Spark Streaming 快速入门(理论)
教程目录
- 0x00 教程内容
- 0x01 Spark Streaming 相关概念
-
-
-
-
- 1. Spark Streaming 介绍
- 2. DStream 介绍
-
-
-
- 0x02 Spark Streaming 编程基础
-
-
-
-
- 1. StreamingContext 的初始化
- 2. 输入源
- 3. 转化操作
- 4. 输出操作
-
-
-
- 0xFF 总结
0x00 教程内容
- Spark Streaming 相关概念
- Spark Streaming 编程基础
0x01 Spark Streaming 相关概念
1. Spark Streaming 介绍
Spark Streaming 是在 Spark 上建立的可扩展的、高吞吐量的、实时处理流数据的框架,数据可以来自于多种不同的源,例如 Kafka、Flume、HDFS/S3、Twitter、ZeroMQ 或者 TCP Socket 等。在这个 Spark Streaming 中,支持对流数据的各种运算,比如 map、reduce、join 等,处理完的数据可以存储到文件系统或者各种数据库。
Spark Streaming 的架构定位可以由下图表示:

左边是流数据源,右边是处理后输出数据的存储目标。在其内部,它的工作方式如下图所示: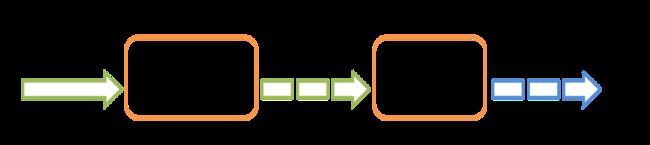
Spark Streaming 接收实时输入的数据流,采用的方法是对流数据进行时间切片,分成小的数据片段,最后通过类似于批处理的方式去处理数据的片段。
2. DStream 介绍
DStream(离散化流) 是 Spark Streaming 提供的基本抽象,与 RDD 是 Spark 的基本抽象类似。它代表一个特定时间段内的数据形成的流,可以理解为就是一种数据流。它可以是从数据源中接收的输入数据流,也可以是通过转化输入流生成的已处理数据流。可以简单地理解为, DStream 是由一系列连续的 RDD 所组成的,每个 RDD 都是特定时刻的数据。比如下图:
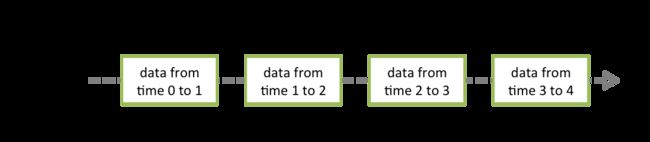
一共有四个时间段(time0-1,time1-2,time2-3,time3-4),这些时间段内,可以产生很多个 RDD ,每个时间段内的 RDD 组成 DStream 。
其实,关于 DStream 上的任何操作都会转换 RDD 操作的。
对 DStream 运用 flatMap 操作其实是作用于每一个 RDD 操作。如下图所示:
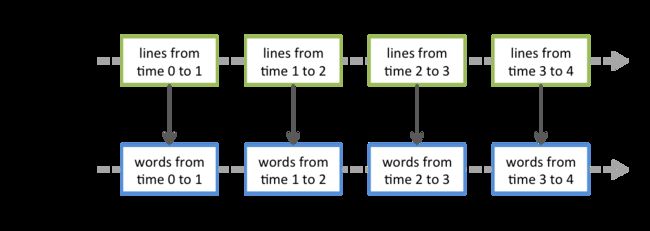
DStream 相当于对 RDD 的再次封装 ,它提供了转化操作和输出操作两种操作方法。
0x02 Spark Streaming 编程基础
1. StreamingContext 的初始化
a. 创建 StreamingContext 对象
可以根据 SparkConf 对象创建 StreamingContext 对象:
import org.apache.spark._
import org.apache.spark.streaming._
val conf = new SparkConf().setAppName(appName).setMaster(master)
// 时间间隔设置为1秒
val ssc = new StreamingContext(conf, Seconds(1))
StreamingContext 内部会创建 SparkContext,通过如下方式获得:
ssc.sparkContext
StreamingContext 的主要用法如下:
- 创建
DStreams定义数据源 - 使用
DStreams的转化和输出操作 - 接收数据:
StreamingContext.start() - 等待处理结果:
StreamingContext.awaitTermination() - 停止程序:
StreamingContext.stop()
2. 输入源
每个Input DStreams(数据源) ,除了file stream,都会关联一个 Receiver(接收器)对象,接收器对象就可以接收数据源中的数据并存储到内存中。
Spark Streaming 提供了两种类型的内置数据源:
a. 基础数据源:可以直接使用 StreamingContext 的 API,比如文件系统、socket 连接、Akka等等;对于简单的文件,可以使用 streamingContext 的 textFileStream 方法处理。
b. 高级数据源:结合 Flume、Kafka、Kinesis、Twitter 等的工具类,作为数据源;注意使用这些数据源的时候,需要引用对应的依赖。
3. 转化操作
DStream 的转化操作分为无状态和有状态两种。无状态转化操作:每个批次的数据不依赖于之前批次的数据;有状态转化操作:需要使用之前批次的数据或者中间结果来计算当前批次的数据。
- 无状态转化操作
DStream 的转化操作与 RDD 的转换操作类似,下面就以列表的方式简单说明:
| 转化操作 | 含义 |
|---|---|
| map(func) | 根据 func 函数生成一个新的 DStream |
| flatMap(func) | 跟 map 方法类似,但是每一项可以返回多个值。func 函数的返回值是一个集合 |
| union(otherStream) | 取 2 个 DStream 的并集,得到一个新的 DStream |
| count() | 计算 DStream 中所有 RDD 的个数 |
| reduce(func) | 计算 DStream 中的所有 RDD 通过 func 函数聚合得到的结果 |
| countByValue() | 如果 DStream 的类型为 K,那么返回一个新的 DStream,这个新的 DStream 中的元素类型是(K, Long),K 是原先 DStream 的值,Long 表示这个 Key 有多少次 |
| reduceByKey(func, [numTasks]) | 对于是键值对(K,V)的 DStream,返回一个新的 DStream 以 K 为键,各个 value 使用 func 函数操作得到的聚合结果为 value |
| join(otherStream, [numTasks]) | 基于(K, V)键值对的 DStream,如果对(K, W)的键值对 DStream 使用 join 操作,可以产生(K, (V, W))键值对的 DStream |
| cogroup(otherStream, [numTasks]) | 跟 join 方法类似,不过是基于(K, V)的 DStream,cogroup 基于(K, W)的 DStream,产生(K, (Seq[V], Seq[W]))的 DStream |
| transform(func) | 基于 DStream 中的每个 RDD 调用 func 函数,func 函数的参数是个 RDD,返回值也是个 RDD |
| updateStateByKey(func) | 对于每个 key 都会调用 func 函数处理先前的状态和所有新的状态 |
- 有状态转化操作
有状态转化操作包括Window 操作(基于窗口的转化操作) 和UpdateStateByKey 操作(追踪状态变化的转化操作)。
a. Window 操作(窗口操作)
Window 操作可以把几个批次的 DStream 合并成一个 DStream:
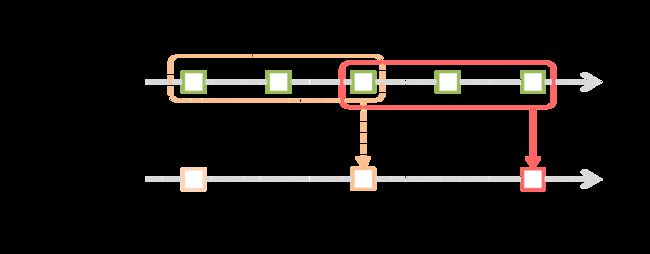
每个 window 操作都需要 2 个参数:
- 参数1(window length):每个窗口对应的时间批次数,如上图中time1、2、3为一个 window,time3、4、5也是一个 window。
- 参数2(sliding interval):每个窗口之间的间隔时间,可以看出上图下方的 window1、window3、window5 是间隔的,所以上图的这个值为 2。
b. UpdateStateByKey 操作
使用 UpdateStateByKey 方法需要做以下两步:
- 定义状态:状态可以是
任意的数据类型 - 定义状态更新函数:这个函数需要根据输入流把
先前的状态和所有新的状态
无论有没有新的数据进来,在每个批次中,Spark 都会对所有存在的 key 调用 func 函数,如果 func 函数返回 None,那么 key-value 键值对不会被处理。
举个例子,我们需要统计在一个文本输入流里每个单词的个数是多少:
def updateFunction(newValues: Seq[Int], runningCount: Option[Int]): Option[Int] = {
val newCount = ... // add the new values with the previous running count to get the new count
Some(newCount)
}
runningCount 是一个状态并且是 Int 类型的,所以这个状态的类型是 Int,runningCount 是先前的状态,newValues 是所有新的状态,是一个集合。
updateStateByKey 方法可以直接调用此函数,如:
val runningCounts = pairs.updateStateByKey[Int](updateFunction _)
4. 输出操作
最终的 DStream 数据一般会输出到数据库、文件系统等外部系统中,一些有多种方式供大家参考:
| 输出操作 | 含义 |
|---|---|
| print() | 打印出 DStream 中每个批次的前 10 条数据 |
| saveAsTextFiles(prefix, [suffix]) | 把 DStream 中的数据保存到文本文件里。每次批次的文件名根据参数 prefix 和 suffix 生成:”prefix-TIME_IN_MS[.suffix]” |
| saveAsObjectFiles(prefix, [suffix]) | 把 DStream 中的数据按照 Java 序列化的方式保存 Sequence 文件里,文件名规则跟 saveAsTextFiles 方法一样 |
| saveAsHadoopFiles(prefix, [suffix]) | 把 DStream 中的数据保存到 Hadoop 文件里,文件名规则跟 saveAsTextFiles 方法一样 |
| foreachRDD(func) | 遍历 DStream 中的每段 RDD,遍历的过程中可以将 RDD 中的数据保存到外部系统中 |
将数据写到外部系统通常都需要一个 connection 对象,一种很好的方式就是使用 ConnectionPool,ConnectionPool 可以在多个批次和 RDD 中对 connection 对象进行重用。示例代码如下:
dstream.foreachRDD {
rdd =>
rdd.foreachPartition {
partitionOfRecords =>
// ConnectionPool is a static, lazily initialized pool of connections
val connection = ConnectionPool.getConnection()
partitionOfRecords.foreach(record => connection.send(record))
ConnectionPool.returnConnection(connection) // return to the pool for future reuse
}
}
需要注意:
- DStream由输出操作延迟执行,就像RDD由RDD操作延迟执行一样。具体来说,DStream输出操作内部的RDD动作会强制处理接收到的数据。因此,如果您的应用程序没有任何输出操作,或者dstream.foreachRDD()内部没有任何RDD操作,就没有输出操作。系统将仅接收数据并将其丢弃。
- 默认情况下,输出操作一次执行一次。它们按照在应用程序中定义的顺序执行。
参考官网:Output Operations on DStreams
0xFF 总结
- 本篇教程为 Spark Streaming 的基础教程,后期还有实操教程,请留意本博客!
- 官网写得非常好,请多查阅官网进行学习!
作者简介:邵奈一
全栈工程师、市场洞察者、专栏编辑
| 公众号 | 微信 | 微博 | CSDN | 简书 |
福利:
邵奈一的技术博客导航
邵奈一原创不易,如转载请标明出处,教育是一生的事业。