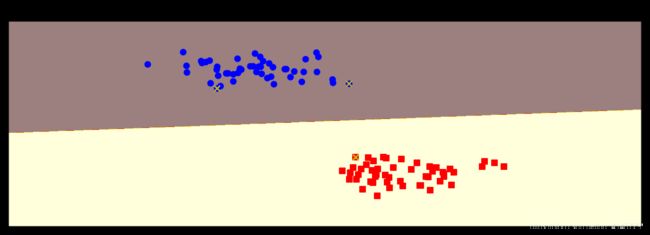
sklearn机器学习(八)简单的SVM分类
真的很简单的SVM,所以就不写个啥了!
直接拿去用吧!
from sklearn import svm
from sklearn.datasets import make_blobs#make_blobes用来生产小型的聚类数据集
import matplotlib.pyplot as plt
import numpy as np
def plot_hyperplance(clf, X, y, h=0.02, draw_sv=True, title='hyperplan'):
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))#生成网格点坐标矩阵
plt.title(title)
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())
plt.xticks(())#设置坐标轴刻度
plt.yticks(())
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])#ravel是对数组的扁平化,只是进行一个引用,尝试改为flatten,可以尽量避免出错
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, cmap='hot', alpha=0.5)#进行三维等高线图绘制、并进行填充
makers = ['o', 's', '^']
colors = ['b', 'r', 'c']
labels = np.unique(y)#去除重复数字
print(labels)
for label in labels:
plt.scatter(X[y == label][:, 0], X[y == label][:, 1], c=colors[label], marker=makers[label])
#这里面的X[y == label][:, 0]在我看来有点难,所以我打算解释一下整体思路,
#首先labels只有0,1个标签,y里面的值为0或1, y==label 就是y的值等于0划分为1组,y的值等于1划分为一组,将X数组分为0和1两个标签的数组,
#一开始的X为【100,2】的数组,经过y==label划分之后得到的数组依然是【50,2】的数组,
#之后再经过后面的[:, 0]做的一个简单划分,成为【50,1】的数组
if draw_sv:
sv = clf.support_vectors_#绘制支持向量
plt.scatter(sv[:, 0], sv[:, 1], c='y', marker='x')#散点图绘制,颜色为黄色 用x标出
X,y=make_blobs(n_samples=100,centers=2,random_state=0,cluster_std=0.3)#cluster_std的意思是聚类方差=0.3
clf=svm.SVC(C=1.0,kernel='linear')#C是惩罚松弛变量
clf.fit(X,y)
plt.figure(figsize=(12,4),dpi=144)
plot_hyperplance(clf, X, y, h=0.01, title='Maximum Margin Hyperplan')
plt.show()