Python分别实现基于Request库和Scrapy框架对东方财富股票的爬取
本文将讲述Request库和Scrapy框架实现网页的爬取
一、首先我们来认识一下Request库和Scrapy框架
Request库:Request库是Python公认的优秀的第三方网络爬虫库,能够实现自动爬取HTML页面,自动网络请求提交。
Scrapy框架:功能强大,爬取快速的爬虫框架
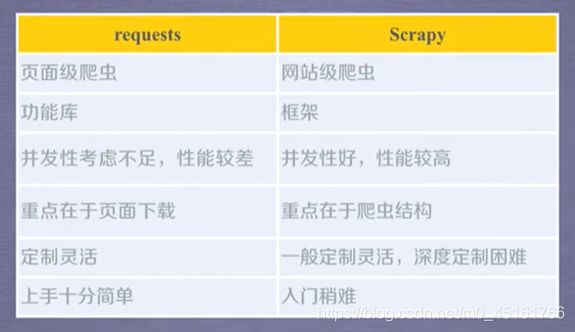
二、Request库和Scrapy框架的对比:Request VS Scrapy
2.1 相同点
- 两者都可以进行页面请求和爬取,Python爬虫的两个主要技术路线
- 两者可用性都好,文档丰富,入门简单
- 两者都没有处理js、提交表单、应对验证码等功能(可扩展)
2.2 不同点
三、开始写代码
3.1 Request库实现对东方财富股票信息的爬取
3.1.1 准备工作
首先安装好需要用到的Python第三方库
- 安装request库
pip install requests - 安装beautifulsoup库
pip install beautifulsoup4
3.1.2 代码实现
import re
import requests
import traceback
from bs4 import BeautifulSoup
# 获得URL对应的页面
def gethttptext(url,code='utf-8'):
try:
r=requests.get(url,timeout=30)
r.raise_for_status()
r.encoding=code
#print(r.status_code)
return r.text
except:
return ""
# 获得股票的信息列表
# list保存所以的股票信息
#获取股票参数的URL网站
def getstocklist(list,stockurl):
# 获得HTML页面
html=gethttptext(stockurl)
# 解析页面
soup=BeautifulSoup(html,'html.parser')
a=soup.find_all('tr')
# 用正则表达式找出股票信息
for i in a:
# 因为tr标签中不一定都符合正则表达式,所以用try来处理异常
try:
href=i.attrs['id']
list.append(re.findall(r'[tr]\d{6}',href)[0])
except:
continue
# 获得个股的股票信息
# fpath股票信息的保存的路径
def getstockinfo(list,stockurl,fpath):
count=0
for stock in list:
# 形成访问个股信息的URL
url=stockurl+stock[1:]+".html"
html=gethttptext(url)
try:
if html=='':
continue
infodict={
}
# 解析网页
soup=BeautifulSoup(html,'html.parser')
stockinfo=soup.find('div',attrs={
'class':'merchandiseDetail'})
# 获得股票名称的信息
name=stockinfo.find_all(attrs={
'class':'fundDetail-tit'})[0]
infodict.update({
'股票名称':name.text.split()[0]})
# 获得股票信息的值
keylist=stockinfo.find_all('dt')
valuelist=stockinfo.find_all('dd')
# 将获得的信息恢复为键值对,并存在列表中
for i in range(len(keylist)):
key=keylist[i].text
val=valuelist[i].text
infodict[key]=val
# 将所有信息保存在文件中
with open(fpath,'a',encoding='utf-8') as f:
f.write(str(infodict)+'\n')
count = count + 1
print('\r当前速度:{:.2f}%'.format(count*100/len(list)),end='')
except:
count = count + 1
print('\r当前速度:{:.2f}%'.format(count * 100 / len(list)), end='')
# 获取异常信息
traceback.print_exc()
continue
if __name__=="__main__":
# 获得股票列表的链接
stock_list_url="https://fund.eastmoney.com/fund.html#os_0;isall_0;ft_;pt_1"
# 获得取票信息链接的主题部分
stock_info_url="https://fund.eastmoney.com/"
# 保存的路径
output_fire='D://BaiduStockInfo.txt'
slist=[]
getstocklist(slist,stock_list_url)
getstockinfo(slist,stock_info_url,output_fire)
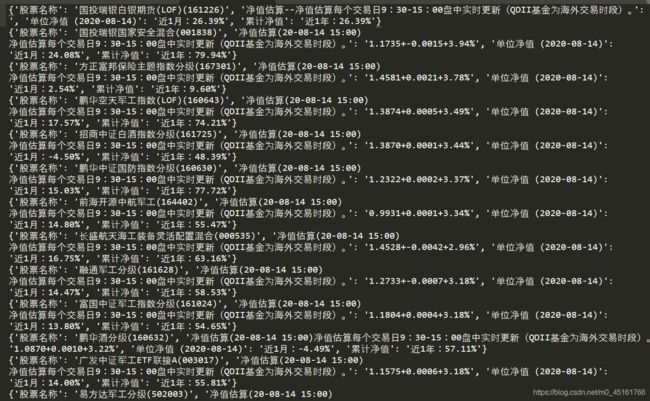
3.1.3 结果展示
3.2 Scrapy框架实现对东方财富股票信息的爬取
3.2.1 准备工作
1. 安装Scrapy库pip install sctapy
2. 创建一个工程
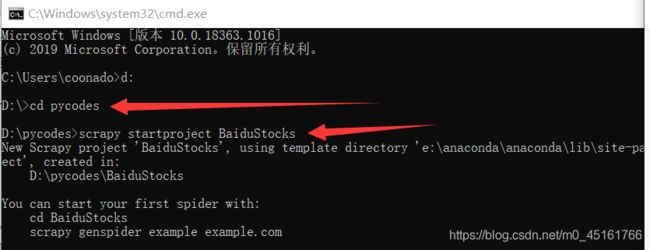
比如要在D盘的pycodes文件夹中存放一个名叫Python123demo的工程
(1) 打开cmd 进入pycodes文件夹
(2) 输入scrapy startproject 工程名
(3) 这是pycodes文件夹下就创建好了工程
(4) 对刚创建的工程文件Python123demo中的文件解释说明

3. 在工程中产生一个Scrapy爬虫
(1)再进入到刚创建的文件夹中
(2)输入scrapy genspider 爬虫名字 爬取的网址

注意:这条命令只是用来生成一个在spider文件下stocks.py的爬虫文件
(3)解释一下爬虫文件stocks.py中的内容
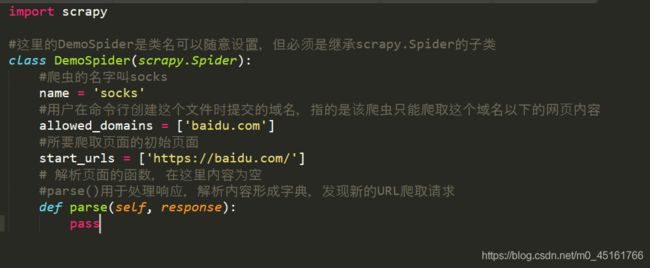
4. 配置产生的Spider爬虫
(1)将spider文件下的stocks.py配置为
import scrapy
import re
class StocksSpider(scrapy.Spider):
name = 'stocks'
start_urls = ['http://quote.eastmoney.com/stock_list.html']
def parse(self, response):
# 循环获取列表中a标签的链接信息
for href in response.css('a::attr(href)').extract():
try:
# 通过正则表达式获取链接中想要的信息
stock = re.findall(r"[s][hz]\d{6}", href)[0]
# 生成百度股票对应的链接信息
url = 'http://gu.qq.com/' + stock + '/gp'
# yield是生成器
#将新的URL重新提交到scrapy框架
# callback给出了处理这个响应的处理函数为parse_stock
yield scrapy.Request(url, callback=self.parse_stock)
except:
continue
# 定义如何存百度的单个页面中提取信息的方法
def parse_stock(self, response):
# 因为每个页面返回 的是一个字典类型,所以定义一个空字典
infoDict = {
}
stockName = response.css('.title_bg')
stockInfo = response.css('.col-2.fr')
name = stockName.css('.col-1-1').extract()[0]
code = stockName.css('.col-1-2').extract()[0]
info = stockInfo.css('li').extract()
# 将提取的信息保存到字典中
for i in info[:13]:
key = re.findall('>.*?<', i)[1][1:-1]
key = key.replace('\u2003', '')
key = key.replace('\xa0', '')
try:
val = re.findall('>.*?<', i)[3][1:-1]
except:
val = '--'
infoDict[key] = val
# 对股票的名称进行更新
infoDict.update({
'股票名称': re.findall('\>.*\<', name)[0][1:-1] + \
re.findall('\>.*\<', code)[0][1:-1]})
yield infoDict
(2)将D:\pycodes\BaiduStocks\BaiduStocks目录下的pipelines.py配置为
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
# from itemadapter import ItemAdapter
class BaidustocksInfoPipeline(object):
def process_item(self, item, spider):
return item
class BaidustocksInfoPipeline(object):
# 当爬虫被调用时
def open_spider(self, spider):
self.f = open('gupiao.txt', 'w')
# 当爬虫关闭时
def close_spider(self, spider):
self.f.close()
# 对每一个item处理时
def process_item(self, item, spider):
try:
line = str(dict(item)) + '\n'
self.f.write(line)
except:
pass
return item
(3)将D:\pycodes\BaiduStocks\BaiduStocks目录下的settings.py
添加一行
ITEM_PIPELINES = {
'BaiduStocks.pipelines.BaidustocksInfoPipeline': 300,
}
或者找到ITEM_PIPELINES = {}取消注释进行修改
其中settings.py文件中要修改的字段
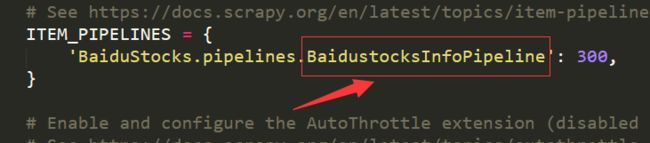
取决于pipelines.py文件中的类名
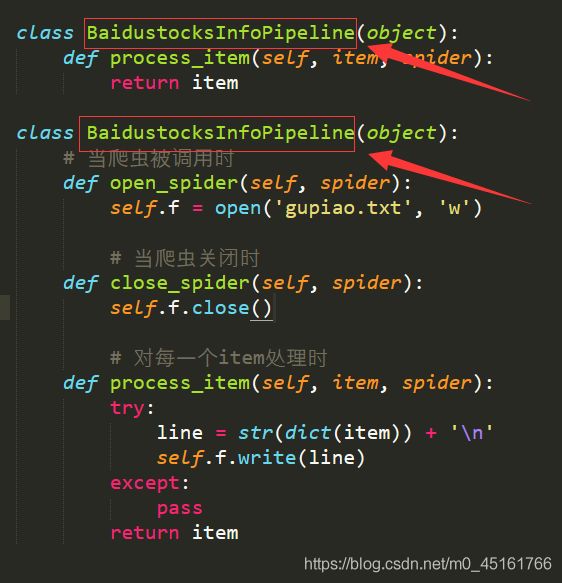
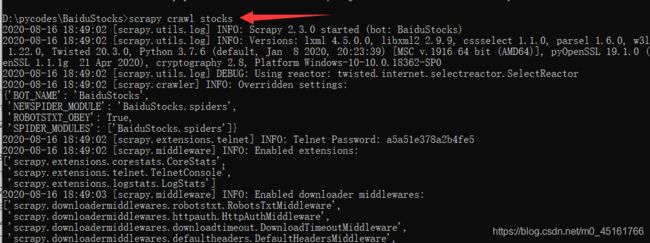
5. 运行爬虫,获取网页信息
cmd中输入scrapy crawl 爬虫名
6. 结果展示
