数据结构学习笔记--二叉表达式树
终于到谈到树了,可以说数据结构最精彩的算法都出自这里
(但不是最复杂的,后面还有图..)。接下来的2篇文章会介绍有关树的一些操作和应用。
树的两个基本用途,可以用物质和精神来比喻。
一个用途是做为数据储存,储存具有树结构的数据——目录、族谱等等。为了在实际上是线性的储存载体上(内存、磁盘)储存非线性的树结构,必须有标志指示出树的结构。因此,只要能区分根和子树,树可以采取各种方法来储存——多叉链表、左孩子-右兄弟二叉链表、广义表、多维数组。由于操作的需求,储存方法并不是随意选取的。比如,在并查集的实现上,选取的是双亲链表。
一个用途是做为逻辑判断,此时会常常听到一个名词——判定树。最常用的结构是二叉树
(见下文),一个孩子代表true,一个孩子代表false。关于多叉判定树,有个例子是求8皇后的全部解——这个连高斯都算错了(一共是92组解,高斯最开始说76组解),我们比不上高斯,但是我们会让computer代劳。
就像哲学界到现在还纠缠于物质和精神本源问题,实际上在树这里也是如此。有些情况下,并不能区分是做为储存来用还是做为判断来用,比如搜索树,既储存了数据,还蕴涵着判断,这在后续的文章会提到。
和后面的图相比,树更基本,也更常用。你可以不知道最短路径怎么求,却每时每刻都在和树打交道——看看你电脑里的文件夹吧
^_^
首先要介绍的是树形结构中最基础、最常用的所谓二叉树。二叉树可以说是人们假想的一个模型,因此,允许有空的二叉树是无争议的。二叉树是有序的,左边有一个孩子和右边有一个的是不同的两棵二叉树树。做这个规定,是因为人们赋予了左孩子和右孩子不同的意义。二叉树有多种存储方式,下面只讲解链式结构。看各种讲数据结构的书,你会发现一个有趣的现象:在二叉树这里,基本操作有计算树高、寻找节点以及各种遍历,但就是没有插入、删除操作。那树是怎么建立起来的?其实这很好理解,对于非线性的树形结构,插入删除操作不在一定的法则规定下,是毫无意义的。因此,只有在具体的应用中,才会有插入删除操作。
与之前的文章一样,这里不讨论各种基本操作,而是讲一些实际应用。我发现这样更有利于加深对数据结构的理解。这里讲书上的例子:二叉表达式树。但书上一个具体算法都没有给出,倒是随书光盘里给出了一个中缀表达式建树的演示,我就根据它编写了一个完整的表达式树类,下面以它来介绍二叉树的一些典型操作。包括:输入任意形式的表达式建立一棵树,表达式树的求值以及通过不同方式的遍历来生成不同形式的表达式。
首先是结点结构。与前面学过的线形链表一样,二叉树的结点也分为数据域与指针域,只不过这里有两个指针域分别指向左右孩子节点。有时为了操作方便还会附加一个双亲指针,这里就不需要了,下面是节点定义:
class
TNode {
public :
union { char optr; int opnd; };
TNode * left;
TNode * right;
TNode( char op, TNode * lef, TNode * rgt)
: optr(op), left(lef), right(rgt) {}
TNode( int num)
: opnd(num), left(NULL), right(NULL) {}
};
public :
union { char optr; int opnd; };
TNode * left;
TNode * right;
TNode( char op, TNode * lef, TNode * rgt)
: optr(op), left(lef), right(rgt) {}
TNode( int num)
: opnd(num), left(NULL), right(NULL) {}
};
在表达式中又分运算数与操作符,所以结点的数据域必须设成联合的形式。同时为了便于生成新结点而加了两个构造函数。因为这个表达式类只是为了介绍二叉树,所以为了简便起见规定操作数只能是
1~9的整数。
表达式类的定义很简单,只需要存储一个指向树根的指针就够了,并且不需要做任何的初始化操作。下面是类的定义及部分函数声明。
#include
"
../../线性表(链式存储)/栈/Stack.h
"
#include " ../../require.h "
#include < iostream >
#include < string >
class ExpTree {
TNode * m_pRoot;
public :
ExpTree() : m_pRoot(NULL) {}
~ ExpTree() { destroy(m_pRoot); }
// 求值
int value() { return val(m_pRoot); }
private :
// 销毁树
void destroy(TNode * cur) {
if (cur) {
destroy(cur -> left);
destroy(cur -> right);
delete cur;
}
}
// 计算
int cacul( int a, char op, int b) {
switch (op) {
case ' + ' : return a + b;
case ' - ' : return a - b;
case ' * ' : return a * b;
case ' / ' : return a / b;
}
}
// 求值函数
int val(TNode * cur) {
if (cur -> left == NULL && cur -> right == NULL)
return cur -> opnd;
else
return cacul(val(cur -> left), cur -> optr, val(cur -> right));
}
};
#include " ../../require.h "
#include < iostream >
#include < string >
class ExpTree {
TNode * m_pRoot;
public :
ExpTree() : m_pRoot(NULL) {}
~ ExpTree() { destroy(m_pRoot); }
// 求值
int value() { return val(m_pRoot); }
private :
// 销毁树
void destroy(TNode * cur) {
if (cur) {
destroy(cur -> left);
destroy(cur -> right);
delete cur;
}
}
// 计算
int cacul( int a, char op, int b) {
switch (op) {
case ' + ' : return a + b;
case ' - ' : return a - b;
case ' * ' : return a * b;
case ' / ' : return a / b;
}
}
// 求值函数
int val(TNode * cur) {
if (cur -> left == NULL && cur -> right == NULL)
return cur -> opnd;
else
return cacul(val(cur -> left), cur -> optr, val(cur -> right));
}
};
在之前的章节讲栈与递归时书上给出过一个中缀表达式求值的具体程序,在求值过程中需要用两个栈,并且代码并不简单。而这里你会看到,对于表达式树的求值操作却非常简单,甚至只需要两条语句。因为这里大部分操作都是递归定义,而递归函数本身都是很简洁的,甚至比你想象的还要简单!就像树的遍历操作
(我第一次看时有些惊讶,没想到如此简单)。三种遍历分别是先序遍历、中序遍历与后序遍历,正好对应表达式的三种形式:前缀型、中缀型与后缀型。其中为大家所熟知的是中缀形式,如2+3*(5-4)。前缀型表达式又叫波兰式(Polish Notation),后缀性表达式又叫逆波兰式(Reverse Polish Notation)。它们最早于1920年由波兰数学家Jan Lukasiewicz 发明,这两种表示方式的最大特点是不需要括号来标明优先级,它们经常用于计算机科学,特别是编译器设计方面。三种遍历方式书上讲得很详细,不再说了,并且利用C++的封装和重载特性,这些遍历方法能很清晰的表达
:
public
:
// 先序遍历
void PreOrder( void ( * visit)(TNode * cur) = print) {
cout << " 先序遍历(波兰式): " << endl;
PreOrder(m_pRoot, visit);
cout << endl;
}
// 中序遍历
void InOrder( void ( * visit)(TNode * cur) = print) {
cout << " 中序遍历(中缀形式): " << endl;
InOrder(m_pRoot, visit);
cout << endl;
}
// 后序遍历
void PostOrder( void ( * visit)(TNode * cur) = print) {
cout << " 后序遍历(逆波兰式): " << endl;
PostOrder(m_pRoot, visit);
cout << endl;
}
private :
// 先序遍历
void PreOrder(TNode * p, void ( * visit)(TNode * cur) = print) {
if (p != NULL) {
visit(p);
PreOrder(p -> left, visit);
PreOrder(p -> right, visit);
}
}
// 中序遍历
void InOrder(TNode * p, void ( * visit)(TNode * cur) = print) {
if (p != NULL) {
InOrder(p -> left, visit);
visit(p);
InOrder(p -> right, visit);
}
}
// 后序遍历
void PostOrder(TNode * p, void ( * visit)(TNode * cur) = print) {
if (p != NULL) {
PostOrder(p -> left, visit);
PostOrder(p -> right, visit);
visit(p);
}
}
// 先序遍历
void PreOrder( void ( * visit)(TNode * cur) = print) {
cout << " 先序遍历(波兰式): " << endl;
PreOrder(m_pRoot, visit);
cout << endl;
}
// 中序遍历
void InOrder( void ( * visit)(TNode * cur) = print) {
cout << " 中序遍历(中缀形式): " << endl;
InOrder(m_pRoot, visit);
cout << endl;
}
// 后序遍历
void PostOrder( void ( * visit)(TNode * cur) = print) {
cout << " 后序遍历(逆波兰式): " << endl;
PostOrder(m_pRoot, visit);
cout << endl;
}
private :
// 先序遍历
void PreOrder(TNode * p, void ( * visit)(TNode * cur) = print) {
if (p != NULL) {
visit(p);
PreOrder(p -> left, visit);
PreOrder(p -> right, visit);
}
}
// 中序遍历
void InOrder(TNode * p, void ( * visit)(TNode * cur) = print) {
if (p != NULL) {
InOrder(p -> left, visit);
visit(p);
InOrder(p -> right, visit);
}
}
// 后序遍历
void PostOrder(TNode * p, void ( * visit)(TNode * cur) = print) {
if (p != NULL) {
PostOrder(p -> left, visit);
PostOrder(p -> right, visit);
visit(p);
}
}
默认的
visit函数print如下:
//
默认输出函数
void print(TNode * cur) {
if (cur -> left == NULL && cur -> right == NULL)
cout << cur -> opnd;
else cout << cur -> optr;
cout << ' ' ;
}
void print(TNode * cur) {
if (cur -> left == NULL && cur -> right == NULL)
cout << cur -> opnd;
else cout << cur -> optr;
cout << ' ' ;
}
下面来讨论如何根据表达式建立一棵树。我们知道在表达式树中,只有度为2的树杈结点与度为0的叶子节点,并且树杈节点上都存放运算符,叶子节点都存放操作数。比如由表达式1+2*3创建的树是这样的:
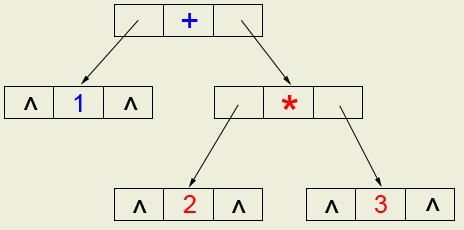
每一个叶子结点有一个确定的值,对于每一个运算符结点,也可以看做它代表一个值,其值为左子树的值与右子树的值按照结点中存储的运算符计算后的结果。如结点
’+’的值为“1+右子树的值”,而右子树的值为它的左子树的值乘以它的右子树的值,即”2*3”,所以表达式的值就是根节点的值”1+2*3”。
由上述递归的定义不难看出,建立表达式树就是建立树中的每一个结点,将每一个结点链接起来就是整棵树。而在建立深度低的结点时要将其左右指针指向之前建立的深度比它高一级的结点
(如’*’要指向’2’和’3’,而’+’又要指向’*’)。这样我们可以用栈来存放每次建立的结点,按照优先级(表达式为中缀型)或顺序扫描表达式(表达式为波兰式与逆波兰式)建立每一个结点。建立结点的顺序即为表达式求值的顺序。如果扫描到操作数则直接新建一个左右指针为空的结点,并压入结点栈中(存放结点指针)。遇到运算符时首先新建一个结点,然后从栈中依次弹出两个结点,并让新建立的结点的左右指针域指向它们。当所有结点建立完毕时,如果表达式没有错误(这里假设输入表达式正确),这时栈中应该只剩下一个结点,它就是所建立的表达式的根结点。
上面叙述的就是算法流程,对于前缀与后缀表达式,因为没有优先级的说法所以顺序扫描即可,下面是代码:
//
前缀表达式建树 样例:- + 1 * 2 3 4
void ExpTree::PreOrderCreate( string str) {
if (str.length() == 0 ) {
cout << " 输入前缀表达式(波兰式): " ;
getline(cin, str);
}
Stack < TNode *> nodeStack;
TNode * tempNode;
for ( int i = str.length() - 1 ; i >= 0 ; i -- ) {
if (str[i] == ' ' ) continue ;
switch (str[i]) {
case ' + ' : case ' - ' : case ' * ' : case ' / ' :
tempNode = nodeStack.pop();
nodeStack.push( new TNode(str[i],
tempNode, nodeStack.pop()));
break ;
default :
nodeStack.push( new TNode(str[i] - ' 0 ' ));
break ;
} // switch (str[i])
} // for (unsigned int i = 0;..)
require(nodeStack.GetLength() == 1 ,
" ExpTree::PreOrderCreate illegal expression! " );
m_pRoot = nodeStack.pop();
}
// 后缀表达式建树 样例:1 2 3 * + 4 -
void ExpTree::PostOrderCreate( string str) {
if (str.length() == 0 ) {
cout << " 输入后缀表达式(逆波兰式): " ;
getline(cin, str);
}
Stack < TNode *> nodeStack;
for ( int i = 0 ; i < str.length(); i ++ ) {
if (str[i] == ' ' ) continue ;
switch (str[i]) {
case ' + ' : case ' - ' : case ' * ' : case ' / ' :
nodeStack.push( new TNode(str[i],
nodeStack.pop(), nodeStack.pop()));
break ;
default :
nodeStack.push( new TNode(str[i] - ' 0 ' ));
break ;
} // switch (str[i])
} // for (unsigned int i = 0;..)
require(nodeStack.GetLength() == 1 ,
" ExpTree::PostOrderCreate illegal expression! " );
m_pRoot = nodeStack.pop();
}
void ExpTree::PreOrderCreate( string str) {
if (str.length() == 0 ) {
cout << " 输入前缀表达式(波兰式): " ;
getline(cin, str);
}
Stack < TNode *> nodeStack;
TNode * tempNode;
for ( int i = str.length() - 1 ; i >= 0 ; i -- ) {
if (str[i] == ' ' ) continue ;
switch (str[i]) {
case ' + ' : case ' - ' : case ' * ' : case ' / ' :
tempNode = nodeStack.pop();
nodeStack.push( new TNode(str[i],
tempNode, nodeStack.pop()));
break ;
default :
nodeStack.push( new TNode(str[i] - ' 0 ' ));
break ;
} // switch (str[i])
} // for (unsigned int i = 0;..)
require(nodeStack.GetLength() == 1 ,
" ExpTree::PreOrderCreate illegal expression! " );
m_pRoot = nodeStack.pop();
}
// 后缀表达式建树 样例:1 2 3 * + 4 -
void ExpTree::PostOrderCreate( string str) {
if (str.length() == 0 ) {
cout << " 输入后缀表达式(逆波兰式): " ;
getline(cin, str);
}
Stack < TNode *> nodeStack;
for ( int i = 0 ; i < str.length(); i ++ ) {
if (str[i] == ' ' ) continue ;
switch (str[i]) {
case ' + ' : case ' - ' : case ' * ' : case ' / ' :
nodeStack.push( new TNode(str[i],
nodeStack.pop(), nodeStack.pop()));
break ;
default :
nodeStack.push( new TNode(str[i] - ' 0 ' ));
break ;
} // switch (str[i])
} // for (unsigned int i = 0;..)
require(nodeStack.GetLength() == 1 ,
" ExpTree::PostOrderCreate illegal expression! " );
m_pRoot = nodeStack.pop();
}
简单说明一下,
nodeStack栈存放结点指针(这个栈类是之前学线性表时编写的,由于比较大(上一篇文章提到过)这里就不给出了,需要的话可以e-mail我),每次判断读取的字符,依据之前说的方式建立结点并压栈。注意在前缀表达式建树算法中,运算符结点的建立时用到了一个结点指针变量temp,来临时存放栈顶指针,在后缀建树时没有用到。这是因为在C++中,实参给形参赋值时是按照函数参数表从右向左进行的,前缀建树时的结点顺序是逆序的,所以必须保证顺序正确。
中缀建树要复杂一些,因为还有括号与优先级问题。本来我编到这里时也很头疼,后来突然想起了前面那个用栈实现表达式求值的算法,其求值过程与建树过程极其相似,只要把求值改成创建结点就可以了。如果你看过那个算法那么下面就很简单了,几乎完全一样:
//
返回运算符op所对应的优先级
int ExpTree::Precedence( const char & op) {
switch (op) {
case ' + ' : case ' - ' :
return 1 ;
case ' * ' : case ' / ' :
return 2 ;
case ' ) ' : case ' @ ' :
default :
// 定义在栈中的左括号和栈底字符的优先级最低
return 0 ;
}
}
// 中缀表达式建树 样例:1 + 2 * 3 - 4
void ExpTree::InOrderCreate( string str) {
if (str.length() == 0 ) {
cout << " 输入中缀表达式: " ;
getline(cin, str);
}
Stack < TNode *> nodeStack;
Stack < char > opStack;
opStack.push( ' @ ' );
for ( int i = 0 ; i < str.length(); i ++ ) {
if (str[i] == ' ' ) continue ;
switch (str[i]) {
case ' ( ' :
opStack.push(str[i]);
break ;
case ' ) ' :
while (Precedence(opStack.peek()) > 0 )
nodeStack.push( new TNode(opStack.pop(),
nodeStack.pop(), nodeStack.pop()));
opStack.pop(); // 弹出栈顶左括号
break ;
case ' + ' : case ' - ' : case ' * ' : case ' / ' :
while (Precedence(opStack.peek())
>= Precedence(str[i])) {
nodeStack.push( new TNode(opStack.pop(),
nodeStack.pop(), nodeStack.pop()));
}
opStack.push(str[i]);
break ;
default :
nodeStack.push( new TNode(str[i] - ' 0 ' ));
break ;
}
}
while (opStack.peek() != ' @ ' )
nodeStack.push( new TNode(opStack.pop(),
nodeStack.pop(), nodeStack.pop()));
require(nodeStack.GetLength() == 1 ,
" ExpTree::InOrderCreate illegal expression! " );
m_pRoot = nodeStack.pop();
}
int ExpTree::Precedence( const char & op) {
switch (op) {
case ' + ' : case ' - ' :
return 1 ;
case ' * ' : case ' / ' :
return 2 ;
case ' ) ' : case ' @ ' :
default :
// 定义在栈中的左括号和栈底字符的优先级最低
return 0 ;
}
}
// 中缀表达式建树 样例:1 + 2 * 3 - 4
void ExpTree::InOrderCreate( string str) {
if (str.length() == 0 ) {
cout << " 输入中缀表达式: " ;
getline(cin, str);
}
Stack < TNode *> nodeStack;
Stack < char > opStack;
opStack.push( ' @ ' );
for ( int i = 0 ; i < str.length(); i ++ ) {
if (str[i] == ' ' ) continue ;
switch (str[i]) {
case ' ( ' :
opStack.push(str[i]);
break ;
case ' ) ' :
while (Precedence(opStack.peek()) > 0 )
nodeStack.push( new TNode(opStack.pop(),
nodeStack.pop(), nodeStack.pop()));
opStack.pop(); // 弹出栈顶左括号
break ;
case ' + ' : case ' - ' : case ' * ' : case ' / ' :
while (Precedence(opStack.peek())
>= Precedence(str[i])) {
nodeStack.push( new TNode(opStack.pop(),
nodeStack.pop(), nodeStack.pop()));
}
opStack.push(str[i]);
break ;
default :
nodeStack.push( new TNode(str[i] - ' 0 ' ));
break ;
}
}
while (opStack.peek() != ' @ ' )
nodeStack.push( new TNode(opStack.pop(),
nodeStack.pop(), nodeStack.pop()));
require(nodeStack.GetLength() == 1 ,
" ExpTree::InOrderCreate illegal expression! " );
m_pRoot = nodeStack.pop();
}
建树过程中需要两个栈,
nodeStack存放结点指针不用说,还需要一个存放运算符的栈opStack。因为优先级与括号的作用,需要将因优先级低而暂时不能参与运算的运算符压入栈中(Precedence函数比较两个运算符的优先级)。当读入的运算符与栈顶的运算符优先级相等或比起低时,这时建立栈顶运算符的结点并弹栈。直到栈顶运算符优先级低于读入运算符时,再将它压入栈中。若表达式扫描完毕opStack中还有运算符,只需要依次弹出建立结点即可。
至此,二叉表达式类的所有操作就都讲完了,我们来简单测试一下:
int
main() {
cout << " 前缀表达式建树... " << endl;
ExpTree tree1;
tree1.PreOrderCreate( " + 1 * 2 - 3 4 " );
tree1.PreOrder();
tree1.InOrder();
tree1.PostOrder();
cout << " 表达式值: " << tree1.value() << endl;
cout << endl << " 中缀表达式建树... " << endl;
ExpTree tree2;
tree2.InOrderCreate( " 4/(5-9/3) " );
tree2.PreOrder();
tree2.InOrder();
tree2.PostOrder();
cout << " 表达式值: " << tree2.value() << endl;
cout << endl << " 后缀表达式建树... " << endl;
ExpTree tree3;
tree3.PostOrderCreate( " 5 6 + 7 * 8 - " );
tree3.PreOrder();
tree3.InOrder();
tree3.PostOrder();
cout << " 表达式值: " << tree3.value() << endl;
return 0 ;
}
cout << " 前缀表达式建树... " << endl;
ExpTree tree1;
tree1.PreOrderCreate( " + 1 * 2 - 3 4 " );
tree1.PreOrder();
tree1.InOrder();
tree1.PostOrder();
cout << " 表达式值: " << tree1.value() << endl;
cout << endl << " 中缀表达式建树... " << endl;
ExpTree tree2;
tree2.InOrderCreate( " 4/(5-9/3) " );
tree2.PreOrder();
tree2.InOrder();
tree2.PostOrder();
cout << " 表达式值: " << tree2.value() << endl;
cout << endl << " 后缀表达式建树... " << endl;
ExpTree tree3;
tree3.PostOrderCreate( " 5 6 + 7 * 8 - " );
tree3.PreOrder();
tree3.InOrder();
tree3.PostOrder();
cout << " 表达式值: " << tree3.value() << endl;
return 0 ;
}
同样我把输出结果也截了一张图:

为了便于比较三种形式的表达式,这里没用采用同一个表达式,若采用相同的表达式,则不论哪种方式最后建立的树都是一棵树。你要是感兴趣可以自己试试。
这样,关于二叉树就讲完了。通过这个例子,如果能加深你对于理解树的基本操作,那我就没白写
^_^有人说我写的文章太长了,看起来很费劲。没办法,主要是我懒得分的缘故,而且这样看又不用来回跳转链接,其实也挺方便的,哈哈~