不够严谨):即根据对过去一段时间输入的处理结果,加上当前时刻的输入,综合分析数据特征。
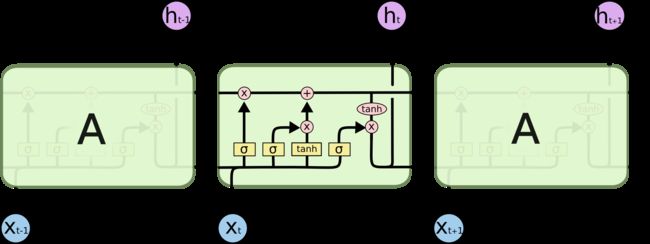
LSTM典型示意图如下,示意图来自http://colah.github.io/posts/2015-08-Understanding-LSTMs/
API 和 需要确定的关键参数
TensorFlow提供了方便的API用于构造LSTM单元和网络,在本文中会用到的两个介绍如下
tf.contrib.rnn.BasicLSTMCell
根据API文档,其构造函数中num_units是没有默认值,必须由网络设计者给定。API文档中对这个参数的作用描述如下
num_units: int, The number of units in the LSTM cell
对于上述描述,笔者表示仍然看不懂,因为“units in the LSTM cell”这个概念在API文档上并没有直接定义。
为了解决这个问题,我们从TF源代码入手,分析上述API对应的源代码 core_rnn_cell_impl.py,找到如下源代码
class BasicLSTMCell(RNNCell):
"""Basic LSTM recurrent network cell.
The implementation is based on: http://arxiv.org/abs/1409.2329.
We add forget_bias (default: 1) to the biases of the forget gate in order to
reduce the scale of forgetting in the beginning of the training.
It does not allow cell clipping, a projection layer, and does not
use peep-hole connections: it is the basic baseline.
For advanced models, please use the full LSTMCell that follows.
"""
def __init__(self, num_units, forget_bias=1.0, input_size=None,
state_is_tuple=True, activation=tanh, reuse=None):
"""Initialize the basic LSTM cell.
Args:
num_units: int, The number of units in the LSTM cell.
forget_bias: float, The bias added to forget gates (see above).
input_size: Deprecated and unused.
state_is_tuple: If True, accepted and returned states are 2-tuples of
the `c_state` and `m_state`. If False, they are concatenated
along the column axis. The latter behavior will soon be deprecated.
activation: Activation function of the inner states.
reuse: (optional) Python boolean describing whether to reuse variables
in an existing scope. If not `True`, and the existing scope already has
the given variables, an error is raised.
"""
if not state_is_tuple:
logging.warn("%s: Using a concatenated state is slower and will soon be "
"deprecated. Use state_is_tuple=True.", self)
if input_size is not None:
logging.warn("%s: The input_size parameter is deprecated.", self)
self._num_units = num_units
self._forget_bias = forget_bias
self._state_is_tuple = state_is_tuple
self._activation = activation
self._reuse = reuse
@property
def output_size(self):
return self._num_units注意到其中output_size()函数返回值就是num_units,所以可以推断num_units决定了LSTM Cell输出向量的维度,对于一个batch中的一个sample,num_units决定了这个sample的维度。进一步,num_units可以理解为RNN网络表征特征的复杂度,需要区分的特征越复杂,就需要越多的维度来表征。
tf.nn.dynamic_rnn
单独一个LSTM Cell并不能形成网络,这里我们还需要另外的API构造出RNN网络。在API文档中的多个RNN网络中,我们选择dynamic_rnn,其API文档介绍的输入如下
cell: An instance of RNNCell.
inputs: The RNN inputs.上述Cell就是我们通过LSTM cell API获得的实例,而inputs则是输入RNN的数据,以Tensor的形式表示。
关于input,API文档进一步解说如下
If time_major == False (default), this must be a Tensor of shape: [batch_size, max_time, ...], or a nested tuple of such elements.
...
The input to cell at each time step will be a Tensor or (possibly nested) tuple of Tensors each with dimensions [batch_size, ...]. 根据上述文档,可以这样理解,在time_major==False(默认值)条件下,input必须是[batch_size, max_time, …]形式的Tensor,其中…又是每个时刻的数据Tensor,形状不限。
关键参数
前一节的API介绍中,至少有两个关键参数需要确定
- LSTMCell的num_units
- RNN网络中input tensor的第二个维度,max_time
实验和神经网络设计
考虑一个数列分类问题,输入数列的长度设计为10,这是10个元素每个都是一个标量,生成两类数据。
- 第一类,前5个元素是递增的自然数0,1,2,3,4,后5个元素是随机数,记为[0,1,2,3,4,Rand,Rand,Rand,Rand,Rand];
- 第二类,10个元素全部是随机数,记为[Rand,Rand,Rand,Rand,Rand,Rand,Rand,Rand,Rand,Rand]
数据生成代码如下
def genUTData(num):
data = np.zeros((num, 10, 1))
label = np.zeros((num, 2))
for index in range(0, num):
if index % 2 == 0:
label[index][0] = 1
for i in range(0, 5):
data[index][i][0] = i
for i in range(5,10):
data[index][i][0] = np.random.randn(1)
else:
label[index][1] = 1
data[index] = np.random.randn(10, 1)
return data, labelRNN网络设计:由于是简单二分类问题,LSTMCell的num_units设置为2,直接作为输出用的one-hot vector。网络采用最简单的结构,输入Tensor直接进入LSTMCell,经过max_time处理后获得输出
思考题:假如问题很复杂,num_units=2不足以正确分类,同时问题目标又是二分类问题怎么办?(思路见文末)
with tf.name_scope('net_define'):
batch_size_t = tf.placeholder(tf.int32, None)
inputTensor = tf.placeholder(tf.float32, [None, max_time, dims_of_input], name='inputTensor')
labelTensor = tf.placeholder(tf.float32, [None, n_classes], name='LabelTensor')
lstmCell = tf.contrib.rnn.BasicLSTMCell(num_units_in_LSTMCell)
init_state = lstmCell.zero_state(batch_size_t, dtype=tf.float32)
raw_output, final_state = tf.nn.dynamic_rnn(lstmCell, inputTensor, initial_state = init_state)
outputs = tf.unstack(tf.transpose(raw_output, [1, 0, 2]), name='outputs_before_softmax')
output = outputs[-1];
output = tf.identity(output, 'tensor_before_softmax')
y_predict = tf.nn.softmax(output, name='softmax_output')前文提到的两个关键参数,num_units已经通过2分类问题确定,另一个max_time参数的确定比较复杂,因此我设计了两套实验方案,在给定某个max_time取值的条件下
- 方案1:将原始序列(长度=10,每个元素是标量)截断到长度等于max_time,每个step仍然是一个1维标量
- 方案2:将原始序列(长度=10,每个元素是标量)变形为一个形状为[max_time, dims_of_input]的矩阵,这里为了简单,max_time只取1,2,5,10这些可以被总长度10整除的数字
代码中通过以下开关控制两种测试方案
# define the test plan:
# plan1: fix 'max_time', if length_of_input_sequence is longer than max_time, drop the oldest element to make the input sequence same length as max_time
# plan2: use reshape function to reshape input sequence to (max_time, -1)
test_plan = 1实验结果和分析
本文的结果以Tensorboard中输出的“精度-迭代次数”和“交叉熵-迭代次数”曲线表示,橙色为测试集,蓝色为训练集。精度达到1表示对所有样本分类正确,交叉熵越接近0表示分类效果越好。
方案1测试结果和分析
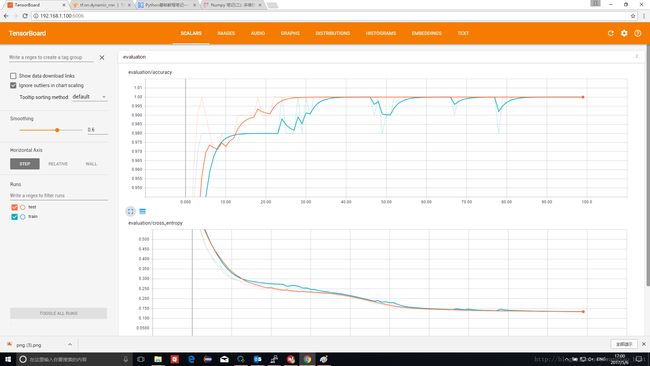
max_time=10
这种情况下整个原始数列进入RNN分类器。第一类数据输入为[0,1,2,3,4,Rand,Rand,Rand,Rand,Rand]
可以看出虽然有波动,但最终分类器实现了100%正确分类。
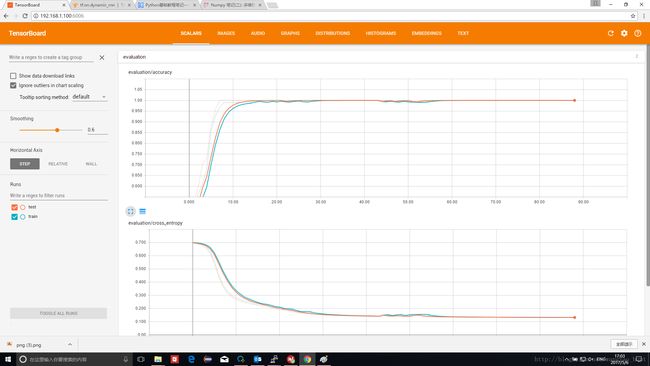
max_time=6
这种情况下只有原始数列的最后6个元素进入RNN,回忆一下数据生成规则,区分第一类和第二类的关键在于前5个元素,所以最后6个元素中第一个元素仍然是有规则的。实际第一类输入数据为[4,Rand,Rand,Rand,Rand,Rand]
实测结果如下,仍然可以实现100%正确分类。
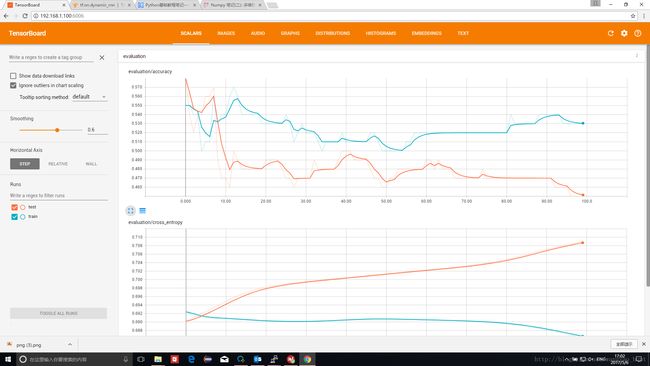
max_time=5
这种情况下只有原始数列的最后5个元素进入RNN,根据数据生成规则,无论是第一类还是第二类数据,最后5个元素都是随机数。实际第一类输入数据为[Rand,Rand,Rand,Rand,Rand]。
因而在测试结果上,分类器无法做到正确分类,分类准确率在50%左右,完全随机
小结:在只给出一个长序列的区间片段到RNN的情况下,只有给定区间包含了能够分类的规律,RNN才能实现分类
用一个具体的例子来解释,假定明天的天气受到过去一周天气的影响,如果在训练神经网络中只传入昨天和今天的天气,无论怎么训练,预测结果都不会好。
方案2测试结果和分析
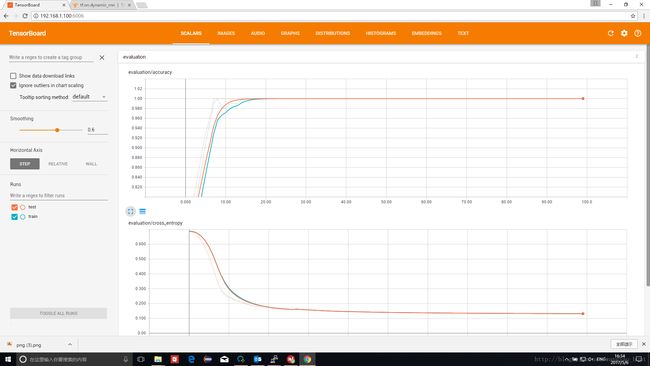
max_time=10
这种情况下方案2等价于方案1,第一类数据输入为[0,1,2,3,4,Rand,Rand,Rand,Rand,Rand]
测试结果也印证了这一点
max_time=5
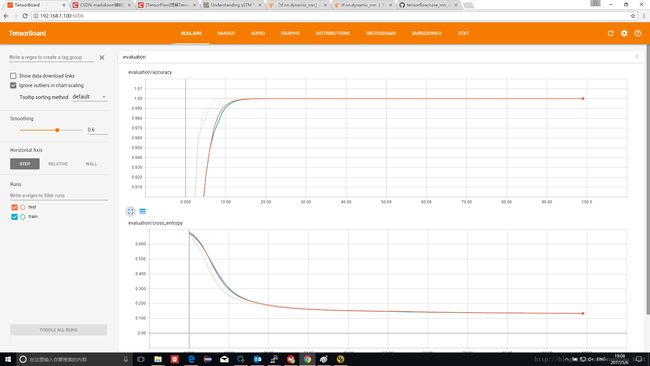
方案2在这种情况下虽然把RNN的输入压缩到了5个时刻,但每个时刻从1维标量变为2维Tensor,第一类数据输入为[[0,1],[2,3],[4,Rand],[Rand,Rand],[Rand,Rand]]
从信息的角度,仍然包含了可以区分两类的信息。因此测试结果证明,仍然可以正确分类
max_time=1
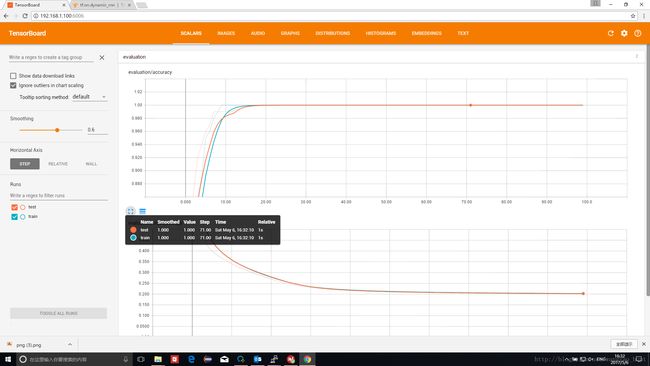
对于方案2,这是一种极端情况,意味着我们将连续时间序列“退化”成了一个单个点,对于第一类数据,其形式为[[0,1,2,3,4,Rand,Rand,Rand,Rand,Rand]]。
这样RNN的R即递归就不发生作用,整个数据只有一个时刻,输出只由当前时刻决定。
实测证明,在这种情况下,RNN仍然能正确分类
小结:在完整保留长序列信息的情况下,无论max_time如何选择,都不影响正确分类
结论
基于上述实验,结论如下
- num_units的选择:根据分类问题的复杂程度决定,
- 如果分类问题本身较为简单,不同类别之间存在明显区分(例如本文中的例子)。则num_units取值可以很小,甚至对于分类问题可以使用类别数目作为num_units,最后经过softmax作为分类向量使用;
- 如果设计者认为分类问题不是简单问题,即不同类别之间区分不明显,则num_units必须增加才能表征复杂特征。为了输出N分类的最终结果,RNN输出数据需要通过全连接网络将输出转为N分类结果。举个例子,对于复杂二分类问题,例如笔者前一篇文章 可视化展示神经网络是如何将分类正确率提升的,num_units=64才获得满足预期的分类结果,即LSTM输出的是64维向量。如何将64维向量转为2分类结果,就是在LSTM输出之后附加一个64路输入,两个输出节点的全连接层,通过全连接层将输出转为one-hot vector
- max_time的选择: max_time决定了RNN中时间序列的长度,进一步,决定了RNN能记忆到“此前多久 ”的输入数据,在设计这个参数时,需要确保设定的长度足以区别不同类别数据。
TODO
关于如何根据问题复杂度选择num_units的问题,本文给出的描述是定性的,笔者计划通过定量实验的方式展示num_units的变化是如何影响分类器准确度的,后续文章完成后会在这里通过Link连接。