python数据分析-杭州市地铁站人流量【数据源---阿里云天池新人赛】
python数据分析-杭州市地铁站人流量【数据源—阿里云天池新人赛】
前言
天池新人实战赛是针对数据新人开设的实战练习专场,以经典赛题作为学习场景,提供详尽入门教程,手把手教你学习数据挖掘。天池希望新人赛能成为高校备受热捧的数据实战课程,帮助更多学生掌握数据技能。城市计算AI挑战赛以“地铁乘客流量预测”为课题,参赛者将根据主办方提供的地铁人流相关数据,挖掘隐藏在背后的出行规律,准确预测各个地铁站点未来流量的变化。
数据下载:

#这里是数据图片展示,要下载的话点击这个链接:
https://tianchi.aliyun.com/home/ #这是阿里云天池平台,里面有很多好玩的比赛,大家有时间可以体验一下
#首页
#需要用阿里云账号登陆,没有的话就自己注册,这是我的个人中心界面,里面显示了我参加的比赛,随便点击一个项目进去:

#点击赛题与数据这一栏

#然后出现了可供下载的数据
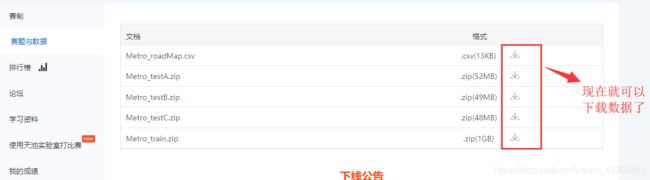
再说一下比赛数据的下载流程,点击阿里云天池平台的链接----------阿里云账号登陆----------参加比赛-----------下载数据-----------开始数据挖掘之旅
大赛以“地铁乘客流量预测”为赛题,参赛者可通过分析地铁站的历史刷卡数据,预测站点未来的客流量变化,帮助实现更合理的出行路线选择,规避交通堵塞,提前部署站点安保措施等,最终实现用大数据和人工智能等技术助力未来城市安全出行。
大赛开放了20190101至20190125共25天地铁刷卡数据记录,共涉及3条线路81个地铁站约7000万条数据作为训练数据(Metro_train.zip),供选手搭建地铁站点乘客流量预测模型。训练数据(Metro_train.zip)解压后可以得到25个csv文件,每天的刷卡数据均单独存在一个csv文件中,以record为前缀。如2019年1月1日的所有线路所有站点的刷卡数据记录存储在record_2019-01-01.csv文件中,以此类推。同时大赛提供了路网地图,即各地铁站之间的连接关系表,存储在文件Metro_roadMap.csv文件中供选手使用。
测试阶段,大赛将提供某天所有线路所有站点的刷卡数据记录,选手需预测未来一天00时至24时以10分钟为单位各时段各站点的进站和出站人次。
为帮助选手测试算法性能的鲁棒性,本次新人赛一共开放了A、B、C三个赛道:
A赛道:提供2019年1月28日的刷卡数据(testA_record_2019-01-28.csv),需对2019年1月29日全天各地铁站以10分钟为单位的人流量进行预测。
B赛道:提供2019年1月26日的刷卡数据(testB_record_2019-01-26.csv),需对2019年1月27日全天各地铁站以10分钟为单位的人流量进行预测。
C赛道:提供2019年1月30日的刷卡数据(testC_record_2019-01-30.csv),需对2019年1月31日全天各地铁站以10分钟为单位的人流量进行预测。
竞赛数据表结构
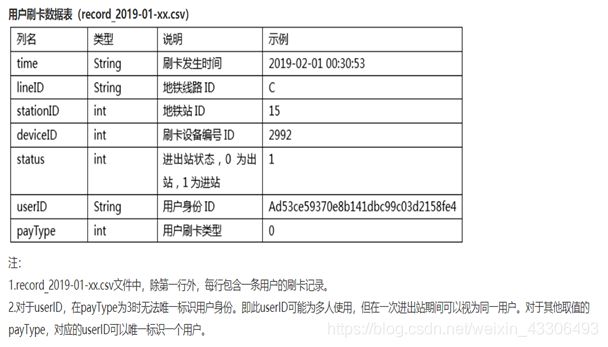

如图:
步骤一:数据预处理
(一)数据清洗:
数据清洗是指发现并纠正数据文件中可识别的错误的最后一道程序,包括检查数据一致性,处理无效值和缺失值等。与问卷审核不同,录入后的数据清理一般是由计算机而不是人工完成。
数据清洗(Data cleaning)– 对数据进行重新审查和校验的过程,目的在于删除重复信息、纠正存在的错误,并提供数据一致性。
数据清洗从名字上也看的出就是把“脏”的“洗掉”,指发现并纠正数据文件中可识别的错误的最后一道程序,包括检查数据一致性,处理无效值和缺失值等。因为数据仓库中的数据是面向某一主题的数据的集合,这些数据从多个业务系统中抽取而来而且包含历史数据,这样就避免不了有的数据是错误数据、有的数据相互之间有冲突,这些错误的或有冲突的数据显然是我们不想要的,称为“脏数据”。我们要按照一定的规则把“脏数据”“洗掉”,这就是数据清洗。而数据清洗的任务是过滤那些不符合要求的数据,将过滤的结果交给业务主管部门,确认是否过滤掉还是由业务单位修正之后再进行抽取。不符合要求的数据主要是有不完整的数据、错误的数据、重复的数据三大类。数据清洗是与问卷审核不同,录入后的数据清理一般是由计算机而不是人工完成 。
-------百度百科
数据清洗是一项复杂且繁琐的工作,同时也是整个数据分析过程中最为重要的环节。
空值和缺失值的处理
#使用isnull()和notnull()函数都能判断数据集中是否存在空值和缺失值
#查看是否存在空值和缺失值,使用isnull()
#这里只以杭州地铁站1月3日三条线路所有站点的刷卡数据记录为例
代码:

如图:

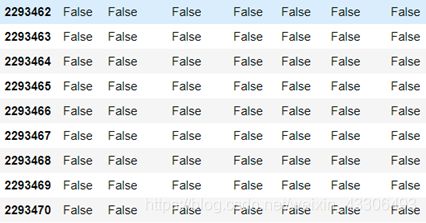
全为false,说明没有一个空值或缺失值,说明天池挑战赛提供的数据很干净
#查看是否存在空值和缺失值,使用notnull()
代码:

如图:
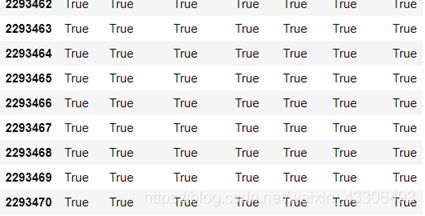
#全为true,说明没有一个空值或缺失值,说明天池挑战赛提供的数据很干净
#如果出现缺失值的话,可以使用dropna()和fillna()方法对缺失值进行填充,不过这里用不到
重复值的处理
#数据中出现了重复值,大多数情况下需要进行删除,拿这次的杭州市乘客地铁刷卡记录来说,它的时间点是唯一的,不可能同一个乘客在相同的时间点【如2019/01/11 01:11】有两条甚至是三条相同的记录出现,他搭一次车是不可能出现多条记录的,除非记录系统出现漏洞,当然重复是指每一项的数值都相同,所以这次数据清洗要是出现重复的话,就要处理重复值了
#Pandas提供duplicated()和drop_duplicated()方法处理重复值
duplicated()用来标记是否有重复值,drop_duplicated()用于删除重复值
#查看是否有重复值
代码:

如图:

所有的标记都显示为false。说明没有重复值,不需要再处理,提供的数据没有问题,记录系统没有出错
异常值的处理
#异常值是指样本中的个别值,其数值明显偏离它所属样本的其余观测值,这些数值是不合理的或错误的,需要进行处理
#检查一组数据中是否有异常值,常用3Q原则和箱型图
#3Q原则是基于正态分布的数据监测【数据要满足正态分布】,这里不做详细介绍,箱型图没有严格的要求,可以检测任意一组数据,下面用箱型图进行处理
箱型图介绍


开始检测异常值
代码:

如图:
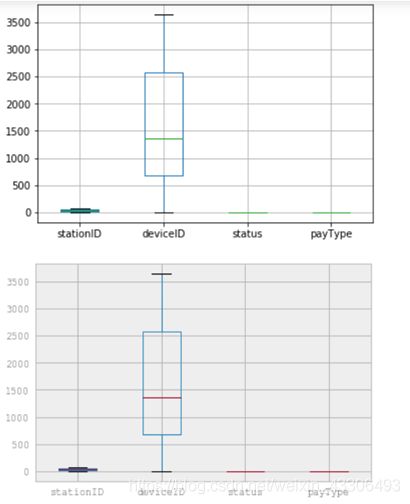
从绘制出的箱型图可以看出没有没有出现离散点,说明这次大赛提供的数据很规范干净,没有出现异常值 #这里我们需要分组显示箱形图,比如数据中有的来自1号站点、有的来自于2号站点,有的来自3号站点
以stationID进行分组,然后绘制箱形图
代码:

如图:
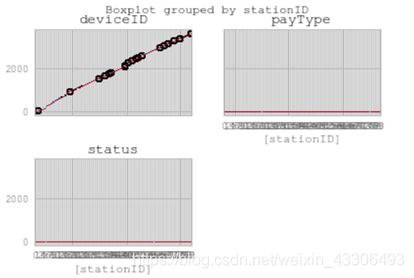
#这个结果有些看不懂,可能是分组项选的不太合适
这里我们也需要分组显示箱形图,比如数据中有的来自A线路、有的来自于B线路,有的来自C线路 #以lineID进行分组,然后绘制箱形图
代码:
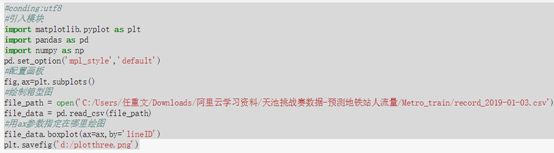
如图:

从上面箱型图可以看出deviceID这一列的所有数据没有离散点,其他三列绘出的图看不出什么,但也没有离散点,也说明数据很干净
异常值的处理【由于前面的操作没有出现异常值,这里只作介绍】


更改数据类型




比赛提供的数据的类型很规范,这里不做转换,了解就好
(二)数据合并【轴向.关键值】
#轴向堆叠数据
concat函数是在pandas底下的方法,可以将数据根据不同的轴作简单的融合




开始轴向堆叠数据
#读取1月3号到1月5号这三天的表数据
#相同字段的表首尾相接,开始合并三张表
#代码:

如图:


主键合并数据



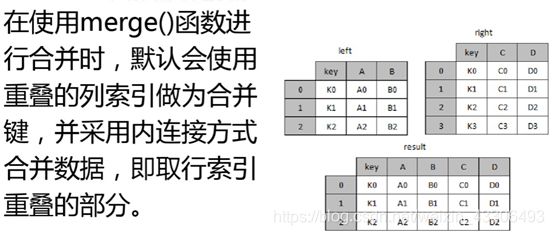



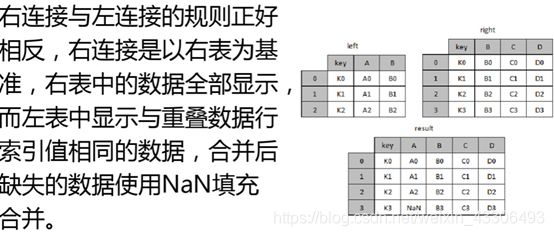
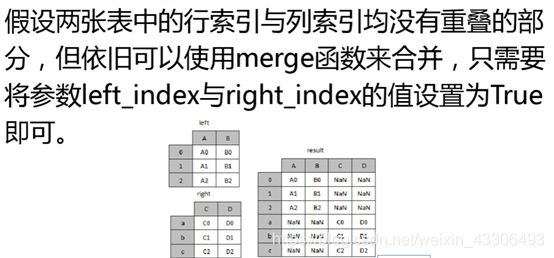
由于提供的所有表的字段值都相等,主键都相同,没有合并的必要,只介绍一下
(三)数据重塑
重塑层次化索引




#我觉得这样做意义不大,就介绍一下
(四)数据转换
离散化连续数据
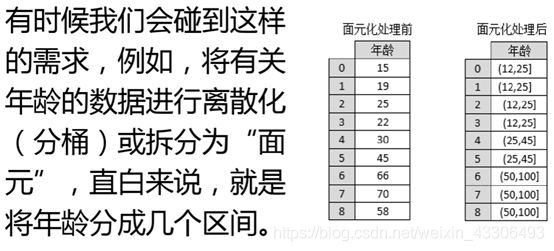




#这里只作简单介绍
步骤二:数据聚合与分组计算
分组与聚合的原理

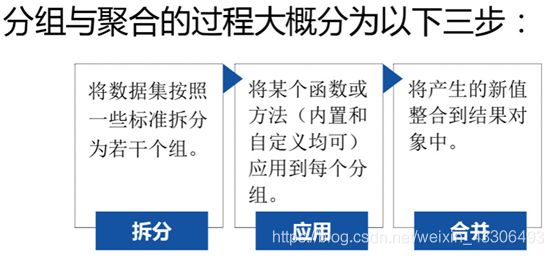

Pandas通过groupby()方法将数据拆分成组








数据读取:
开始读取杭州地铁站三条线路所有站点的刷卡数据记录【1月1日到1月25日】
杭州地铁站1月1日三条线路所有站点的刷卡数据记录
程序:
import pandas as pd
import numpy as np
#读取杭州地铁站三条线路所有站点的刷卡数据记录【1月1日到1月25日】
#读取杭州地铁站1月1日三条线路所有站点的刷卡数据记录
file_path = open(‘C:/Users/任重文/Downloads/阿里云学习资料/天池挑战赛数据-预测地铁站人流量/Metro_train/record_2019-01-01.csv’)
file_data = pd.read_csv(file_path)
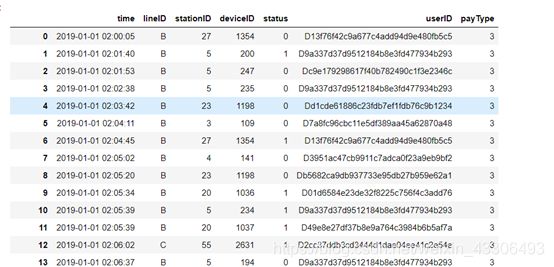
file_data
如图:

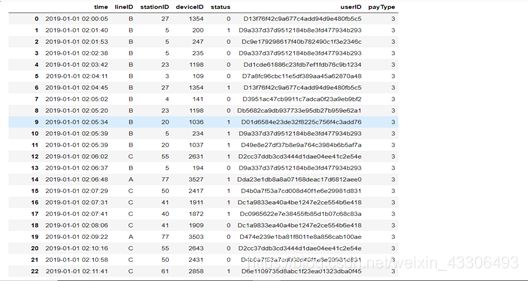
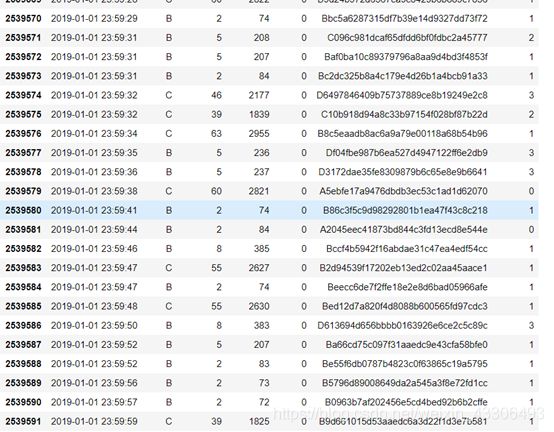
从读取到的数据可以看出,刷卡数据记录包括刷卡时间,乘客所在线路,搭车站点,刷卡设备号,刷卡状态【有或没有刷卡】,客户ID【一列字符串】,支付类型【有三种】
#杭州地铁站1月2日三条线路所有站点的刷卡数据记录
import pandas as pd
import numpy as np
读取杭州地铁站1月2日三条线路所有站点的刷卡数据记录
file_path = open(‘C:/Users/任重文/Downloads/阿里云学习资料/天池挑战赛数据-预测地铁站人流量/Metro_train/record_2019-01-02.csv’)
file_data = pd.read_csv(file_path)
file_data
如图:
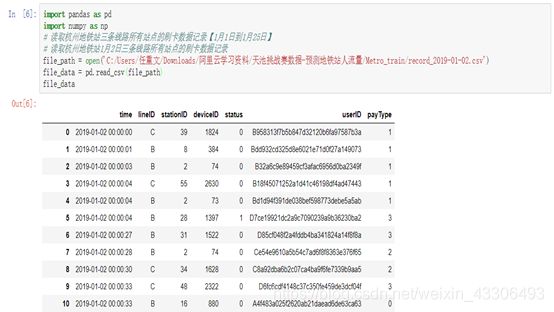

#杭州地铁站1月3日三条线路所有站点的刷卡数据记录
import pandas as pd
import numpy as np
#读取杭州地铁站1月3日三条线路所有站点的刷卡数据记录
file_path = open(‘C:/Users/任重文/Downloads/阿里云学习资料/天池挑战赛数据-预测地铁站人流量/Metro_train/record_2019-01-03.csv’)
file_data = pd.read_csv(file_path)
file_data
如图:
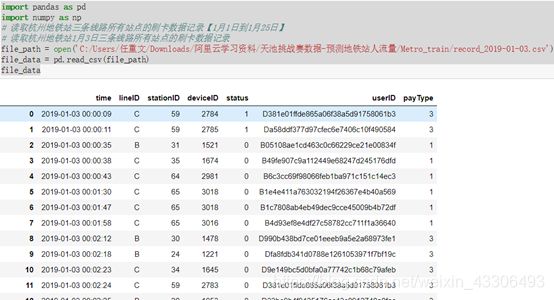

照这个模式可以读出剩下22天三条线路所有站点的刷卡数据
#由于这次的数据量太大,个人数据分析能力低下,只以1月3日的数据为例
开始数据分组
读取lineID这一列,只取唯一值
代码:
import pandas as pd
import numpy as np
file_path = open(‘C:/Users/任重文/Downloads/阿里云学习资料/天池挑战赛数据-预测地铁站人流量/Metro_train/record_2019-01-03.csv’)
file_data = pd.read_csv(file_path)
#创建一个DataFrame对象,该对象只有一列列数据:lineID[线路ID]
new_df = pd.DataFrame({‘lineID’:file_data[‘lineID’].unique()})
new_df
如图:
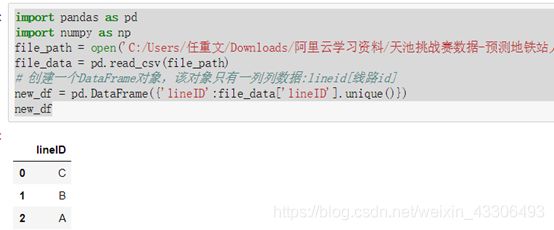
通过读取lineID一列的唯一值可以看出有三条地铁线路
这里读取的时候和数据库读表有些类似,也可以根据要求读表,也可以将记录分组,排序等等
按lineID这一列将数据进行分组,并统计每个分组的数量
代码:
import math
import pandas as pd
import numpy as np
file_path = open(‘C:/Users/任重文/Downloads/阿里云学习资料/天池挑战赛数据-预测地铁站人流量/Metro_train/record_2019-01-03.csv’)
file_data = pd.read_csv(file_path)
#按“lineID”列将file_data进行分组,并统计每个分组的数量
groupy_area = file_data.groupby(by=‘lineID’).count()
groupy_area
如图:

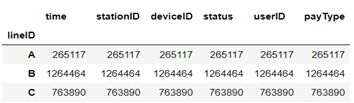
按“userID”一列从大到小排列
代码:
import math
import pandas as pd
import numpy as np
file_path = open(‘C:/Users/任重文/Downloads/阿里云学习资料/天池挑战赛数据-预测地铁站人流量/Metro_train/record_2019-01-03.csv’)
file_data = pd.read_csv(file_path)
#按“lineID”列将file_data进行分组,并统计每个分组的数量
groupy_area = file_data.groupby(by=‘lineID’).count()
groupy_area
#按“userID”一列从大到小排列
groupy_area.sort_values(by=[‘userID’], ascending=False)
如图:

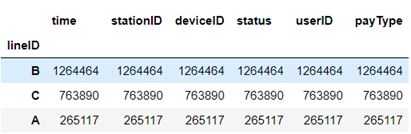
#可以从图表中看出,B站点的人流量最大,A站点最小,B站点越容易发生人流拥堵问题
按stationID这一列将数据进行分组,并统计每个分组的数量
代码:

如图:
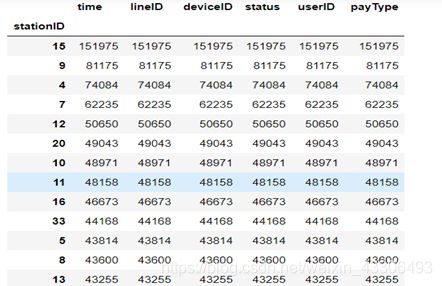
按“userID”一列从大到小排列
代码:

如图:
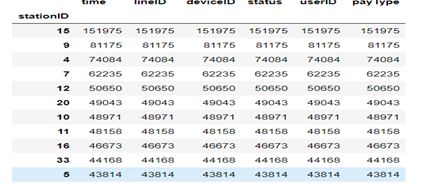

#从上图数据可以看出,15号站点人流量最大,容易发生交通人流拥堵问题,74号站点人流量最少
按deviceID这一列将数据进行分组,并统计每个分组的数量
代码:

如图:
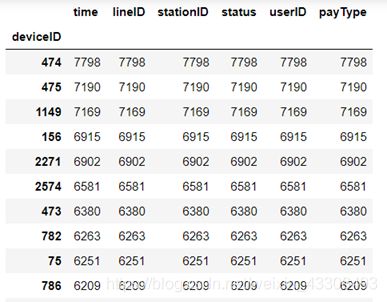
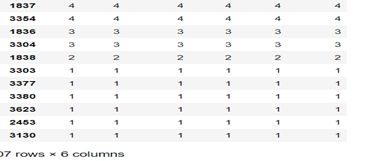
按“userID”一列从大到小排列
代码:

如图:

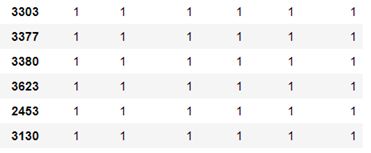
#可以看出,474号设备的刷卡数最多,3130号设备的刷卡数最少
数据聚合

开始聚合,按照lineID分组,求每个分组的平均值
代码:

如图:

#开始聚合,按照stationID分组,求每个分组的平均值
代码:

如图:
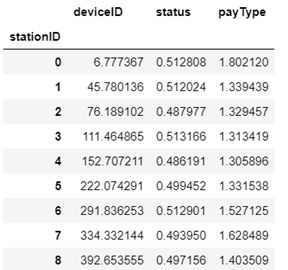
开始聚合,按照deviceID分组,求每个分组的平均值
代码:

如图:
开始聚合,按照lineID分组,求每个分组的最大,最小值
代码:

如图:

代码:

如图:

步骤三:数据可视化
数据可视化概述:




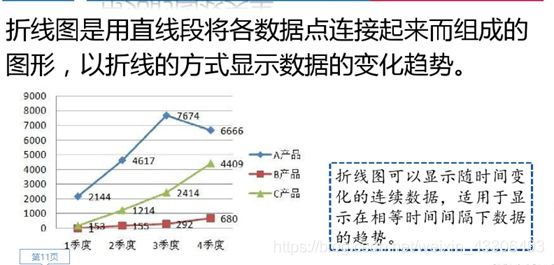






Matplotlib—绘图制表



用hist()函数绘制直方图
代码:

如图:



绘制散点图
代码:

如图:


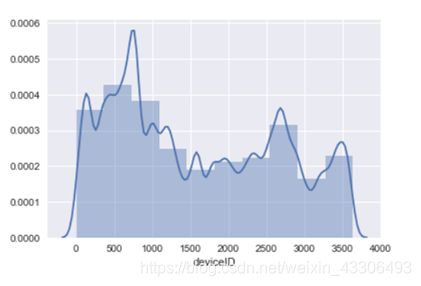
绘制带有核密度估计曲线的直方图
代码:

如图:

通过jointplot()函数创建多面板图形
代码:

如图:

绘制二维直方图
代码:

如图:


绘制核密度估计图形
代码:

如图:
出现的问题及总结:
问题一:数据读取–杭州地铁站1月1日三条线路所有站点的刷卡数据记录时出现问题,如图:
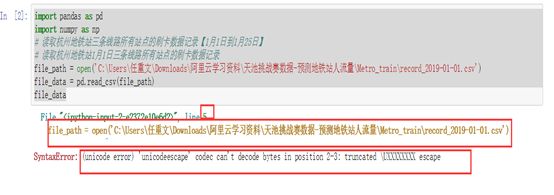
解决方案:csdn查找,发现是写文件路径的时候不规范,直接从电脑上打开文件的地方复制的地址占到程序里是错误的
正确的文件路径应该是这样的,举例:
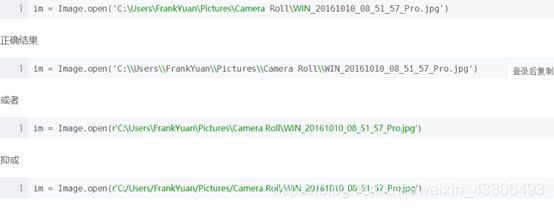
window 读取文件可以用\,但是在字符串中\是被当作转义字符来使用,所以’d:\a.txt’会被转义成’d:\a.txt’这是正确路径,所以不会报错。而‘C:\Users\FrankYuan\Pictures\Camera Roll\WIN_20161010_08_51_57_Pro.jpg ’中经过转义之后可能就找不到路径的资源了,例如\t可能就转义成tab键了。
#‘\xxx\xxx\xx’是错误的,应该是’/xxx/xxx/xxx’,改完之后成功执行,如图:

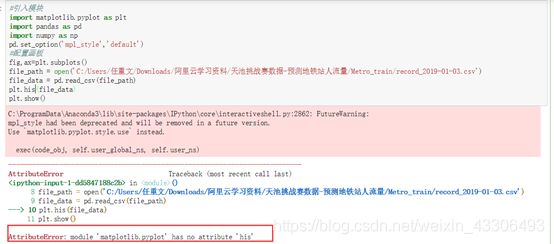
问题二:绘制箱型图查看数据中是否有异常值时出现错误,如图:

解决方案:网上查找,发现没有引用matplotlib.pyplot模块,相关语句也没有写对如再画图前还有配置画板这一步,正确操作后,成功出现结果,如图:

解决方案:

问题三:用hist()函数绘制直方图时出现错误,如图:
解决方案:检查代码,发现hist写成his了,重新运行,成功执行,如图:

