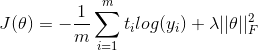Attention-Based Bidirectional Long Short-Term Memory for Relation Classification双向lstm实体关系分类
本文章主要内容为关系分类的重大挑战是一个短文本的重要信息的位置并不确定提出的attention双向lstm;attention在许多博客都有相关解释,这里不作说明,双向lstm是对单向lstm做的改进,要通过上下文信息对当前lstm神经元做影响;
在引言部分作者介绍了关系分类的重要性,例如信息提取以及智能问答,文章举了一个小例子,实体与目标之间的关系,它是有关于flower和chapel之间的关系 。
在引言最后开始说名大部分传统方法运用了许多手工特征/最近深度学习减少了手工特征,但是仍然运用了大量的高级特征例如句法分析或者实体识别等第三方方法;(借助第三方是否句有弊端,本热认为并不能作为唯一的好坏之分,)作者运用双向lstm加attention自动提取包含整个句子语义信息关键词汇或者字符,并且在实验中在SemEval-2010 Task 8 dataset 获得
文章第二章主要讲了相关工作有关于关系分类,第三章主要讲了模型,第4张模型评估,第5张总结。
对于第2章不在进行解析,因为差不多就是说别人的缺点,以及在此基础上的改进,直接进入主题。
第二章有关于关系分类的相关工作
要说明一下相关工作回顾整个发展,
(1)基于传统的大部分都是模式匹配方法或者利用额外的nlp语义特征,最典型的是rink用其他预料提取的特征来对svm训练分类.
(2)最近许多文献开始利用深度网络自动提取特征,最具有代表性的是zeng(2014)运用卷积网络进行分类,然而cnn不适合做长距离语义语义信息(对于这个说法,本人并不赞同,由于利用卷积核获取的特征虽然是局部特征,但是对于深层又会对特征进行组合,)
(3)相关工作是张运用双向rnn从原始文本中学习模式类别,尽管双向rnn已经获取上下文信息,由于梯度爆炸等原因(具体rnn为什么会有梯度爆炸https://blog.csdn.net/qq_29340857/article/details/70556307讲解的比较好),最后又说了zhang(2015)的利用nlp工具以及特征pos,切词,句法等高级特征,作者的方法就是利用四个位置坐标作为一个单词,转换所有单词作为向量,简单完整,(仍然不赞同,原因是一些句法名词性是认为设定,本身涵盖了模型,是人训练的模型,添加这些特征,会对模型有更好的效果,小孩之所以不知道词性,并不代表小孩不会对词进行分类,只不过他不知道每个词性叫什么).
第三章模型解析
模型主要分为五个部分:
1/ 输入层:input layer:输入一个句子;
2/编码层:embedding layer:把每一个单词映射到低维向量;
(为什么称为低维向量,自己理解对于词,数据非常大,如果用词袋模型,一个句子的向量长度是无法形容的,吗例如:“今天你吃饭了吗” 如果我们的词袋含有(今天 你 我 吃饭 ,...,) 那么一个单词就表示为例如今天标示为【1,0,0,0,0】,首先矩阵比较稀疏,第二不能够很好的表达词之间的位置关系,具体介绍请在网上查阅词向量概念,介绍的比较清除)
3/lstmlayer: 从句子向量(2)获取高层特征;
4/attention layer :主要是两个过程(1)产生一个权重向量,把每一步的单词级别向量合并成句子级别向量,;(2)把两者相乘;
5/output layer :最后输出的是能够进行分类的向量;
接下来进行解析整个模型每一部分:
3.1 单词编码
输入一般都是一个句子含有T个单词表示为 S={x1,x2,...,xT},其中没一个单词xi转化为一个向量ei,怎么做的的其实和普通的编码是一个过程;我们举例:
第一步首先对于一个句子S("张杰的看月亮爬起来")把他映射到一个矩阵,其中V表示整个模型的语料词汇的大小,对词汇进行编码词向量的大小,标示需要学习的参数,是用户需要设置的超参数,假设我们有的数据语料为(张杰,的,看,月亮,爬起来,吃饭),则矩阵表示为:
(张杰,的,看,月亮,爬起来,吃饭)
,
每一列表示一个词汇向量,那么把单词xi映射到ei的公式如下:
,其中表示one hot ,也就是哪个词出现了在输入文本中,对于句子“张杰的看月亮爬起来”的张杰对应的就是
,那么一个句子作为实际模型输入表示为{e1,e2,...,eT}.这也是lstm的常规embedding编码过程;
把训练数据集做成vocabulary,对于每一个词汇有对应的词向量,根据下标对应词向量。
3.2 双向network
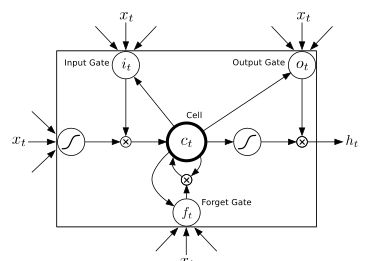
文章开始说了单向lstm没有考虑未来的信息对当前的影响,直接运用了 graves的lstm时用了双向lstm,在这里对lstm做简要回顾,整个前向过程比较清晰,反向就是梯度要根据前向输入,把梯度按照这个顺序返回过去;在文章或者csdn对lstm有许多介绍,在graves那篇文章SPEECH RECOGNITION WITH DEEP RECURRENT NEURAL NETWORKS的图片如下:
对应的公式如下:
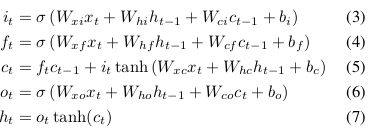
与本论文中的公式有所差别:本论文中公式如下:
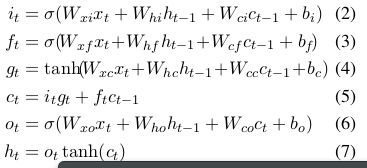
在本论中 中有的状态参与,所以说当前状态及包含了当前输入信息以及之前状态信息,但是这样做是否涵盖重复信息呢,(疑问来自和都有时刻的状态信息,这样增加应该是增强了之前的状态信息影响,在实际试验,本人用seq2seq进行问答系统实验,发现过拟合状态,后来词的生成几乎只依赖前一个词的生成,而与问句完全无关,这个说明运用一个state c状态来涵盖之前的所有信息并不完全可行,实验应该增加o或者h的输出来增加上下文相关信息)。
中有的状态参与,所以说当前状态及包含了当前输入信息以及之前状态信息,但是这样做是否涵盖重复信息呢,(疑问来自和都有时刻的状态信息,这样增加应该是增强了之前的状态信息影响,在实际试验,本人用seq2seq进行问答系统实验,发现过拟合状态,后来词的生成几乎只依赖前一个词的生成,而与问句完全无关,这个说明运用一个state c状态来涵盖之前的所有信息并不完全可行,实验应该增加o或者h的输出来增加上下文相关信息)。
在此需要把作者的模型结构图展示出来,对最终双向lstm的输出处理进行解释:
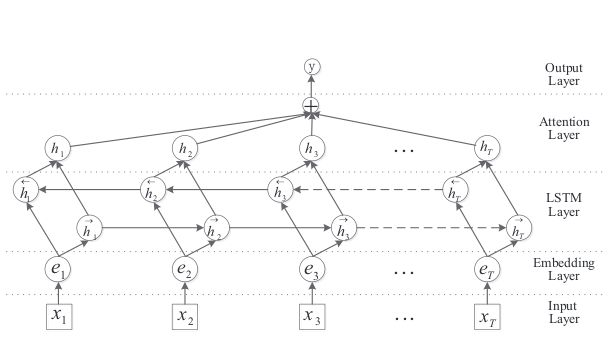
图 3.2
可以看到对于输入[x1,x2,...,xt}={"张杰 的 看 月亮 爬出来"} 每一个time step i输入的词汇得到的,在作者公式中如下:
就是把每一个单词的前馈输出与反馈输出逐个元素求和得到的向量作为最后的输出。
3.3 attention 注重层
通过双向lstm得到了每一个单词的输出h_{i},我们得到了输出向量,其中T为单词的个数,注意力就是对每一个单词的最后输出来得到哪个单词对关系分类重要程度,因此学习一个权重向量来得到最好的输出:
因此权重层的结构输出为:
M=tanh(H)(9)
![]() (10)
(10)
![]() (11)
(11)
这个过程论文并没有详细解释,为什么这样做,公式(9)把向量映射到-1到1的范围之内,经过公式10,得到权重之后的特征,至于再乘以原始输出特征,可能是为了增加特征的影响,最后把权重输出通过tanh映射:
![]() (12)
(12)
3.4分类
这里作者直接用softmax分类器求解预测条件概率:
![]() (13)
(13)
![]() 也就是求最大分类概率;对于损失函数也比较普通
也就是求最大分类概率;对于损失函数也比较普通
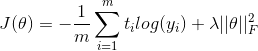 其中t代表实际的分类,后边的就是L2正则化.
其中t代表实际的分类,后边的就是L2正则化.
至此整个模型讲解完毕,整体运用的增加了attention对真个文本进行信息侧重表示文本信息的词汇,可以根据粒度来增加句法的关系,实验就不做介绍.因为本文的说明是为了对 github的代码进行详细分析原理铺垫,真个实体抽取,关系抽取在博客https://mp.csdn.net/postedit/79893868,这里介绍的只是整个系统的一部分.