python小数据池(内存地址)
今天来学习认识一下python中的小数据池。
我们都知道 ==是用来作比较,要是两个变量的数值相等,
用==比较返回的bool值会是True:
a = 1000
b = 1000
print(a == b) #返回True
== 比较的是数值
如果我们用a is b这样的方式呢?
注意要测试内存地址is()和接下来的id()方法等都不要在pyCharm (python IDE)中测试,
而是要打开python自带的IDE或直接cmd环境下测试才能得出效果。
(PyCharm的话会直接放同一个内存地址了,不是真实生产环境。)
is 比较的是内存地址,
print(a is b) #返回的是False
"==" 和 "is" 的区别:
前者是相等性比较,
比较的是两个对象中的值是否相等,后者是一致性比较,比较的是两个对象的内存空间地址是否相同。
如果内存地址相同,那么它们的值肯定也是一样的,因此,如果 “is” 返回 True,那么 “==” 一定也返回 True,反之却不成立。有且当仅比较的两个变量指向同一个对象时 "is" 才返回 True,而 "==" 最终取决于对象的 eq() 方法,本质上两个变量进行 "==" 比较操作调用的是对象的 eq() 方法。
查看内存地址我们使用的是id()方法:
print(id(a)) #返回的是内存地址,id门牌号之类
print(id(b))
若是将
a = 1000
b = a
再判断a is b又如何?
python一切皆是对象,和liunx一切皆文件有点异曲同工之处。
对象是通过引用传递的。在赋值时,不管这个对象是新创建的,还是一个已经存在的,都是将该对象的引用赋值给变量。
所以这里a实际上和b是同一个对象,a is b为true!
>>> c = 256
>>> d = 256
>>> c is d
True
>>> e = 257
>>> f = 257
>>> e is f
False将c赋值整型值256,d也为256,e为257,f为257。
当把c与d,e与f进行is操作时,却发现两者的布尔值结果不同。
为什么呢?
这是由python中的整型对象的缓冲池机制引起的。
在python中几乎所有的内建对象,都会有自己所特有的对象池机制。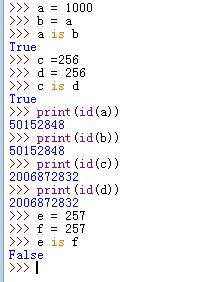
小数据池 (注意只有字符串和数值有这个概念)
在一定范围之内的,共用同一个内存地址。
数字 -5~256 节省空间(内存),共用的都是一个小数据池(指向的是同一个内存地址)
小整数对象[-5, 257]在python中是共享的
(注,用列表表示是因为python中含首不含尾,所以[-5,257]表示的范围也就是数字 -5~256。)
整数对象都是从缓冲池中获取的。
整数对象回收时,内存并不会归还给系统,而是将其对象的ob_type指向free_list,供新创建的整数对象使用
1.小整数对象——小整型对象池
[small_ints的链表]
在实际编程中,数值比较小的整数,比如1,2,33等,会非常频繁的出现。
python中,所有的对象都存在于系统堆上。
如果某个小整数出现的次数非常多,那么python将会出现大量的malloc/free操作,这样大大降低了运行效率,而且会造成大量的内存碎片,严重影响Python的整体性能。
所以在python2.5乃至3.6中,将小整数位于[-5,257)之间的数,缓存在小整型对象池中。
2.大整数对象——通用整数对象池
python将小整型数完全的缓存在了小对象缓存池中了。
而那些大整数对象呢?
python运行环境也有提供一块内存空间供大整数轮流使用。
这块内存空间就是PyIntBlock。
通常称为通用整数对象池。
所以大整数其实也是有缓存的。
该对象池使用链表组织,哪怕两个大整数变量有着相同的值,但是在链表中确是不同的节点。不再是一个对象了。
字符串intern
关于字符串的intern内存驻留机制:
Incomputer science, string interning is a method of storing only onecopy of each distinct string value, which must be immutable. Interning strings makes some stringprocessing tasks more time- or space-efficient at the cost of requiring moretime when the string is created or interned. The distinct values are stored ina string intern pool. --引自维基百科
译:
在计算机科学中,string interning是一种只存储每个不同字符串值的onecopy的方法,它必须是不可变的。连接字符串使得一些stringprocessing任务更费时——或者更节省空间,因为在创建或插入字符串时需要moretime。不同的值存储在字符串驻留池中。
也就是说值相同的字符串对象只会保存一份,是共用的,所以字符串必须是不可变对象。
就跟小整数对象一样,相同的数值只要保存一份就行了,没必要用不同对象来区分。
同时以上也说到了这样做的优缺点:
优点:能够提高一些字符串处理任务在时间和空间上的性能;需要值相同的字符串的时候(比如标识符),直接从池里拿来用,避免频繁的创建和销毁,提升效率,节约内存。
缺点:在创建或插入字符串时会花费更多的时间。
注意事项
1、拼接字符串
由于字符串的改动不是inplace的操作,需要新建对象,因此不推荐使用+来拼接字符串,推荐使用join函数,因为join函数在拼接字符串之前会计算所有字符串的长度,然后逐一拷贝,仅新建一次对象。
2、字符串驻留限制
仅包含下划线(_)、字母和数字的字符串会启用字符串驻留机制驻留机制。因为解释器仅对看起来像python标识符的字符串使用intern()方法,而python标识符正是由下划线、字母和数字组成。
python默认只会对由字符
"0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ_abcdefghijklmnopqrstuvwxyz"构成字符串进行intern。
这部分的逻辑在codeobject.c中的函数PyCode_New中:在该函数中,会调用all_name_chars,检查字符串是否全是由简单的字符组成,判断通过的字符串才会进行intern处理。
这里的分析是对常量而言,对于计算得出的字符串,也是不做intern的。
python2中可以用intern()来对除此外的字符串进行处理使其共用一个内存空间,python3中不知为何对intern取消了支持。可能怕引起混乱吧,反正就默认了对那些看起来像是python标识符的进行intern。
例:python27中支持intern()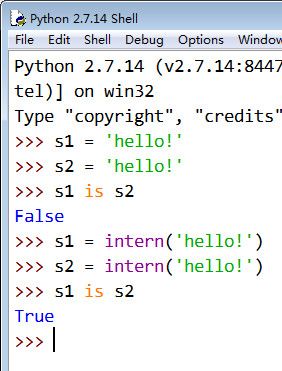
python3中使用intern()会直接报错。
>>> s3 = intern('hello!')
Traceback (most recent call last):
File "", line 1, in
s3 = intern('hello!')
NameError: name 'intern' is not defined 3、字符串驻留时机
字符串只会在编译时进行驻留,而不是在运行时。
例:
>>> s5 = 'tiele'
>>> s6 = 'mao'
>>> 'tiele' + 'mao' is 'tielemao'
True
>>> s5 + s6 is 'tielemao'
False实现 Intern 机制的就好比是通过维护一个字符串储蓄池,这个池子是一个字典结构,如果字符串已经存在于池子中了就不再去创建新的字符串,直接返回之前创建好的字符串对象,如果之前还没有加入到该池子中,则先构造一个字符串对象,并把这个对象加入到池子中去,方便下一次获取。
短字符串缓冲池characters
另外,字符串除了有intern机制缓存字符串之外,还有一种专门的短字符串缓冲池characters。用于缓存字符串长度为1的PyStringObject对象。
变长对象
在Python世界中将对象分为两种:
一种是定长对象,比如整数,整数对象定义的时候就能确定它所占用的内存空间大小,另一种是变长对象,在对象定义时并不知道是多少,比如:str,list, set, dict等。
同样都是字符串对象,不同字符串对象所占用的内存是不一样的,这就是变长对象,对于变长对象,在对象定义时是不知道对象所占用的内存空间是多少的。
字符串对象在Python内部用PyStringObject表示,PyStringObject和PyIntObject一样都属于不可变对象,对象一旦创建就不能改变其值。
(注意:变长对象和不可变对象是两个不同的概念)。
总结:
- 字符串用PyStringObject表示
- 字符串属于变长对象
- 字符串属于不可变对象
- 字符串用intern机制提高python的效率
- 字符串有专门的缓冲池存储长度为1的字符串对象
本文大量引用和参考链接如下:
https://foofish.net/python_str_inplements.html 《python字符串对象实现原理》
https://foofish.net/python_int_implement.html 《python整数对象实现原理》
https://blog.csdn.net/u011300968/article/details/77160619 《Python的字符串驻留》
end
铁乐与猫
2018-3-26