Caffe中卷积层的实现
作者:xg123321123
出处:http://blog.csdn.net/xg123321123/article/details/53319080
声明:版权所有,转载请联系作者并注明出处
1 简述
- 使用im2col分别将featrue maps和filter转换成矩阵;
- 调用GEMM(GEneralized Matrix Multiplication)对两矩阵内积,这样一来卷积操作就被转化为了矩阵乘法运算。
- 原理图如下

将尺寸为K×K的卷积核在某个位置对应的feature map区域表示为K×K的一维向量;
将feature map各个通道对应的向量之间,串联起来;
那么尺寸K×K的卷积核在某个位置对应的各个通道的feature map,组合起来就是长度为C×K×K的一维向量。

当卷积核对应到新的位置上,又得到新的一维向量。
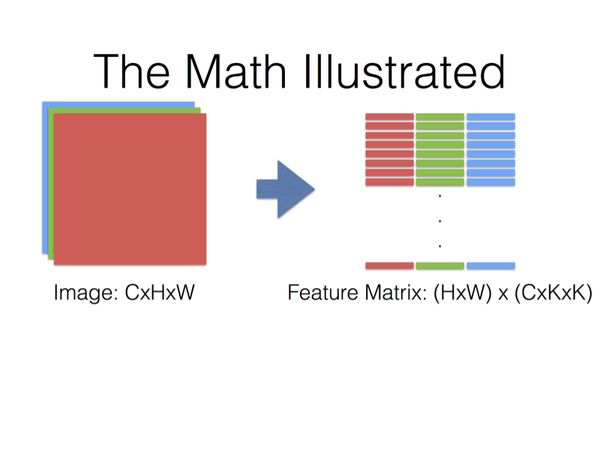
那么卷积核对应整张图片的所有位置,就得到一个(H×W)×(C×K×K)的矩阵(假设卷积核每次移动的步数为1)。

同样地,将卷积核也表示为一维向量;
用于输出一个特征图的卷积核对应一个C×K×K的一维向量(因为用于输出同一个特征图的卷积核是共享权值的,所以在整张图的各个位置进行卷积的都是同一个卷积核);
假设要输出 Cout 个特征图,就需要 Cout 个卷积核,那么所有卷积核对应一个 Cout ×C×K×K的矩阵。
最后,特征图对应矩阵乘以卷积核对应矩阵的转置,得到输出矩阵 Cout ×(H×W),这就是输出的三维Blob( Cout ×H×W)。
2 例图
用下图举个例子,请对号入座。

3 灵感来源
之所以要将卷积运算用im2col操作实现,是因为优化CNN中的卷积不是一件简单的事。
由于时间、成本上的种种原因,caffe作者作用了这样一种lazy but temporary的方案。
这种方案取得的效果还是比较好的。
详情见caffe作者吐槽Caffe卷积算法的链接:Convolution in Caffe: a memo · Yangqing/caffe Wiki · GitHub
4 代码实现
ConvolutionLayer 是 BaseConvolutionLayer的子类,BaseConvolutionLayer 是 Layer 的子类。
ConvolutionLayer 除了继承了相应的成员变量和函数以外,自己的成员函数主要有:compute_output_shape,Forward_cpu 和 Backward_cpu。
compute_output_shape
template <typename Dtype>
void ConvolutionLayer::compute_output_shape() {
this->height_out_ = (this->height_ + 2 * this->pad_h_ - this->kernel_h_)
/ this->stride_h_ + 1; //输出feature map 的 height
this->width_out_ = (this->width_ + 2 * this->pad_w_ - this->kernel_w_)
/ this->stride_w_ + 1; //输出 feature map 的 width
} Forward_cpu
template <typename Dtype>
void ConvolutionLayer::Forward_cpu(const vector forward_cpu_gemm
template <typename Dtype>
void BaseConvolutionLayer::forward_cpu_gemm(const Dtype* input,
const Dtype* weights, Dtype* output, bool skip_im2col) {
const Dtype* col_buff = input;
if (!is_1x1_) {
if (!skip_im2col) {
// 如果没有1x1卷积,也没有skip_im2col
// 则使用conv_im2col_cpu对使用卷积核滑动过程中的每一个kernel大小的图像块
// 变成一个列向量,其中height=kernel_dim_
// width = 卷积后图像heght*卷积后图像width
conv_im2col_cpu(input, col_buffer_.mutable_cpu_data());
}
col_buff = col_buffer_.cpu_data();
}
// 使用caffe的cpu_gemm来进行计算
for (int g = 0; g < group_; ++g) {
// 分组分别进行计算
// conv_out_channels_ / group_是每个卷积组的输出的channel
// kernel_dim_ = input channels per-group x kernel height x kernel width
// 计算的是output[output_offset_ * g] =
// weights[weight_offset_ * g] X col_buff[col_offset_ * g]
// weights的形状是 [conv_out_channel x kernel_dim_]
// col_buff的形状是[kernel_dim_ x (卷积后图像高度乘以卷积后图像宽度)]
// 所以output的形状自然就是conv_out_channel X (卷积后图像高度乘以卷积后图像宽度)
caffe_cpu_gemm(CblasNoTrans, CblasNoTrans, conv_out_channels_ / group_, conv_out_spatial_dim_, kernel_dim_,
(Dtype)1., weights + weight_offset_ * g, col_buff + col_offset_ * g,
(Dtype)0., output + output_offset_ * g);
}
} forward_cpu_bias
template type>
void BaseConvolutionLayertype>::forward_cpu_bias(Dtype* output,
const Dtype* bias) {
// output = bias * bias_multiplier_
// num_output 与 conv_out_channel是一样的
// num_output_ X out_spatial_dim_ = num_output_ X 1 1 X out_spatial_dim_
caffe_cpu_gemmtype>(CblasNoTrans, CblasNoTrans, num_output_,
out_spatial_dim_, 1, (Dtype)1., bias, bias_multiplier_.cpu_data(),
(Dtype)1., output);
} Backward_cpu
template <typename Dtype>
void ConvolutionLayer::Backward_cpu(const vector 本篇博客主要参考自
《 (Caffe)卷积的实现 》
《在 Caffe 中如何计算卷积?》
《Caffe源码(五):conv_layer 分析 》