ORACLE事务和实例恢复过程梳理
1.首先会经过在share pool中的sql语句的解析过程,这一过程只要是针对sql语法,执行计划这些进行处理,这一部分不细讲。
2.接着,到了sql执行后,数据库从物理文件读出数据行相应的数据库到 buffer cache中(假设此时内存不存在相应的数据块同时不讨论锁的过程),这一过程也涉及到数据块写到dirty list,并写脏块,为新读取的数据块寻找空闲空间的过程 。
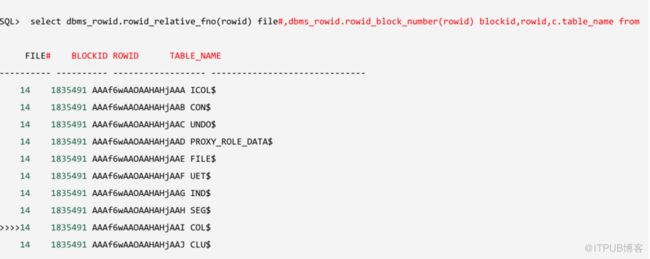
以下通过DUMP UNDO 相关 信息来查看。



看到index是0x09的事务槽的 state 为 10代表事务正在活动,而其他槽是 9代表事务不活动,
scn 表示务事启动、提交、回滚的SCN,事务槽 0x09的scn是 0x0009.01e25a30,转换之后是38686317104。
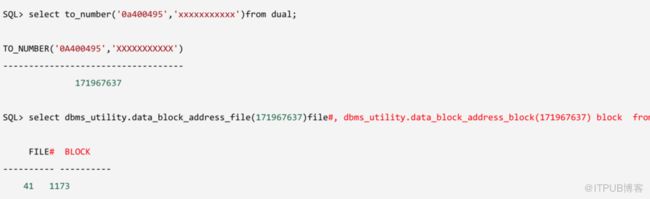
事物表中0x19槽的dba为0x0a400495即41号文件的1173号块块号这与(与v$transaction视图中一致)。
我们在看一下这个前镜像到底是什么?
转储数据块

接着往下看,有本UNDO块中有51条记录:

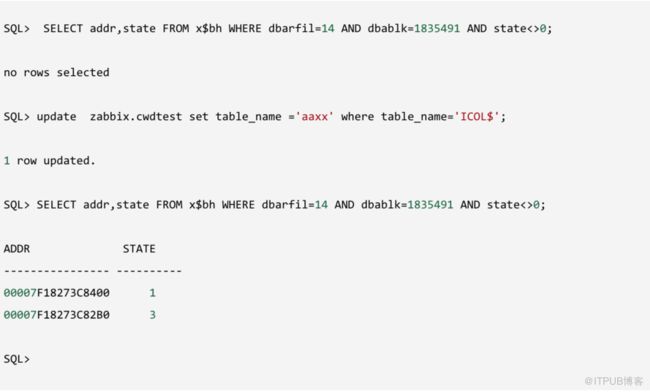
我们找到第51行记录的对象号是130736,这个正是我们本次事务更改的表。

这里字段值是 49 43 4f 4c 24,通过转换是ICOL$,这正是update前的值。
SQL> select utl_raw.cast_to_varchar2(replace('49 43 4f 4c 24',' ')) from dual;
UTL_RAW.CAST_TO_VARCHAR2(REPLACE('49434F4C24',''))
-------------------------------------------------------------------------------------
ICOL$
tab 0, row 0, @0x1e87
tl: 249 fb: --H-FL-- lb: 0x0 cc: 55
col 0: [ 3] 53 59 53
col 1: [ 5] 49 43 4f 4c 24<<<<<< 转换成字符后是'ICOL$'
Block dump from disk:
buffer tsn: 7 rdba: 0x039c01e3 (14/1835491)
scn: 0x0009.01e25a2b seq: 0x02 flg: 0x04 tail: 0x5a2b0602
frmt: 0x02 chkval: 0xf28b type: 0x06=trans data
Hex dump of block: st=0, typ_found=1
tl: 248 fb: --H-FL-- lb: 0x2 cc: 55
col 0: [ 3] 53 59 53
col 1: [ 4] 61 61 78 78<<<<<<<<< 转换成字符后是'aaxx'
Block dump from disk:
buffer tsn: 7 rdba: 0x039c01e3 (14/1835491)
scn: 0x0009.01e25beb seq: 0x01 flg: 0x04 tail: 0x5beb0601
frmt: 0x02 chkval: 0xad91 type: 0x06=trans data
Hex dump of block: st=0, typ_found=1
REDO RECORD - Thread:1 RBA: 0x000412.00335b66.0010 LEN: 0x01a0 VLD: 0x0d
SCN: 0x0009.01e25beb SUBSCN: 1 07/22/2019 17:53:43
(LWN RBA: 0x000412.00335b66.0010 LEN: 0001 NST: 0001 SCN: 0x0009.01e25beb)
CHANGE #1 TYP:0 CLS:1 AFN:14 DBA:0x039c01e3 OBJ:130736 SCN:0x0009.01e25a2b SEQ:2 OP:11.5 ENC:0 RBL:0
KTB Redo
op: 0x01 ver: 0x01
compat bit: 4 (post-11) padding: 1
op: F xid: 0x000b.009.0001ba87 uba: 0x0a400495.639a.51
KDO Op code: URP row dependencies Disabled
xtype: XA flags: 0x00000000 bdba: 0x039c01e3 hdba: 0x039c01e2
itli: 2 ispac: 0 maxfr: 4858
tabn: 0 slot: 0(0x0) flag: 0x2c lock: 2 ckix: 0
ncol: 55 nnew: 1 size: -1
col 1: [ 4] 61 61 78 78
CHANGE #2 TYP:0 CLS:37 AFN:3 DBA:0x00c00170 OBJ:4294967295 SCN:0x0009.01e25bb3 SEQ:1 OP:5.2 ENC:0 RBL:0
ktudh redo: slt: 0x0009 sqn: 0x0001ba87 flg: 0x0012 siz: 140 fbi: 0
uba: 0x0a400495.639a.51 pxid: 0x0000.000.00000000
CHANGE #3 TYP:0 CLS:38 AFN:41 DBA:0x0a400495 OBJ:4294967295 SCN:0x0009.01e25bb2 SEQ:1 OP:5.1 ENC:0 RBL:0
ktudb redo: siz: 140 spc: 646 flg: 0x0012 seq: 0x639a rec: 0x51
xid: 0x000b.009.0001ba87
ktubl redo: slt: 9 rci: 0 opc: 11.1 [objn: 130736 objd: 130736 tsn: 7]
Undo type: Regular undo Begin trans Last buffer split: No
Temp Object: No
Tablespace Undo: No
0x00000000 prev ctl uba: 0x0a400495.639a.50
prev ctl max cmt scn: 0x0009.01e25b73 prev tx cmt scn: 0x0009.01e25b75
txn start scn: 0x0000.00000000 logon user: 0 prev brb: 171967629 prev bcl: 0 BuExt idx: 0 flg2: 0
KDO undo record:
KTB Redo
op: 0x03 ver: 0x01
compat bit: 4 (post-11) padding: 1
op: Z
KDO Op code: URP row dependencies Disabled
xtype: XA flags: 0x00000000 bdba: 0x039c01e3 hdba: 0x039c01e2
itli: 2 ispac: 0 maxfr: 4858
tabn: 0 slot: 0(0x0) flag: 0x2c lock: 0 ckix: 0
ncol: 55 nnew: 1 size: 1
col 1: [ 5] 49 43 4f 4c 24 《〈〈更改前镜像数据
什么时候发生normal checkpoint
下面这些操作将会触发checkpoint事件:
· 日志切换,通过ALTER SYSTEM SWITCH LOGFILE。
· DBA 发出checkpoint命令,通过ALTER SYSTEM checkpoint。
· 对数据文件进行热备时,针对该数据文件的checkpoint也会进行,ALTER TABLESPACE TS_NAME BEGIN BACKUP/END BACKUP。
· 当运行ALTER TABLESPACE/DATAFILE READ ONLY的时候。
· SHUTDOWN 命令发出时。
因为每次完全的checkpoint都需要把buffer cache所有的脏块都写入到数据文件中,这样就是产生一个很大的IO消耗,频繁的完全checkpoint操作很对系统的性能有很大的影响,为此Oracle引入的增量checkpoint的概念,buffer cache中的脏块将会按照BCQ队列的顺序持续不断的被写入到磁盘当中,同时CKPT进程将会每3秒中检查DBWn的写入进度并将相应的RBA信息记录到控制文件中。
有了增量checkpoint之后在进行实例恢复的时候就不需要再从崩溃前的那个完全checkpoint开始应用重做日志了,只需要从控制文件中记录的RBA开始进行恢复操作,这样能节省恢复的时间。
发生增量checkpoint的先决条件
· 恢复需求设定 (FAST_START_IO_TARGET/FAST_START_MTTR_TARGET)
· LOG_checkpoint_INTERVAL 参数值
· LOG_checkpoint_TIMEOUT 参数值
· 最小的日志文件大小
· buffer cache 中的脏块的数量
启动数据库时,如果发现STOP SCN = NULL,表示需要进行crash recovery。
oracle 的实例恢复过程
DATABASE ENTRY
***************************************************************************
。。。。
Controlfile Creation Timestamp 08/21/2017 11:01:49
Incmplt recovery scn: 0x0000.00000000
Resetlogs scn: 0x0000.000e2006 Resetlogs Timestamp 08/21/2017 11:01:51
Prior resetlogs scn: 0x0000.00000001 Prior resetlogs Timestamp 08/24/2013 11:37:30
Redo Version: compatible=0xb200400
#Data files = 53, #Online files = 53
Database checkpoint: Thread=1 scn: 0x0009.01e35ecd
Threads: #Enabled=1, #Open=1, Head=1, Tail=1
CHECKPOINT PROGRESS RECORDS
***************************************************************************
(size = 8180, compat size = 8180, section max = 11, section in-use = 0,
last-recid= 0, old-recno = 0, last-recno = 0)
(extent = 1, blkno = 2, numrecs = 11)
THREAD #1 - status:0x2 flags:0x0 dirty:15
low cache rba:(0x413.18481.0)〉〉〉起点 on disk rba:(0x413.1849b.0)〉〉〉终点
on disk scn: 0x0009.01e374ef 07/24/2019 10:23:54
resetlogs scn: 0x0000.000e2006 08/21/2017 11:01:51
heartbeat: 996528373 mount id: 1186014334
low cache rba 以前的更新的脏块已经写入数据文件,不需要重做, on disk rba以后的日志还没写入到online logfile.所以不需要恢复.
DATA FILE #14:
name #18: /opt/app/oracle/oradata/xxxx/xxx
creation size=2097152 block size=8192 status=0xe head=18 tail=18 dup=1
tablespace 7, index=7 krfil=14 prev_file=13
unrecoverable scn: 0x0000.00000000 01/01/1988 00:00:00
Checkpoint cnt:1061 scn: 0x0009.01e35ecd 07/24/2019 07:30:51
Stop scn: 0xffff.ffffffff 09/27/2018 09:20:13
Creation Checkpointed at scn: 0x0000.000f4212 08/21/2017 12:03:57
thread:1 rba:(0x8.3f45.10)
oradebug dump file_hdrs 1
DATA FILE #14:
name #18: /opt/app/oracle/oradata/xxxx/xxx
creation size=2097152 block size=8192 status=0xe head=18 tail=18 dup=1
tablespace 7, index=7 krfil=14 prev_file=13
unrecoverable scn: 0x0000.00000000 01/01/1988 00:00:00
Checkpoint cnt:1061 scn: 0x0009.01e35ecd 07/24/2019 07:30:51
alter database open
Beginning crash recovery of 1 threads
parallel recovery started with 32 processes
Started redo scan
Completed redo scan
read 16 KB redo, 14 data blocks need recovery
Started redo application at
Thread 1: logseq 1043, block 185196
Recovery of Online Redo Log: Thread 1 Group 2 Seq 1043 Reading mem 0
Mem# 0: /opt/app/oracle/oradata/tlvdb/redo2.log
Completed redo application of 0.01MB
Completed crash recovery at
Thread 1: logseq 1043, block 185228, scn 38686432573《〈〈〈〈〈〈〈〈
14 data blocks read, 14 data blocks written, 16 redo k-bytes read
Wed Jul 24 23:44:50 2019
Thread 1 advanced to log sequence 1044 (thread open)
Thread 1 opened at log sequence 1044
Current log# 3 seq# 1044 mem# 0: /opt/app/oracle/oradata/tlvdb/redo3.log
Successful open of redo thread 1
MTTR advisory is disabled because FAST_START_MTTR_TARGET is not set
Wed Jul 24 23:44:50 2019
SMON: enabling cache recovery
[39962] Successfully onlined Undo Tablespace 2.
Undo initialization finished serial:0 start:193329648 end:193329738 diff:90 (0 seconds)
Verifying file header compatibility for 11g tablespace encryption..
Verifying 11g file header compatibility for tablespace encryption completed
SMON: enabling tx recovery
Database Characterset is ZHS16GBK
SQL> ALTER SYSTEM DUMP LOGFILE '/opt/app/oracle/oradata/tlvdb/redo1.log' SCN MIN 38686383821 SCN MAX 38686389487;
System altered.
Opcodes *.*
RBAs: 0x000000.00000000.0000 thru 0xffffffff.ffffffff.ffff
SCNs: scn: 0x0009.01e35ecd (38686383821) thru scn: 0x0009.01e374ef (38686389487)
Times: creation thru eternity
FILE HEADER:
。。。。
Control Seq=459718=0x703c6, File size=4194304=0x400000
File Number=1, Blksiz=512, File Type=2 LOG
descrip:"Thread 0001, Seq# 0000001042, SCN 0x000901d8f38d-0x000901e35ecd"
thread: 1 nab: 0x384d91 seq: 0x00000412 hws: 0x3 eot: 0 dis: 0
resetlogs count: 0x38c7849f scn: 0x0000.000e2006 (925702)
prev resetlogs count: 0x3121c97a scn: 0x0000.00000001 (1)
Low scn: 0x0009.01d8f38d (38685701005) 07/08/2019 09:24:12
Next scn: 0x0009.01e35ecd (38686383821) 07/24/2019 07:30:51
Enabled scn: 0x0000.000e2006 (925702) 08/21/2017 11:01:51
Thread closed scn: 0x0009.01d8f38d (38685701005) 07/08/2019 09:24:12
Disk cksum: 0x56ca Calc cksum: 0x56ca
Terminal recovery stop scn: 0x0000.00000000
Terminal recovery 01/01/1988 00:00:00
Most recent redo scn: 0x0000.00000000
Largest LWN: 2395 blocks
3.数据文件中包含已提交或未提交的数据,尽管存在未提交的数据,此时数据库已经被打开,允许用户连接,此时针对 未提交的事务被进行回滚
前滚一旦完毕,SMON进程立即打开数据库。但是,这时的数据库中还含有那些中间状态的、既没有提交又没有回滚的脏块,这种脏块是不能存在于数据库中的,因为它们并没有被提交,必须被回滚。打开数据库以后,SMON进程会在后台进行回滚,此时会从Undo空间中寻找到旧版本SCN的数据块信息,来进行SGA中Buffer Cache数据块恢复。

来自 “ ITPUB博客 ” ,链接:http://blog.itpub.net/29863023/viewspace-2652139/,如需转载,请注明出处,否则将追究法律责任。
转载于:http://blog.itpub.net/29863023/viewspace-2652139/